Downloaded 21 times












![21
Spark’s window operations
(source: http://spark.apache.org/docs/latest/streaming-programming-guide.html)
countByWindow(windowLength,slideInterval) Return a sliding window count of elements in the stream.
reduceByWindow(func, windowLength,slideInterval) Return a new single-element stream, created by aggregating
elements in the stream over a sliding interval using func. The
function should be associative so that it can be computed
correctly in parallel.
reduceByKeyAndWindow(func,windowLength,
slideInterval, [numTasks])
When called on a DStream of (K, V) pairs, returns a new
DStream of (K, V) pairs where the values for each key are
aggregated using the given reduce function func over batches in a
sliding window [...]
reduceByKeyAndWindow(func, invFunc,windowLength,
slideInterval, [numTasks])
A more efficient version of the
above reduceByKeyAndWindow() where the reduce value of
each window is calculated incrementally using the reduce values
of the previous window. This is done by reducing the new data
that enters the sliding window, and “inverse reducing” the old
data that leaves the window. An example would be that of
“adding” and “subtracting” counts of keys as the window slides.
However, it is applicable only to “invertible reduce functions”
[...]](https://image.slidesharecdn.com/dsnutshell-160603105457/75/Data-Streaming-in-a-Nutshell-and-Spark-s-window-operations-21-2048.jpg)




![References (non exhaustive list)
Shared-memory parallelism / fine-grained synchronization
1. ScaleJoin: a Deterministic, Disjoint-Parallel and Skew-Resilient Stream Join. Vincenzo Gulisano, Yiannis
Nikolakopoulos, Marina Papatriantafilou, Philippas Tsigas. IEEE International Conference on Big Data
(IEEE Big Data 2015)
2. DEBS Grand Challenge: Deterministic Real-Time Analytics of Geospatial Data Streams through ScaleGate
Objects. Vincenzo Gulisano, Yiannis Nikolakopoulos, Ivan Walulya, Marina Papatriantafilou, Philippas
Tsigas. The 9th ACM International Conference on Distributed Event-Based Systems (DEBS 2015)
3. Concurrent Data Structures for Efficient Streaming Aggregation (brief announcement). Daniel Cederman,
Vincenzo Gulisano, Yiannis Nikolakopoulos, Marina Papatriantafilou, Philippas Tsigas. The 26th Annual
ACM Symposium on Parallelism in Algorithms and Architectures (SPAA) 2014
Streaming + Security / Privacy / Cyber-physical systems
1. Understanding the Data-Processing Challenges in Intelligent Vehicular Systems. Stefania Costache, Vincenzo
Gulisano, Marina Papatriantafilou. 2016 IEEE Intelligent Vehicles Symposium (IV16)
2. BES – Differentially Private and Distributed Event Aggregation in Advanced Metering
Infrastructures. Vincenzo Gulisano, Valentin Tudor, Magnus Almgren and Marina Papatriantafilou. 2nd
ACM Cyber-Physical System Security Workshop (CPSS 2016) [held in conjunction with ACM AsiaCCS’16],
2016.
3. METIS: a Two-Tier Intrusion Detection System for Advanced Metering Infrastructures. Vincenzo Gulisano,
Magnus Almgren, Marina Papatriantafilou. 10th International Conference on Security and Privacy in
Communication Networks (SecureComm) 2014
26](https://image.slidesharecdn.com/dsnutshell-160603105457/75/Data-Streaming-in-a-Nutshell-and-Spark-s-window-operations-26-2048.jpg)






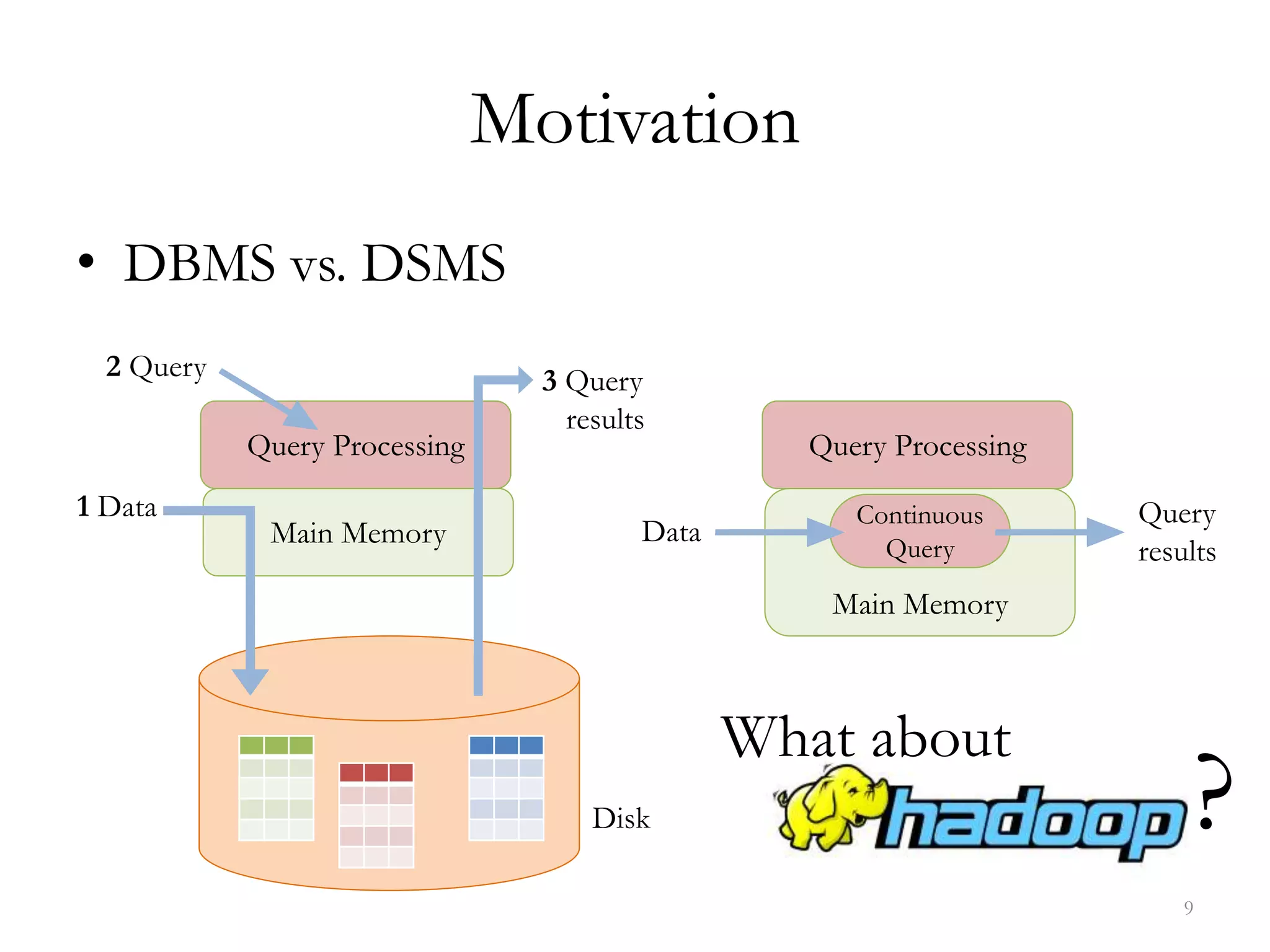
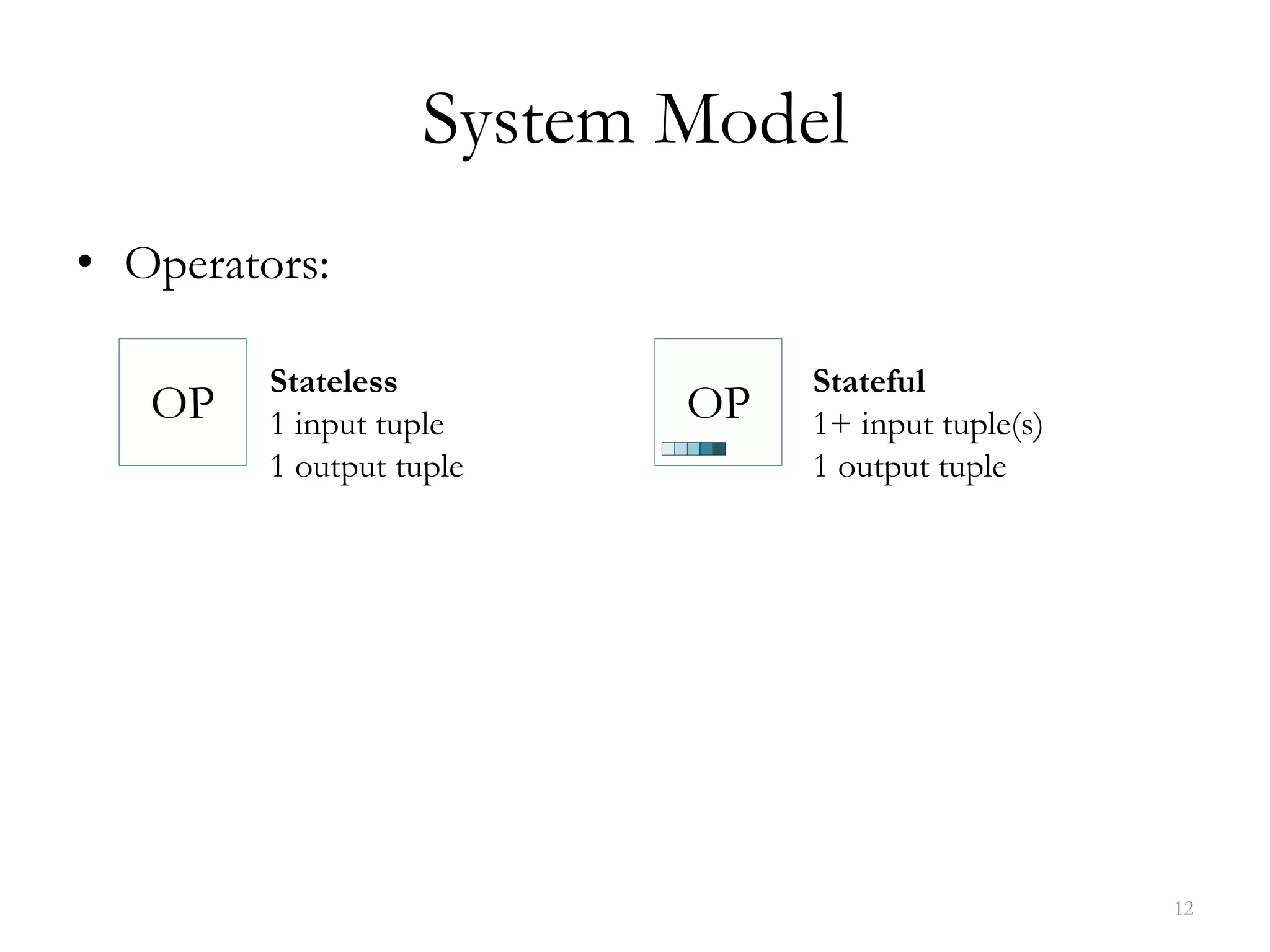
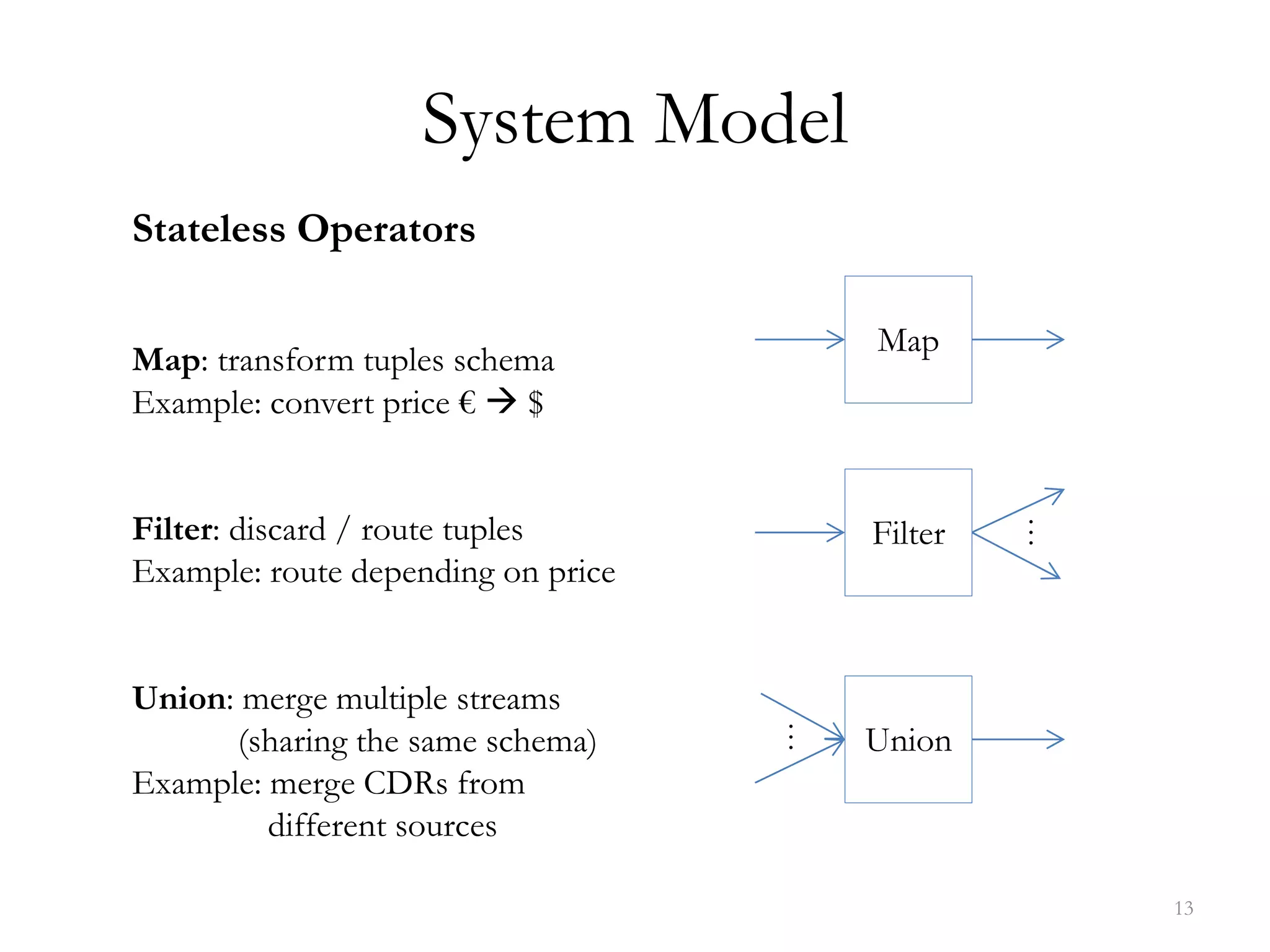
The document discusses data streaming, its significance in real-time data processing, and outlines Spark's window operations for handling continuous data streams. It highlights the limitations of traditional database systems for high-speed data and introduces a system model that incorporates stateless and stateful operators. References to various research and methodologies related to stream processing are also provided.





















































































