


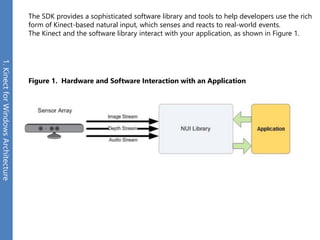

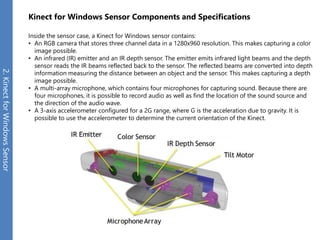


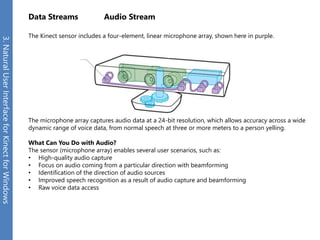





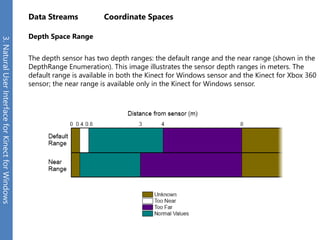


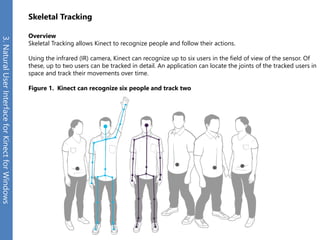

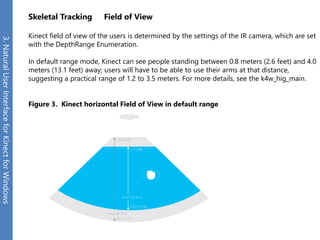
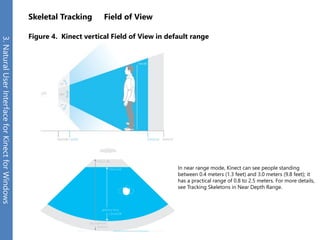
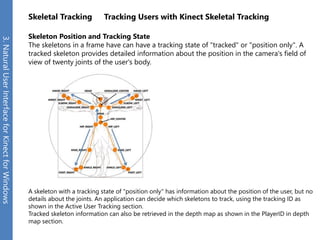
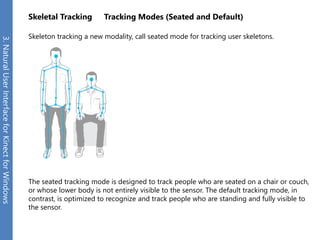
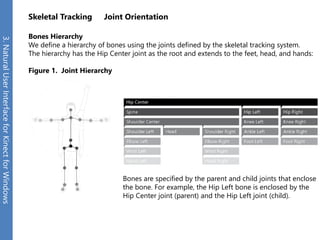
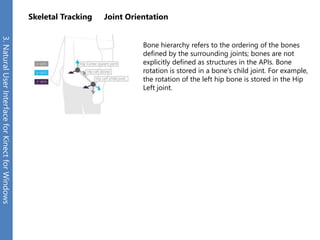
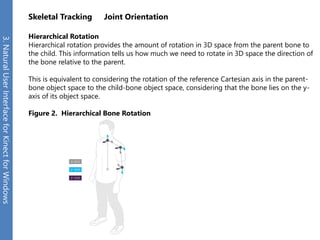





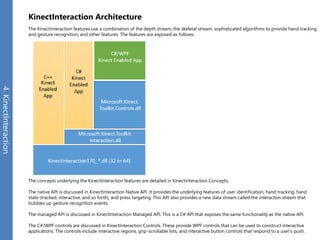





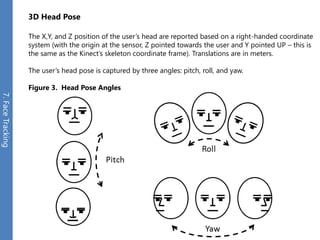


The document provides an overview of the Kinect for Windows SDK and its capabilities for natural user interface and skeletal tracking. It describes the Kinect hardware components, software architecture, data streams for color, depth, infrared and audio data. It explains how to retrieve frames of data through polling or events. It also covers coordinate systems, skeletal tracking, and transforming between spaces. The SDK enables applications to sense natural input through skeletal tracking, audio capture and analysis of color/depth images.


































































































