Downloaded 26 times
















![...Continued
● UDF Handler:
https://github.com/influxdata/kapacitor/tree/master/udf/agent/examples/moving_avg
● TICK Script
stream
|from()
.measurement('cpu')
.where(lambda: "cpu" == 'cpu-total')
@pyavg()
.field('usage_idle')
.size(10)
.as('cpu_avg')
|influxDBOut()
.database('udf')
[udf]
[udf.functions]
[udf.functions.pyavg]
prog = "/usr/bin/python2"
args = ["-u",
"/etc/kapacitor/script/kapacitor/udf/agent/examples/moving_av
g/moving_avg.py"]
timeout = "10s"
[udf.functions.pyavg.env]
PYTHONPATH =
"/etc/kapacitor/script/kapacitor/udf/agent/py"](https://image.slidesharecdn.com/kapacitor-180429183051/85/Kapacitor-Real-Time-Data-Processing-Engine-18-320.jpg)
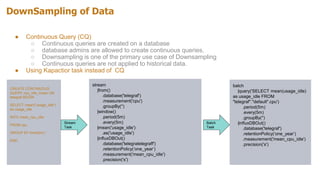
![Enriching Your Data with Kapacitor
Problem: How do I summarize my data for the entire month of August just for business hours, defined by Monday through
Friday between 0800AM and 0500PM for a range of time.
● As per InfluxQL we are limited to : SELECT * FROM “mymeasurement” WHERE time >= ‘2017-08-01
08:00:00.000000’ and time <= ‘2017-08-31 17:00:00.000000’;
● Configure Telegraf to write to Kapacitor instead of directly to InfluxDB
[[outputs.influxdb]]
urls = [http://localhost:9092]
database = “kap_telegraf”
retention_policy = “autogen”](https://image.slidesharecdn.com/kapacitor-180429183051/85/Kapacitor-Real-Time-Data-Processing-Engine-19-320.jpg)



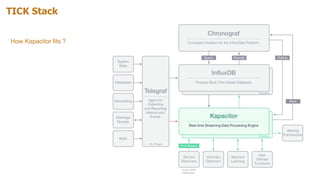
The document provides an overview of Kapacitor, a real-time data processing engine that integrates with the TICK stack to handle stream and batch data from InfluxDB. It discusses installation steps, key capabilities such as alerting and anomaly detection, and the use of TICKscripts for defining tasks. Additionally, it covers the creation of continuous queries, user-defined functions, and methods for enriching data, while offering hands-on examples and considerations for selecting between stream and batch tasks.










![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)


























![Ryan Betts [InfluxData] | Influxdays Keynote: Engineering Update | InfluxDays...](https://cdn.slidesharecdn.com/ss_thumbnails/ryan-influxdays-na-2021-211026005555-thumbnail.jpg?width=640&height=640&fit=bounds)




![Balaji Palani [InfluxData] | InfluxDB Tasks Overview | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/dem13tasksoverviewdemobalajipalani-221020205918-ba7ebf60-thumbnail.jpg?width=640&height=640&fit=bounds)
























