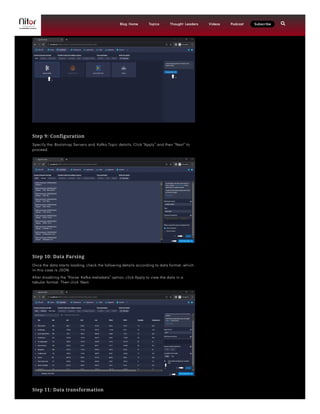
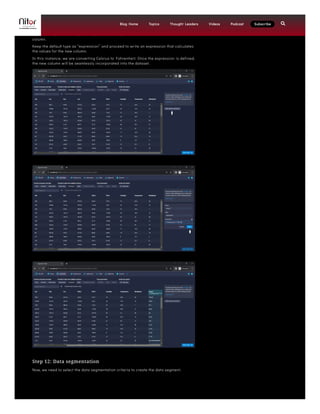
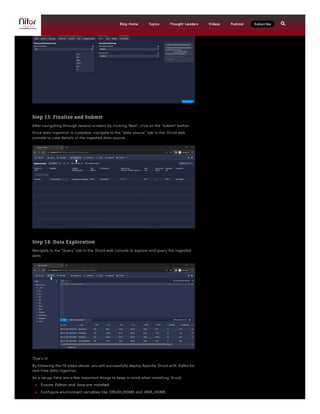
This document provides a comprehensive guide on installing and using Apache Druid for real-time analytics, including prerequisites such as Java, familiarity with Linux, and knowledge of data formats like SQL and JSON. It outlines a detailed 14-step process for deploying Apache Druid with Kafka for real-time data ingestion, emphasizing crucial configuration and data transformation steps. By following these instructions, users can set up a functional Apache Druid cluster capable of handling both historical and real-time data analytics.