Downloaded 54 times




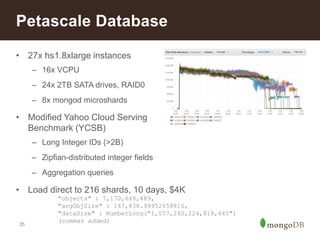
![Document Data Model
Relational MongoDB
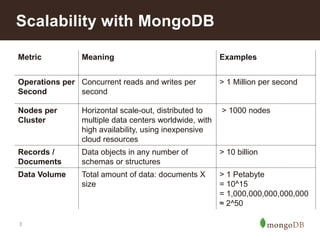
6
{
first_name: ‘Paul’,
surname: ‘Miller’,
city: ‘London’,
location:
[45.123,47.232],
cars: [
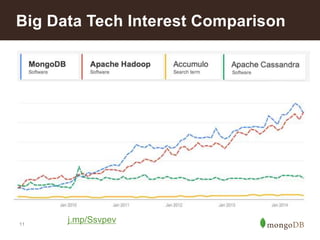
{ model: ‘Bentley’,
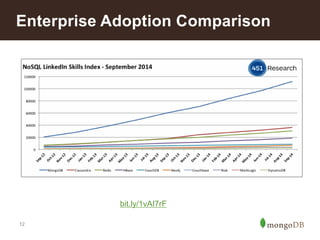
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
}
}](https://image.slidesharecdn.com/scalabilityandagilitymongodc-141014111327-conversion-gate01/85/Agility-and-Scalability-with-MongoDB-6-320.jpg)
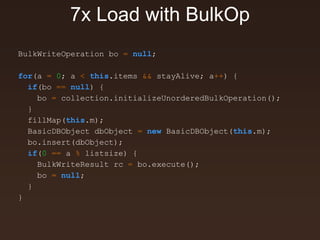
![Documents are Rich Data Structures
7
{
first_name: ‘Paul’,
surname: ‘Miller’,
cell: ‘+447557505611’
city: ‘London’,
location: [45.123,47.232],
Profession: [banking, finance, trader],
cars: [
{ model: ‘Bentley’,
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
}
}
Fields can contain an array of
sub-documents
Fields
Typed field values
Fields can
contain arrays](https://image.slidesharecdn.com/scalabilityandagilitymongodc-141014111327-conversion-gate01/85/Agility-and-Scalability-with-MongoDB-7-320.jpg)


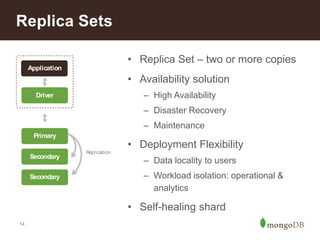
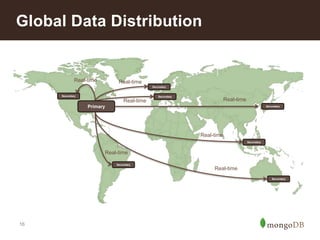
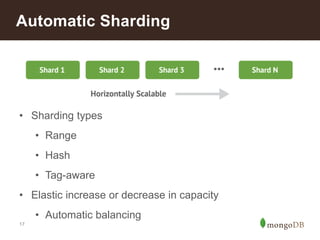
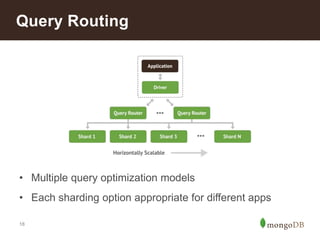







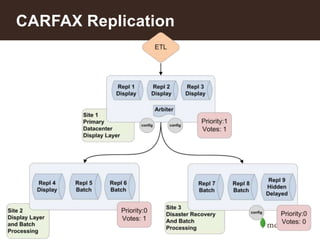
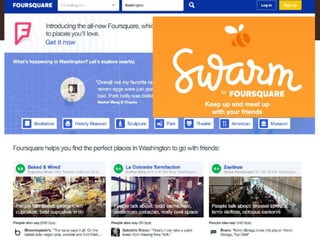









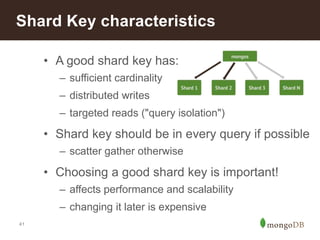
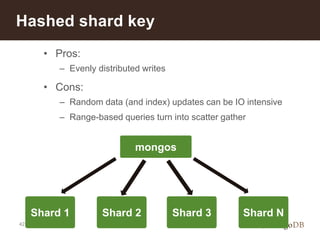
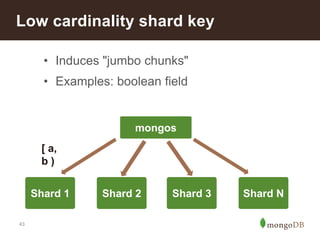
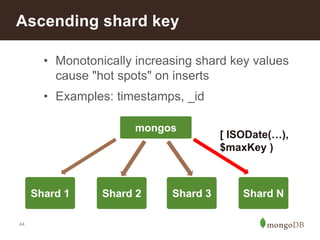



The document discusses MongoDB's scalability and agility, highlighting its capability for high availability and performance in handling large datasets across global data centers. It emphasizes the document data model's benefits, such as flexibility, simplicity in programming, and decreased reliance on joins, while also detailing various scaling and sharding techniques. Case studies, including vehicle history and location-based applications, showcase MongoDB's effectiveness in enterprise environments and its operational advantages over traditional databases.





![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)

























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































