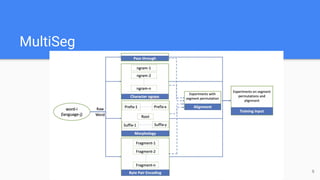
1) The document presents MultiSeg, a method for learning bilingual word embeddings using subword information like character n-grams, morphological segments, and byte-pair encoding, especially for low-resource languages.
2) MultiSeg is evaluated on tasks like word translation, word similarity, and document classification and is shown to outperform existing methods, particularly for morphologically rich languages.
3) Qualitative analysis using t-SNE visualizations indicates MultiSeg learns higher quality cross-lingual embeddings that better represent morphological variants in both languages.