







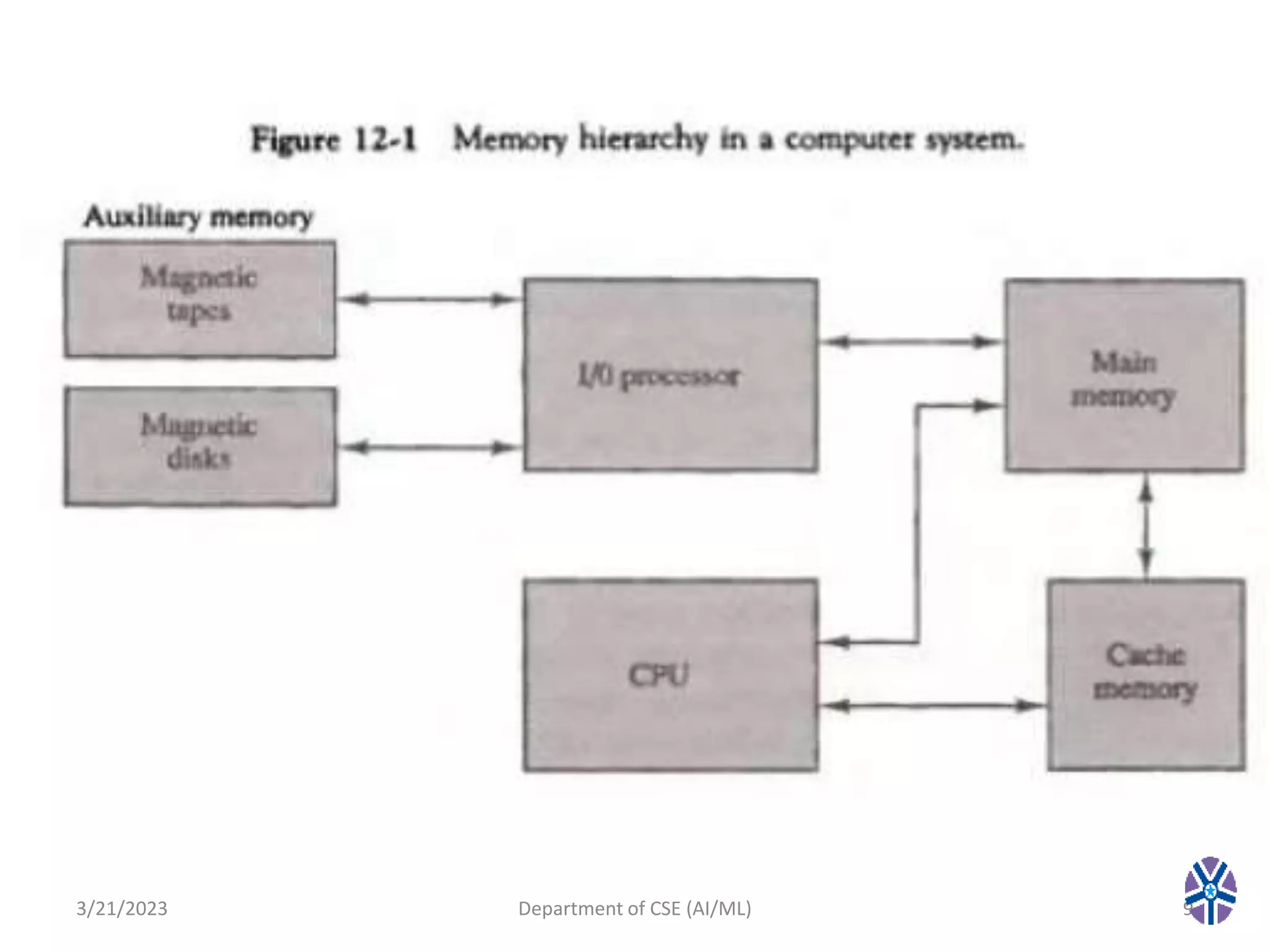




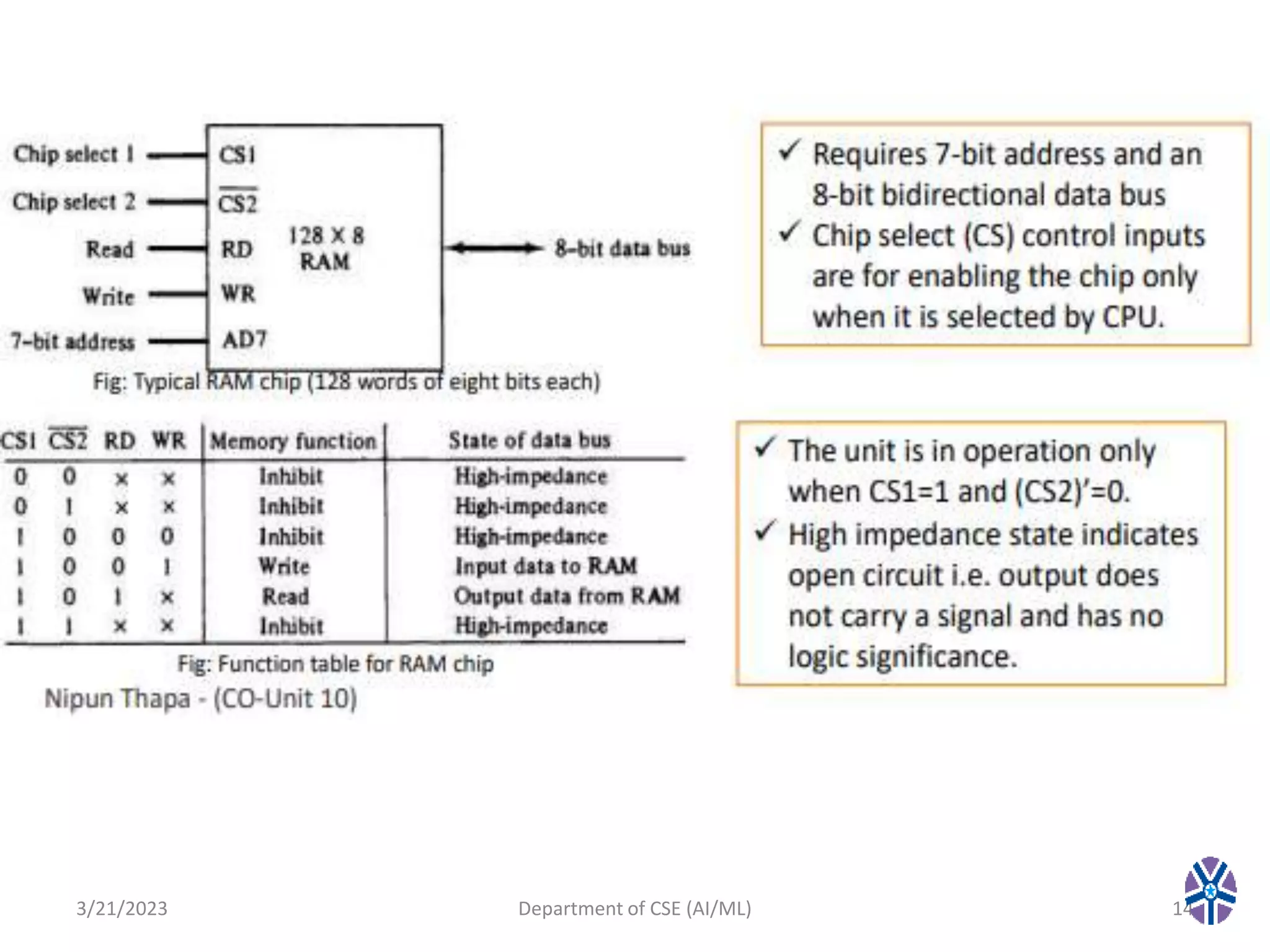
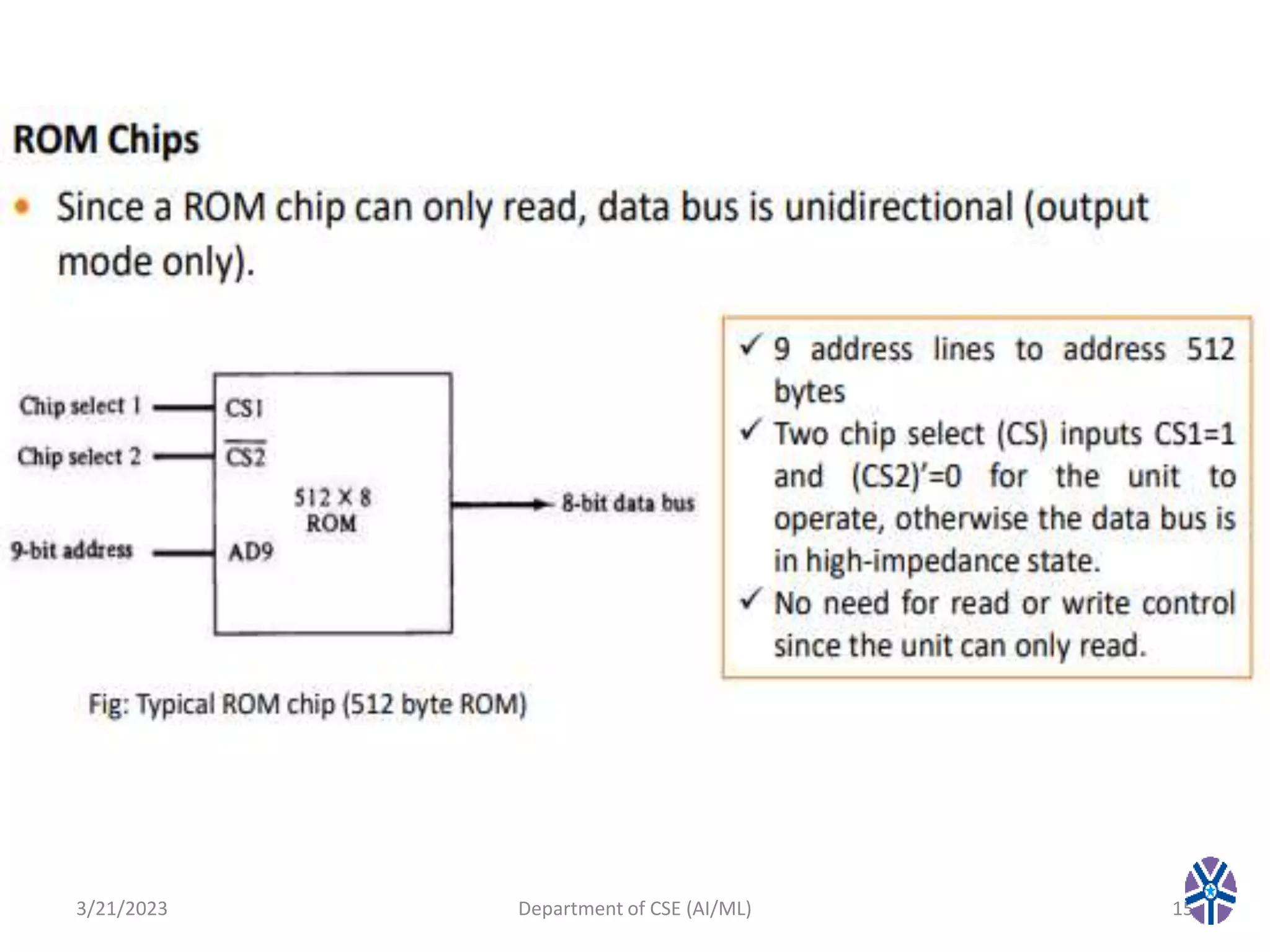




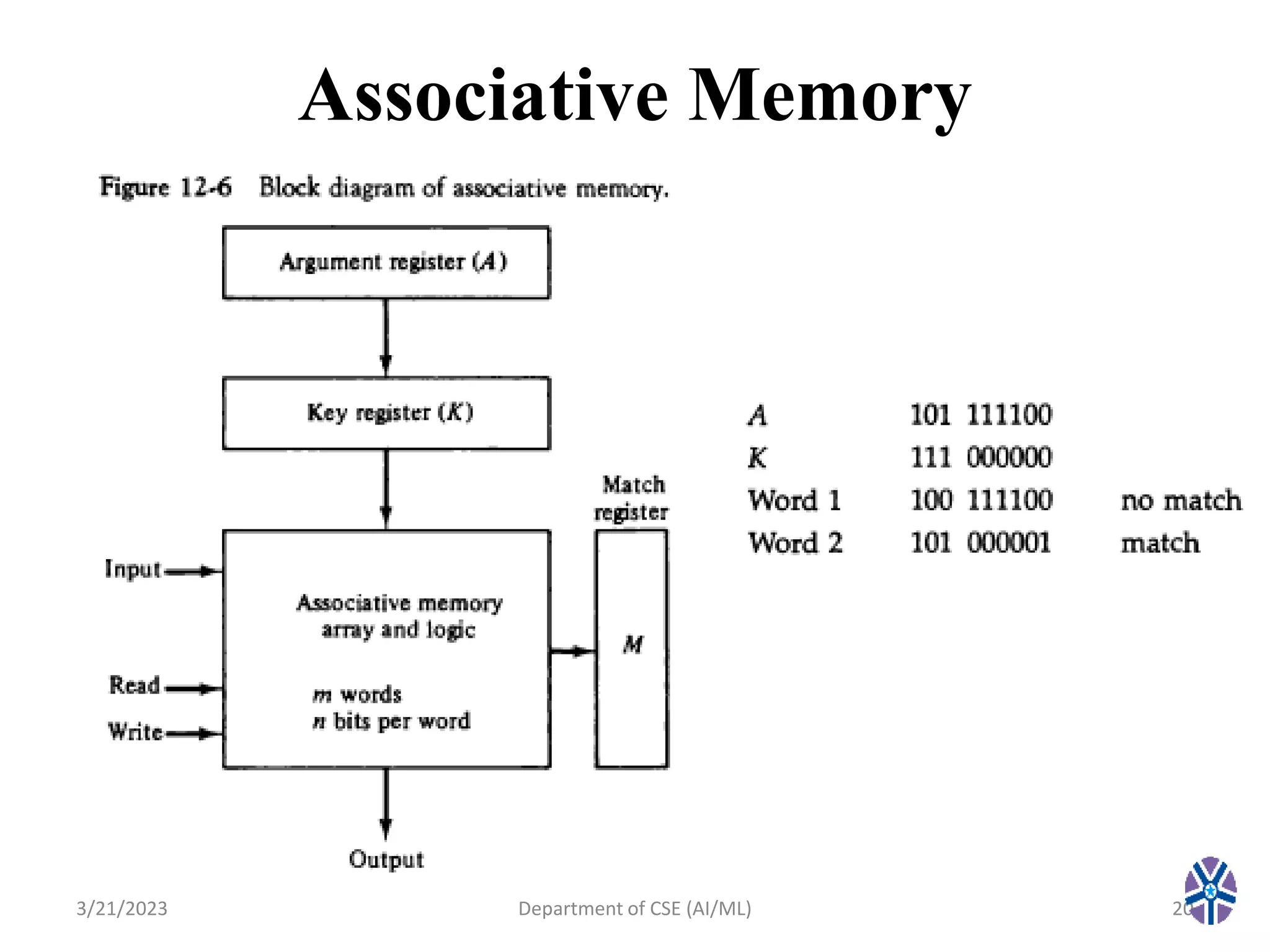
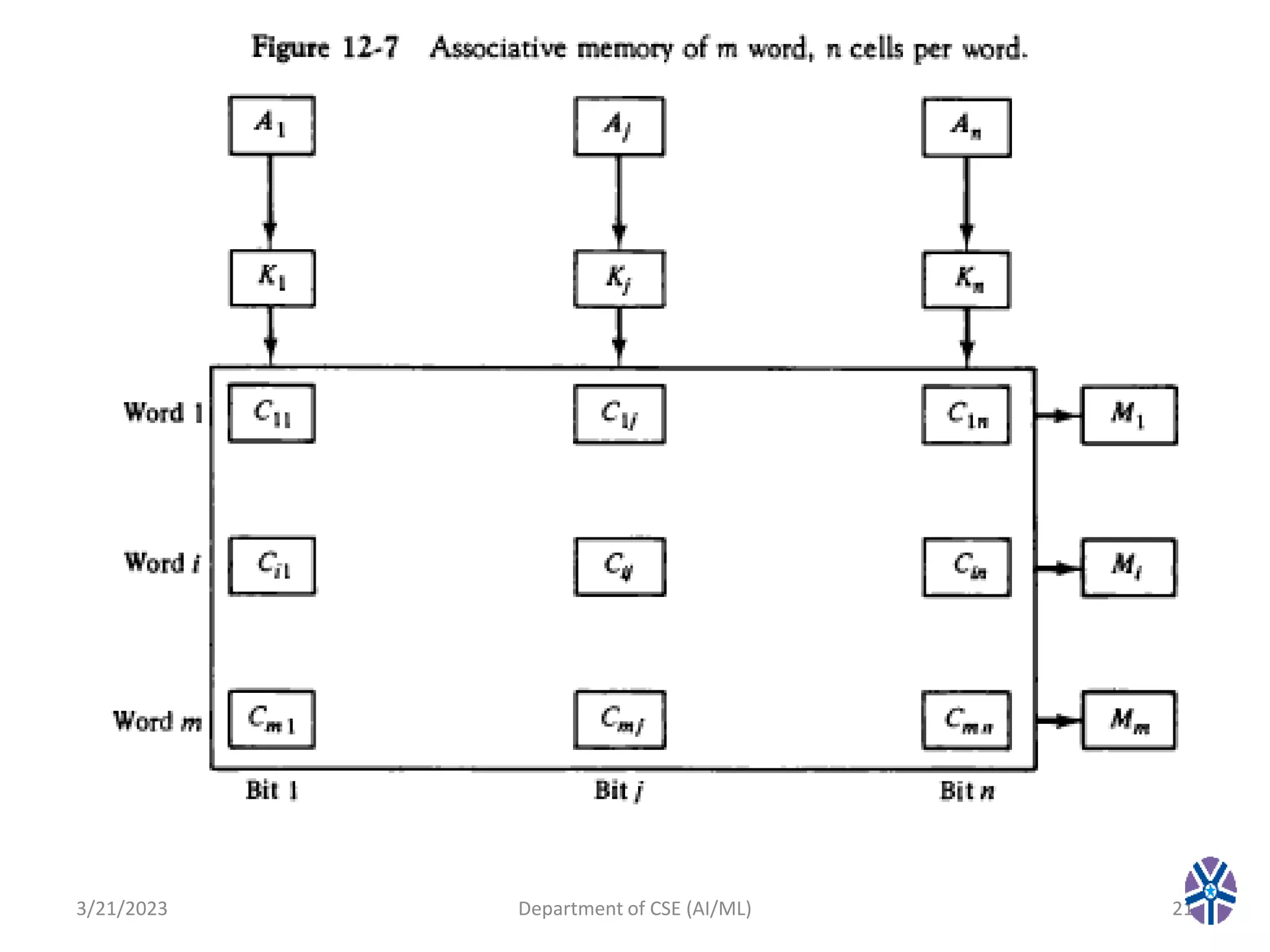


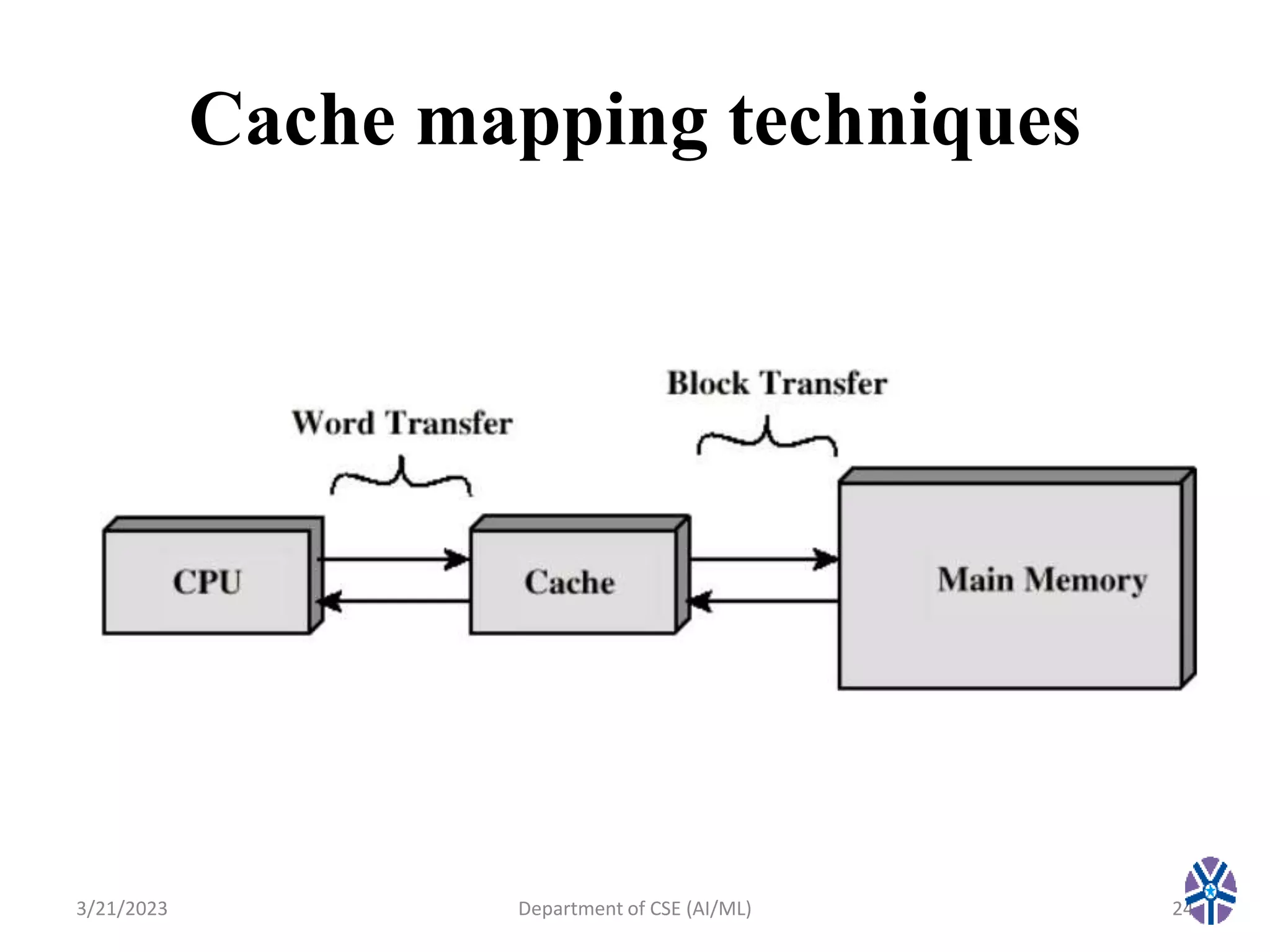
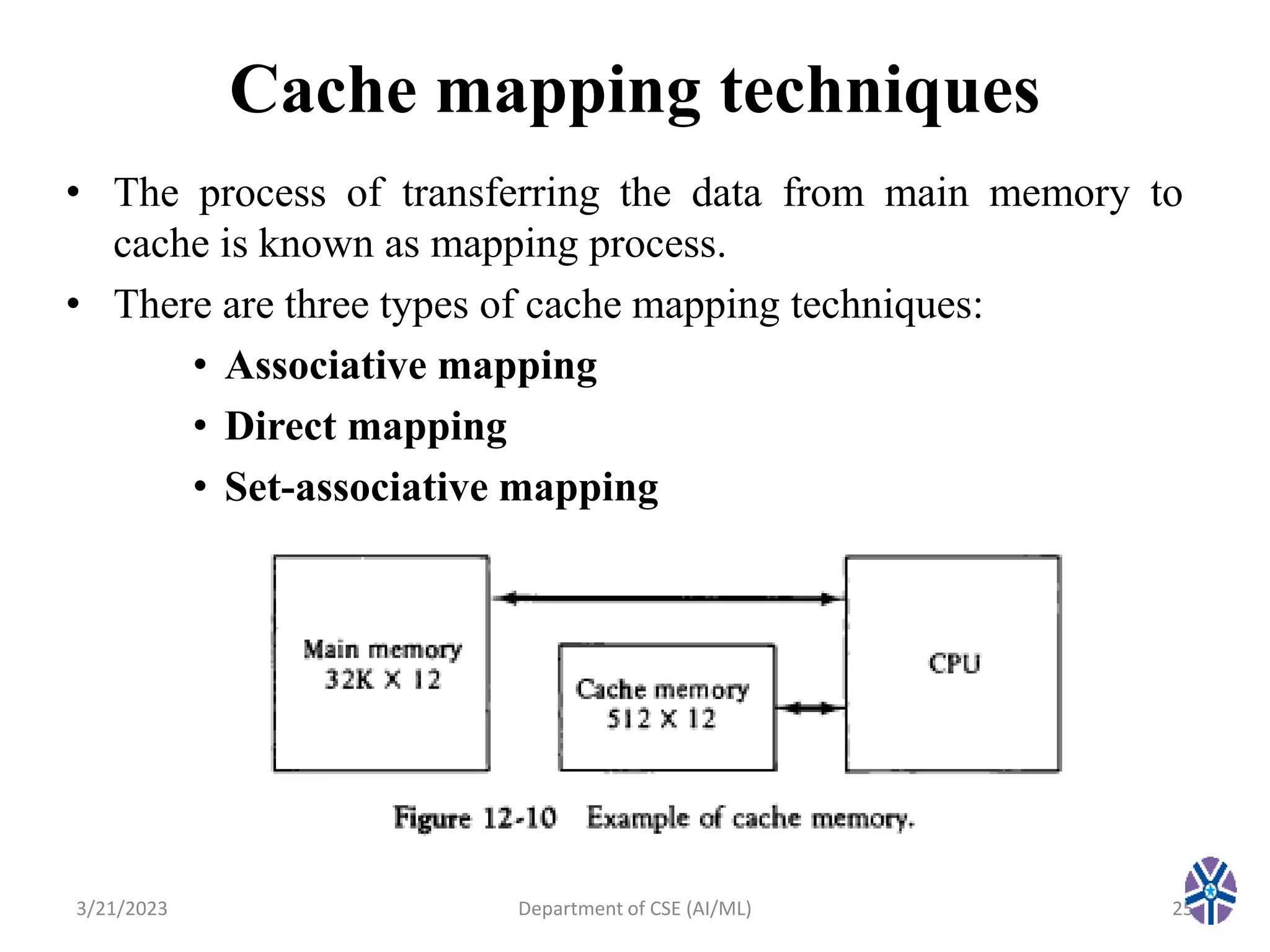


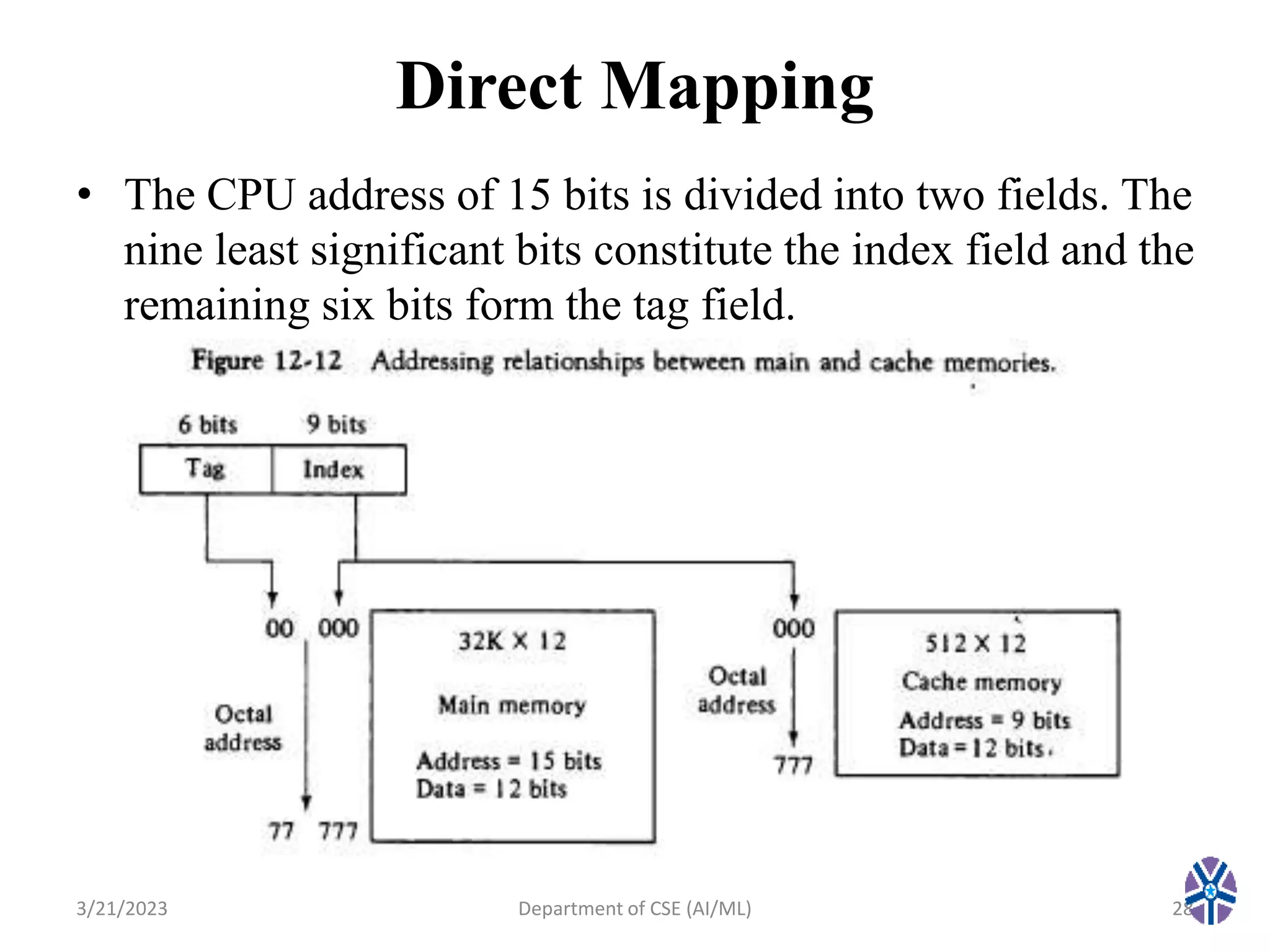

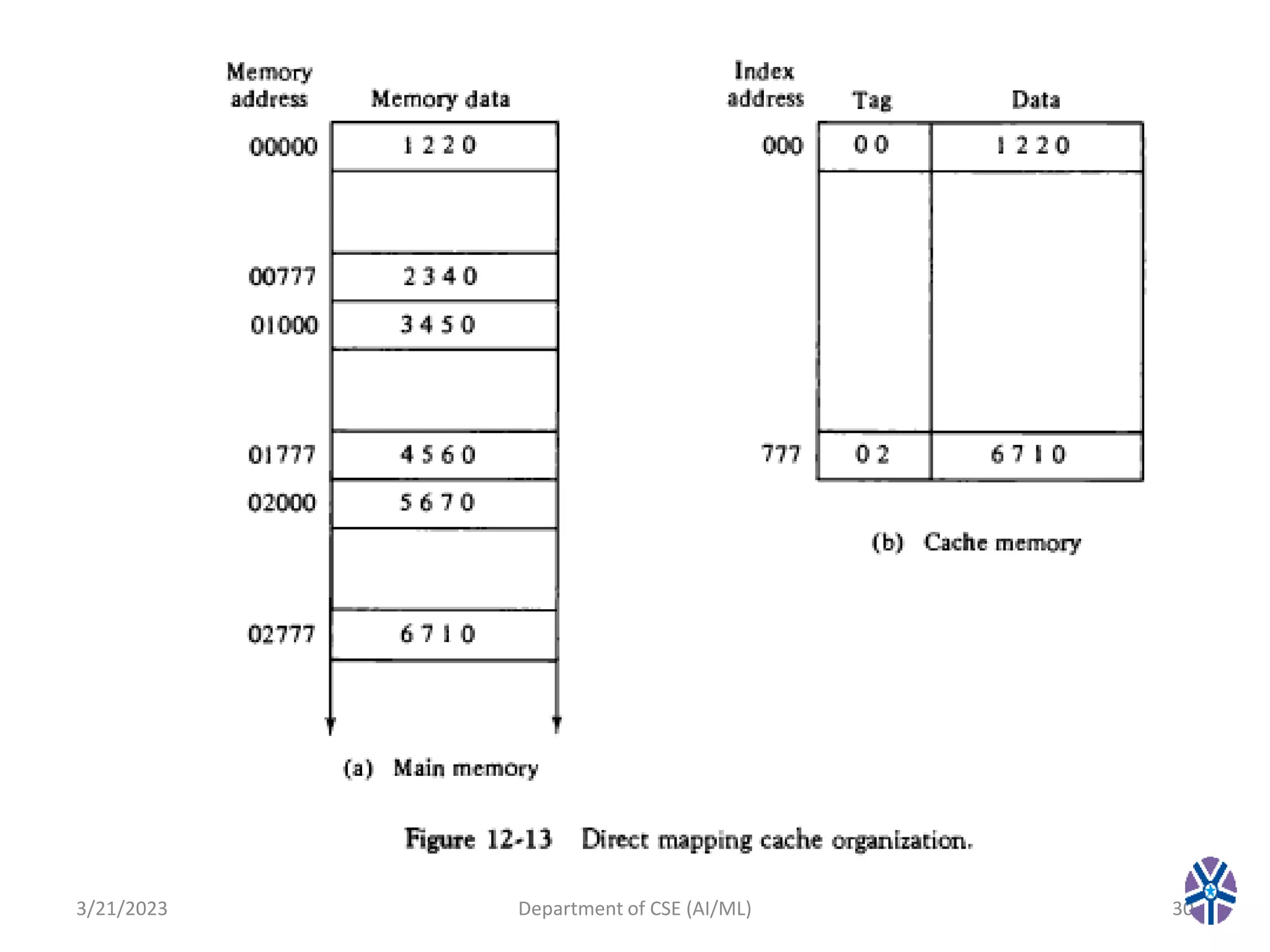






This document summarizes a session on memory organization that was presented by Asst. Prof. M. Gokilavani at VITS. The session covered topics related to memory hierarchy including main memory, auxiliary memory, associative memory, and cache memory. It described the characteristics of different memory types, such as static vs dynamic RAM, RAM vs ROM, and cache mapping techniques like direct mapping, set-associative mapping, and associative mapping. Examples were provided to illustrate memory addressing and cache organization.



































































