Downloaded 22 times



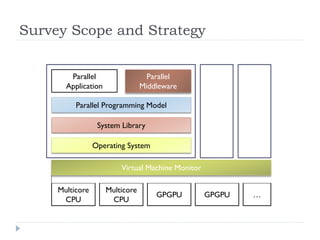


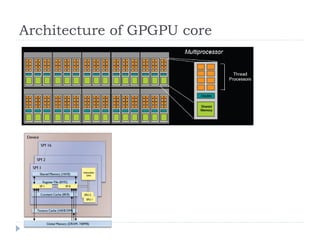

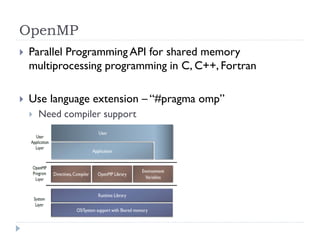

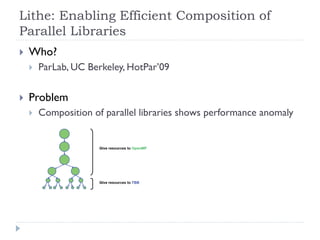
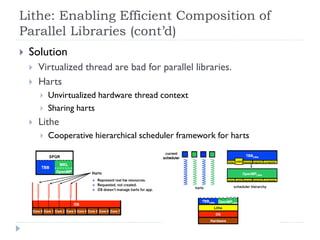





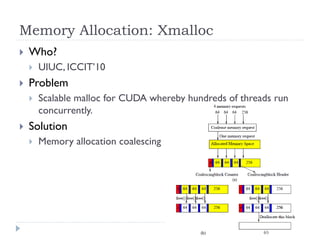








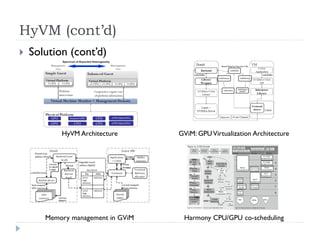
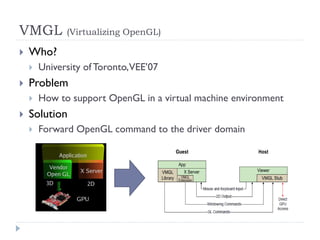

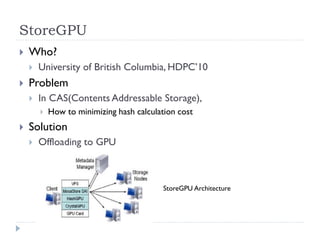
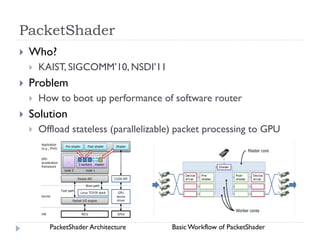



1) The document surveys research on parallel computing using multicore CPUs and GPUs, and its implications for system software. 2) It discusses parallel programming models like OpenMP, Intel TBB, CUDA, and OpenCL. It also covers research on optimizing memory allocation, reducing system call overhead, and revisiting OS architecture for manycore systems. 3) The document reviews work on supporting GPUs in virtualized environments through techniques like GPU virtualization. It also summarizes projects that utilize the GPU in middleware for tasks like network packet processing.


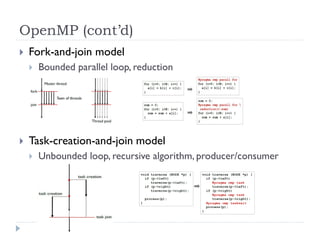
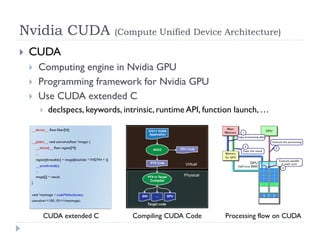
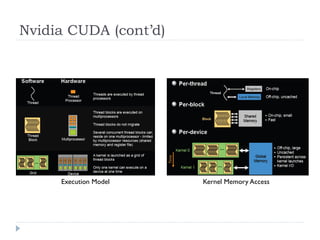
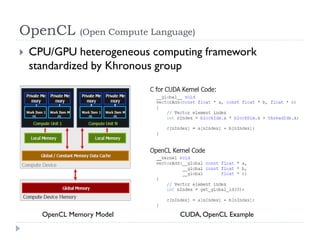
![[Harvard CS264] 06 - CUDA Ninja Tricks: GPU Scripting, Meta-programming & Aut...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201106-cudaninjasharetmp-110301171948-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















































