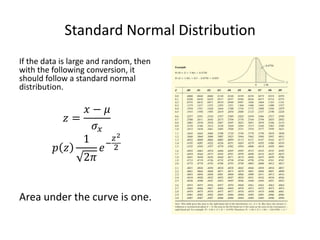
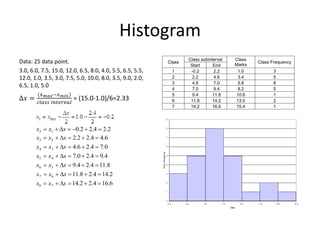
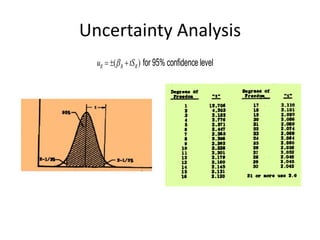
This document defines key statistical terms and concepts. It discusses populations and samples, measures of central tendency like mean and median, measures of variation like standard deviation and coefficient of variation, distributions like Gaussian and standard normal, and methods of analyzing data like linear regression and correlation coefficient. Uncertainty analysis is also covered, including identifying possible outliers using z-scores and Chauvenet's criterion.