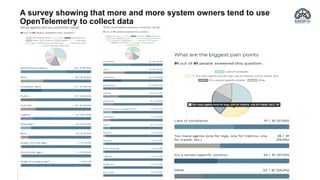
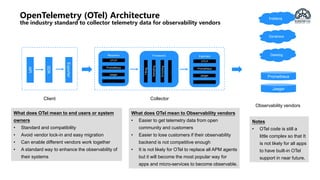
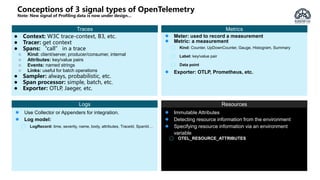
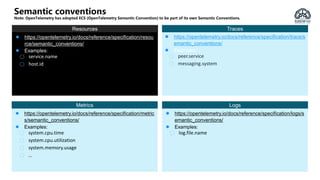
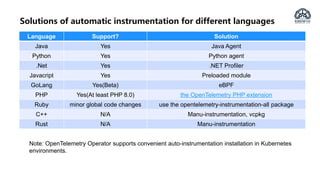
The document provides an overview of OpenTelemetry, an open-source project for service instrumentation to enhance observability. It discusses its architecture, automatic/manual instrumentation solutions for various programming languages, and best practices for deploying OpenTelemetry collectors. Key benefits include standardization, interoperability, and ease of data collection for both system owners and observability vendors.























































![Jacob Marble [InfluxData] | Observability with InfluxDB IOx and OpenTelemetry...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdbioxandopentelemetry-27-oct-2021jmarble-211022195239-thumbnail.jpg?width=640&height=640&fit=bounds)