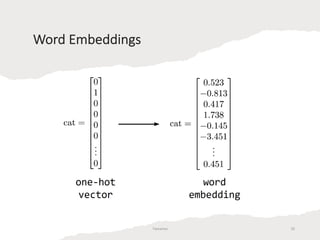
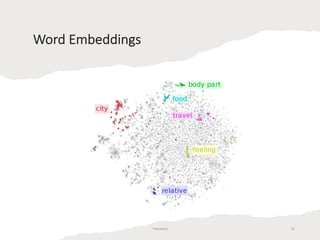
Embeddings are generally better than TF-IDF features for several reasons. TF-IDF represents words as high-dimensional, sparse vectors based on word counts, but embeddings represent words as low-dimensional, dense vectors that encode semantic relationships between words. Embeddings reduce dimensionality and computation costs compared to TF-IDF while capturing similarities between related words. While TF-IDF assumes words are independent, embeddings place similar words in close proximity in vector space.




















![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2740-thumbnail.jpg?width=640&height=640&fit=bounds)











































































