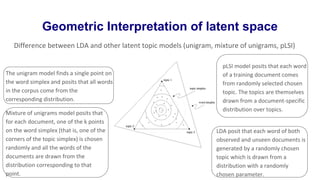
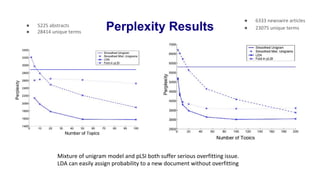
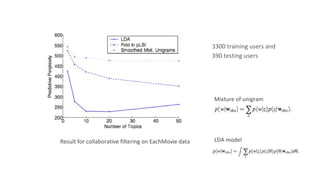
Latent Dirichlet Allocation (LDA) is a generative probabilistic model for collections of discrete data such as text corpora. LDA represents documents as random mixtures over latent topics, characterized by probability distributions over words. LDA addresses limitations of previous topic models like pLSI by treating topic mixtures as random variables rather than document-specific parameters. Variational inference and EM algorithms are used for parameter estimation in LDA. Empirical results show LDA outperforms other models on tasks like document modeling, classification, and collaborative filtering.










![Latent Dirichlet Allocation
❏ Generative probabilistic model of a corpus
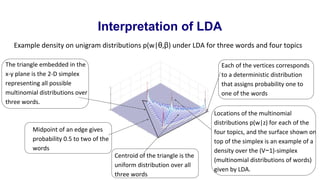
The basic idea is that documents are represented as random mixtures over latent topics
Each topic is characterized by a distribution over words.
❏ LDA generative process for each document w in a corpus D:
1. Choose N ∼ Poisson(ξ)
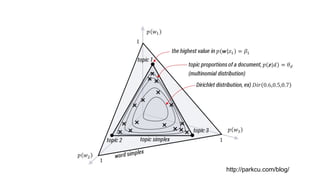
2. Choose θ ∼ Dir(α)
3. For each of the N words wn:
(a) Choose a topic zn ∼ Multinomial(θ).
(b) Choose a word wn from p(wn |zn,β), a multinomial probability conditioned on the topic zn.
❏ Several simplifying assumption : [1] The dimensionality k of the Dirichlet distribution (and
thus the dimensionality of topic variable z) is assumed to be known and fixed [2] The word
probabilities are parameterized by k ×V matrix β where which for now we
treat as a fixed quantity to be estimated. [3] Poisson assumption is not critical to anything.
[4] N is independent to all other data generating θ and z](https://image.slidesharecdn.com/latentdirichletallocationpresentation-170207195630/85/Latent-dirichletallocation-presentation-10-320.jpg)