Download as PDF, PPTX




















![Kafka Startup
Kafka
Broker
Get Metadata
Client
Return Metadata
Metadata Response
{
"Brokers": [
{
"NodeId": 0,
"Host": "broker0.yourdomain.com",
"Port": 9092
},
{
"NodeId": 1,
"Host": "broker1.yourdomain.com",
"Port": 9092
},
{
"NodeId": 2,
"Host": "broker2.yourdomain.com",
"Port": 9092
}
],
"Topics": [],
…
}
Connect to one of the
brokers](https://image.slidesharecdn.com/2023-11-15pspartnerqa-231115124305-c8042372/85/Q-A-with-Confluent-Professional-Services-Confluent-Service-Mesh-26-320.jpg)
![Kafka Startup With CSM
Return Metadata
Kafka
Broker
CSM
Get Metadata
Client
Modify Metadata
Return Metadata
Modified Metadata Response
{
"Brokers": [
{
"NodeId": 0,
"Host": "csm.yourdomain.com",
"Port": 30001
},
{
"NodeId": 1,
"Host": "csm.yourdomain.com",
"Port": 30002
},
{
"NodeId": 2,
"Host": "csm.yourdomain.com",
"Port": 30003
}
],
"Topics": [],
…
}
Connect to a CSM port](https://image.slidesharecdn.com/2023-11-15pspartnerqa-231115124305-c8042372/85/Q-A-with-Confluent-Professional-Services-Confluent-Service-Mesh-27-320.jpg)




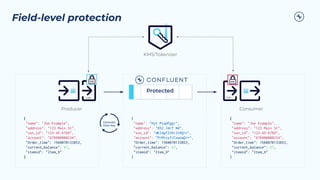
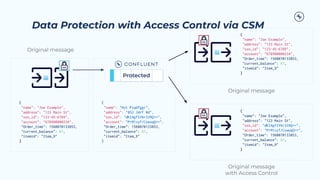
![Integration with Data catalogs, classification
Data classification
{
"type":"record",
"name":"DataClassifications",
"classifications":{
"PII":{
"encrypt":{
"key":"SamplePIIKey",
"wrapping.key":"RSAPII"
},
"classifications":{
"Personal":{
"tokenize":{ }
},
"Financial":{
"encrypt":{
"key":"SampleFinancialKey",
"wrapping.key":"RSAPIIFinancial"
}
}
}
},
"Protected": {
"encrypt": {
"authorizer.class": "classNameHere",
"authorizer.deny": false,
"opa.module.name": "classification",
"opa.rego": "/csm/classification.rego",
"opa.query": "data.classification.allow"
}
}
},
"fields":[ ]
Data Catalog
{
"type":"record",
"name":"ADataCatalog",
"namespace":"com.mybusiness",
"fields":[
{
"name":"SSN",
"type":"string",
"classifications": ["PII/Financial",
“Protected”]
},
{
"name":"Name",
"type":"string",
"classifications": ["PII/Personal",
“Protected”]
},
{
"name":"Address",
"type":"string",
"classifications": ["PII/Personal",
“Protected”]
},
{
"name":"Account",
"type":"string",
"classifications": ["PII/Financial",
“Protected”]
PII/Personal Name: Joe Example
PII/Personal Address: 123 Main St
CustID: 12345
PII/Financial SSN: 123-45-6789
Persona: 56A
Credit: 780
PII/Financial Acct #: 3456789
Current Balance: 0
PII/Personal Name: Hyt Piqdfggr
PII/Personal Address: 852 Jdrf Wd
CustID: 12345
PII/Financial SSN: dKI4gflV6r339Q==
Persona: 56A
Credit: 780
PII/Financial Acct #: PrM1vyf/CxwoqQ==
Current Balance: 0](https://image.slidesharecdn.com/2023-11-15pspartnerqa-231115124305-c8042372/85/Q-A-with-Confluent-Professional-Services-Confluent-Service-Mesh-43-320.jpg)


![Example: CSM Auth Swapping Configurations
…
csm.ssl=true
csm.ssl.enabled=true
csm.ssl.truststore.location=${truststore}
csm.ssl.truststore.password=confluent
csm.ssl.keystore.location=${keystore}
csm.ssl.keystore.password=confluent
csm.ssl.key.password=confluent
csm.ssl.client.auth=required
csm.ssl.principal.mapping.rules: RULE:^CN=([a-zA-Z.0-9@-]+).*$/$1/,DEFAULT
…
csm.authorizers=vaultAuth
vaultAuth.class=io.confluent.csid.csm.auth.VaultAuth
vaultAuth.vault.address=http://vault:8200
vaultAuth.vault.auth.token=vault-plaintext-root-token
vaultAuth.vault.store=secret/testing
vaultAuth.vault.split=/
…
mTLS Configuration
…
csm.ssl=true
sasl.enabled.mechanisms=GSSAPI
csm.sasl.mechanism=GSSAPI
…
csm.authorizers=vaultAuth
vaultAuth.class=io.confluent.csid.csm.auth.VaultAuth
vaultAuth.vault.address=http://vault:8200
vaultAuth.vault.auth.token=vault-plaintext-root-token
vaultAuth.vault.store=secret/testing
vaultAuth.vault.split=/
…
Kerberos Configuration
Examples, Documentation:
https://confluentinc.github.io/csid-csm/](https://image.slidesharecdn.com/2023-11-15pspartnerqa-231115124305-c8042372/85/Q-A-with-Confluent-Professional-Services-Confluent-Service-Mesh-49-320.jpg)








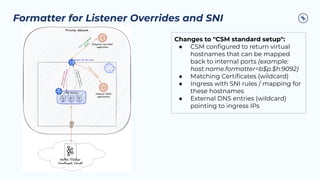
![Solution: Formatter for Listener Overrides
Return Metadata
Kafka
Broker
CSM
Get Metadata
Client
Modify Metadata
Return Metadata
Modified Metadata Response Updated
{
"Brokers": [
{
"NodeId": 0,
"Host": "csm.yourdomain.com",
"Port": 30001
"Host": "b30001.csm.yourdomain.com",
"Port": 9092
},
{
"NodeId": 1,
"Host": "csm.yourdomain.com",
"Port": 30002
"Host": "b30002.csm.yourdomain.com",
"Port": 9092
},
…
],
"Topics": [],
…
}
Connect to a CSM port](https://image.slidesharecdn.com/2023-11-15pspartnerqa-231115124305-c8042372/85/Q-A-with-Confluent-Professional-Services-Confluent-Service-Mesh-63-320.jpg)
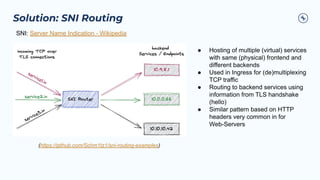





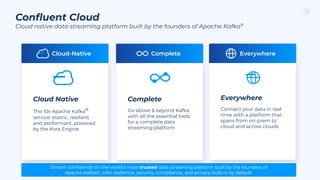
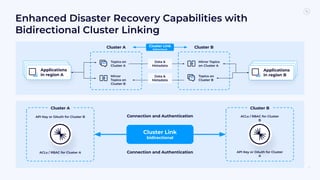
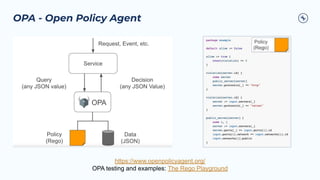
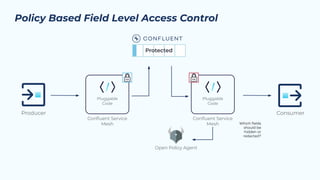
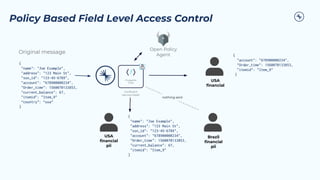
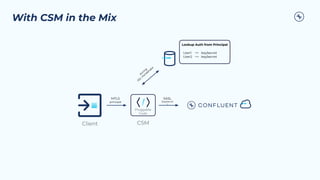
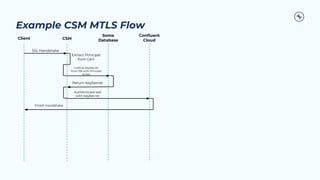
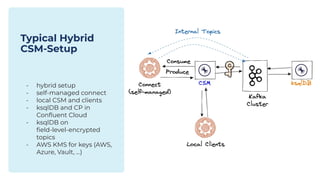
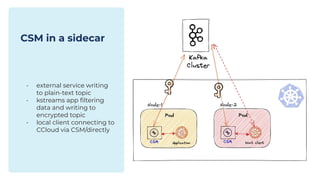
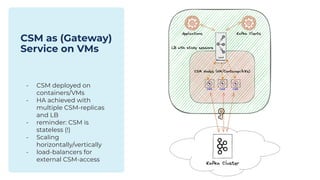
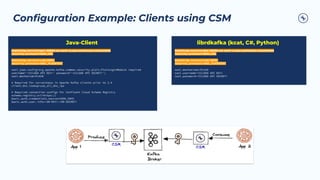
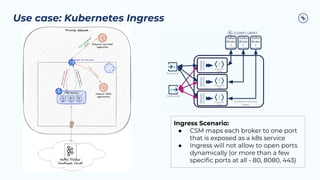
The document outlines the Confluent technical enablement sessions and Q&A offerings for partners, detailing various workshops, learning paths, and product updates focused on data streaming with Apache Kafka. It highlights upcoming features like bi-directional cluster linking and data governance tools to enhance security, reliability, and operational efficiency in cloud-native environments. Additionally, it introduces the Confluent Service Mesh, emphasizing data protection, observability, and encryption standards for cloud-native applications.























































































