




![Introduction
Existing Works
Proposed Approach
Conclusion
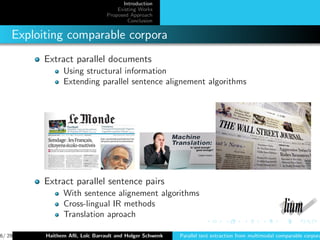
Main Existing Methods
Webcrawling [Resnik and Smith, 2003] : use URLs to find
matching documents
Alignment [Brown et al., 1991] : use word alignment models
to judge how close a source and a target document (sentence)
are
Crosslingual IR [Munteanu and Marcu, 2005] : use lexicon to
translate source words and apply information retrieval
techniques
Translation [Rauf and Schwenk, 2011] : use SMT system to
translate documents and apply information retrieval
7/ 29 Haithem Afli, Lo¨ Barrault and Holger Schwenk
ıc Parallel text extraction from multimodal comparable corpora](https://image.slidesharecdn.com/japtaloral-121104125415-phpapp01/85/Parallel-text-extraction-from-multimodal-comparable-corpora-7-320.jpg)















![Introduction
Existing Works
Proposed Approach
Conclusion
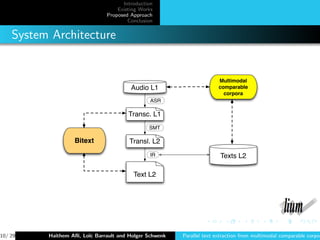
Crawling the Web [Resnik and Smith, 2003]
Search for web pages with similar URLs
Many companies and organizations have their web pages in
multiple languages
Identified by language ID, eg
http ://x.../y.../z.en and http ://x.../y.../z.fr
Pages have links to parallel pages
Webcrawler, which exploits this structural information
25/ 29 Haithem Afli, Lo¨ Barrault and Holger Schwenk
ıc Parallel text extraction from multimodal comparable corpor](https://image.slidesharecdn.com/japtaloral-121104125415-phpapp01/85/Parallel-text-extraction-from-multimodal-comparable-corpora-25-320.jpg)
![Introduction
Existing Works
Proposed Approach
Conclusion
Alignment Approach [Brown et al., 1991]
Train initial lexicon based on parallel data
Use lexicon to calculate alignment score between documents
(or sentences)
Typically IBM1
Select most reliable document (sentence) pairs
Add to parallel training data and retrain -> bootstrapping
26/ 29 Haithem Afli, Lo¨ Barrault and Holger Schwenk
ıc Parallel text extraction from multimodal comparable corpor](https://image.slidesharecdn.com/japtaloral-121104125415-phpapp01/85/Parallel-text-extraction-from-multimodal-comparable-corpora-26-320.jpg)
![Introduction
Existing Works
Proposed Approach
Conclusion
Finding Comparable Documents [Zhao and Vogel, 2002]
Given comparable documents, find (nearly) parallel sentences
Xinhua News Agency publishes news in English and Chinese
Calculate similarity based on lexicon
Iterative process
27/ 29 Haithem Afli, Lo¨ Barrault and Holger Schwenk
ıc Parallel text extraction from multimodal comparable corpor](https://image.slidesharecdn.com/japtaloral-121104125415-phpapp01/85/Parallel-text-extraction-from-multimodal-comparable-corpora-27-320.jpg)
![Introduction
Existing Works
Proposed Approach
Conclusion
CLIR Aproach [Munteanu and Marcu, 2005]
Figure: CLIR Aproach
28/ 29 Haithem Afli, Lo¨ Barrault and Holger Schwenk
ıc Parallel text extraction from multimodal comparable corpor](https://image.slidesharecdn.com/japtaloral-121104125415-phpapp01/85/Parallel-text-extraction-from-multimodal-comparable-corpora-28-320.jpg)
![Introduction
Existing Works
Proposed Approach
Conclusion
Translation Approach [Rauf and Schwenk, 2011]
Figure: Translation Approach
29/ 29 Haithem Afli, Lo¨ Barrault and Holger Schwenk
ıc Parallel text extraction from multimodal comparable corpor](https://image.slidesharecdn.com/japtaloral-121104125415-phpapp01/85/Parallel-text-extraction-from-multimodal-comparable-corpora-29-320.jpg)

The document proposes extracting parallel text from multimodal comparable corpora. It begins with introductions to statistical machine translation and parallel/comparable corpora. An existing approach is described that exploits comparable corpora. The proposed approach extracts parallel text by transcribing audio, translating the text, and using translations as queries for information retrieval on a target corpus. Experimental results show the extracted sentences improve an SMT system and matching the performance of an optimal experiment.

























































































