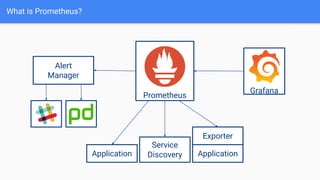
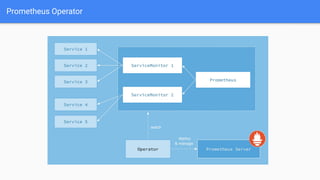
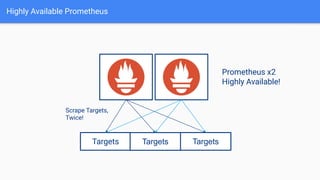
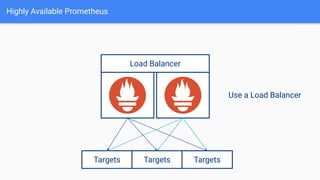
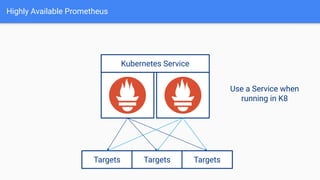
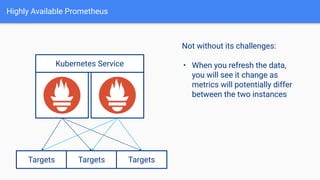
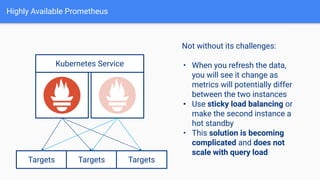
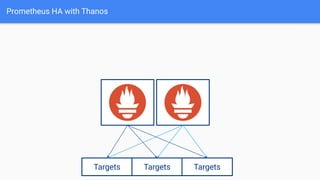
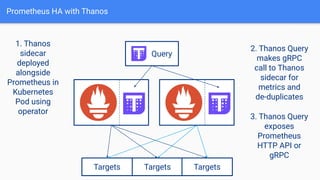
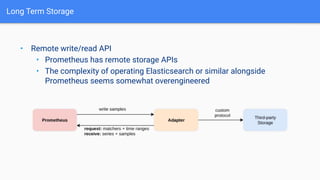
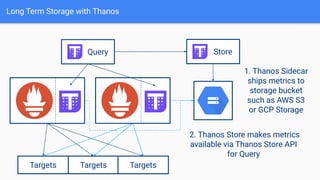
The document provides a comprehensive guide on using Prometheus for Kubernetes observability, including its deployment, monitoring capabilities, and high availability solutions. It highlights the challenges of managing multiple instances and introduces Thanos as a solution for long-term metric storage and high availability. The author emphasizes using the Prometheus operator for automation and building dashboards to enhance observability.