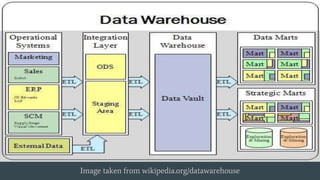
This document describes a data warehousing solution using Apache Spark that was developed by Team 18 for the Movielens 20M movie rating dataset. Key aspects of the solution include storing the dataset in HDFS for faster access, developing an API interface using Flask, querying the data through Spark RDDs in response to API calls, and using GraphX to plot graphs of results like movie rating progressions. The goal was to build a scalable data warehouse system for performing queries and basic analytics on large movie rating data.





















































![[REPORT] Women in Leadership: Why It Matters](https://cdn.slidesharecdn.com/ss_thumbnails/womeninleadership-whyitmatters-160512123606-thumbnail.jpg?width=640&height=640&fit=bounds)








































