Download as PDF, PPTX







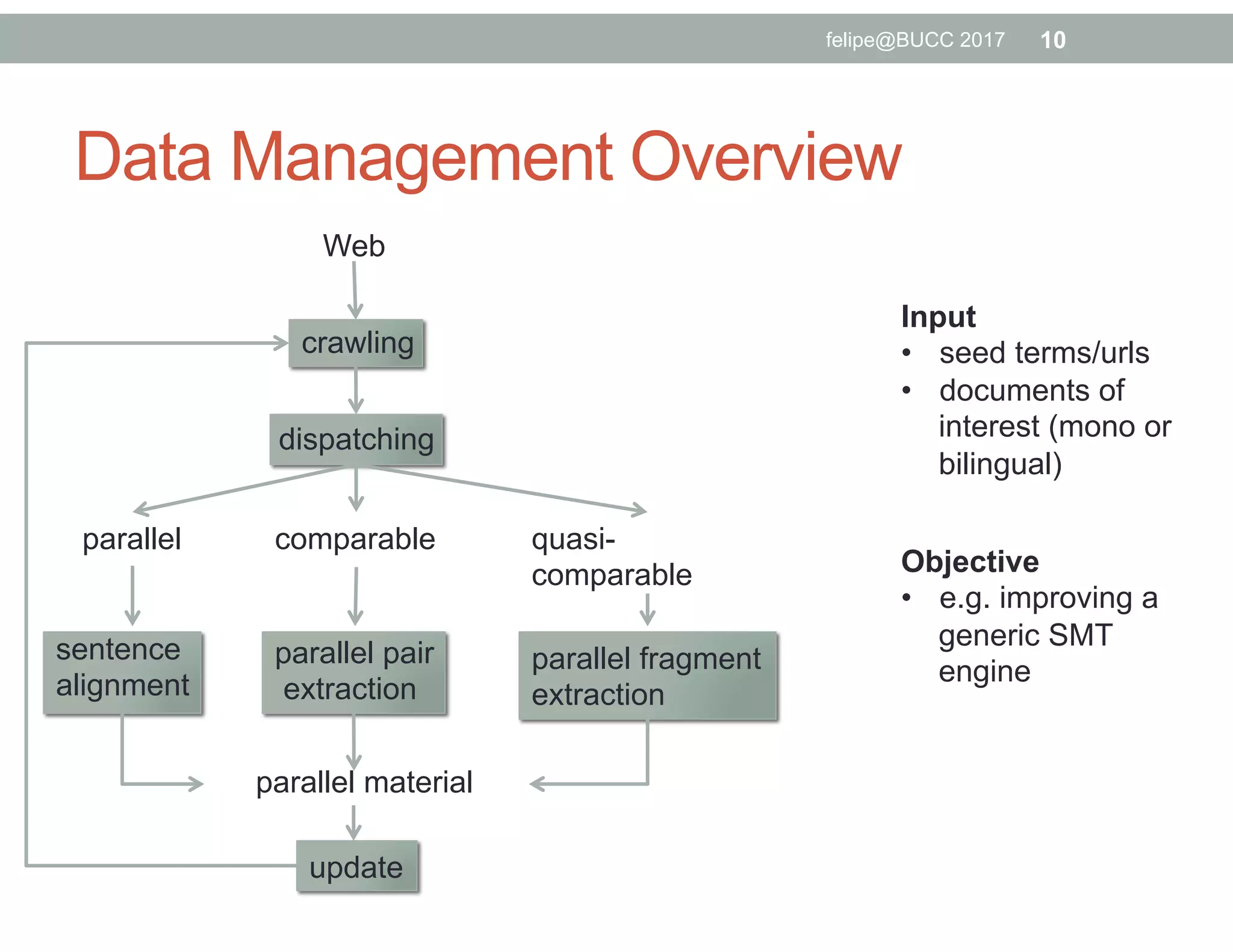







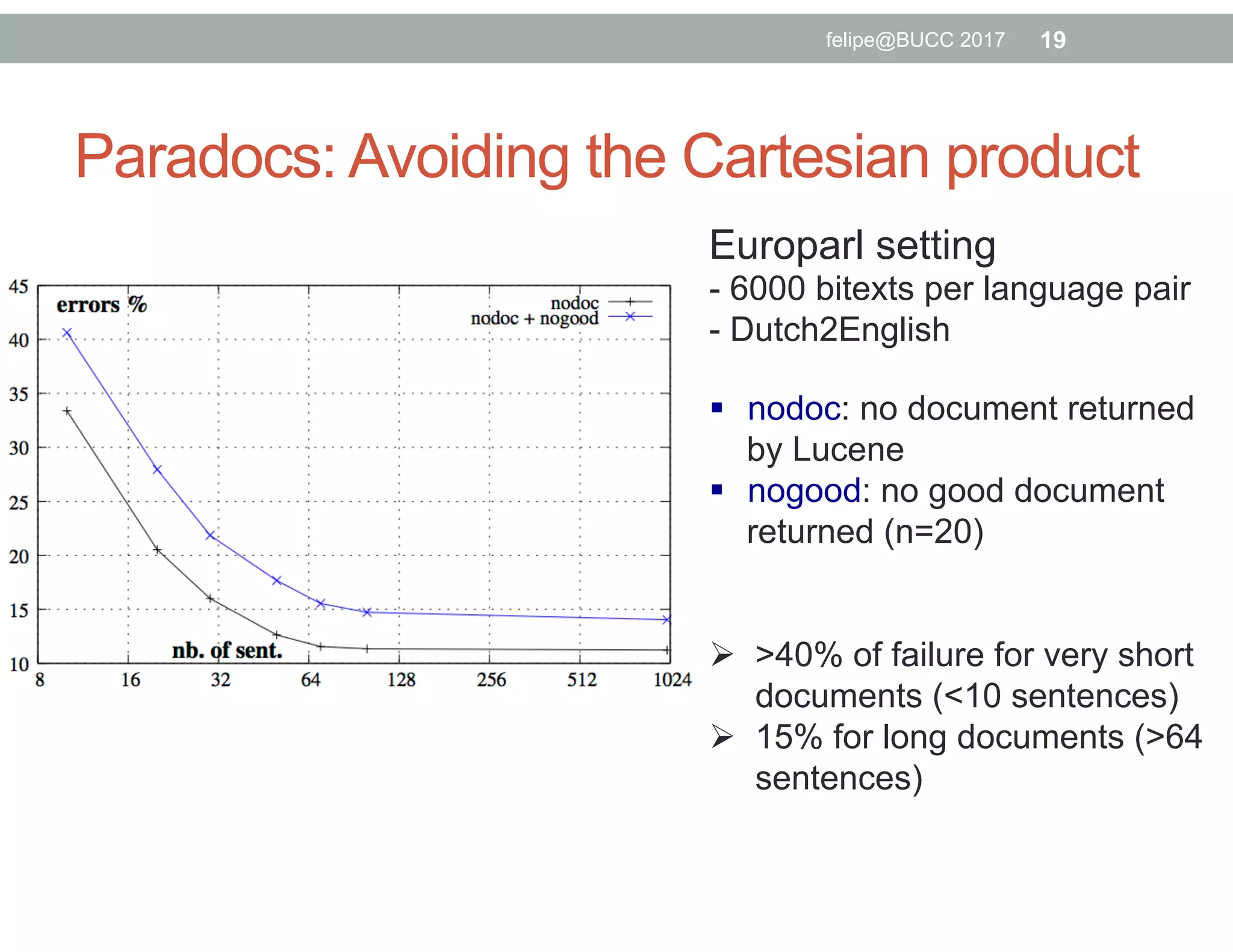



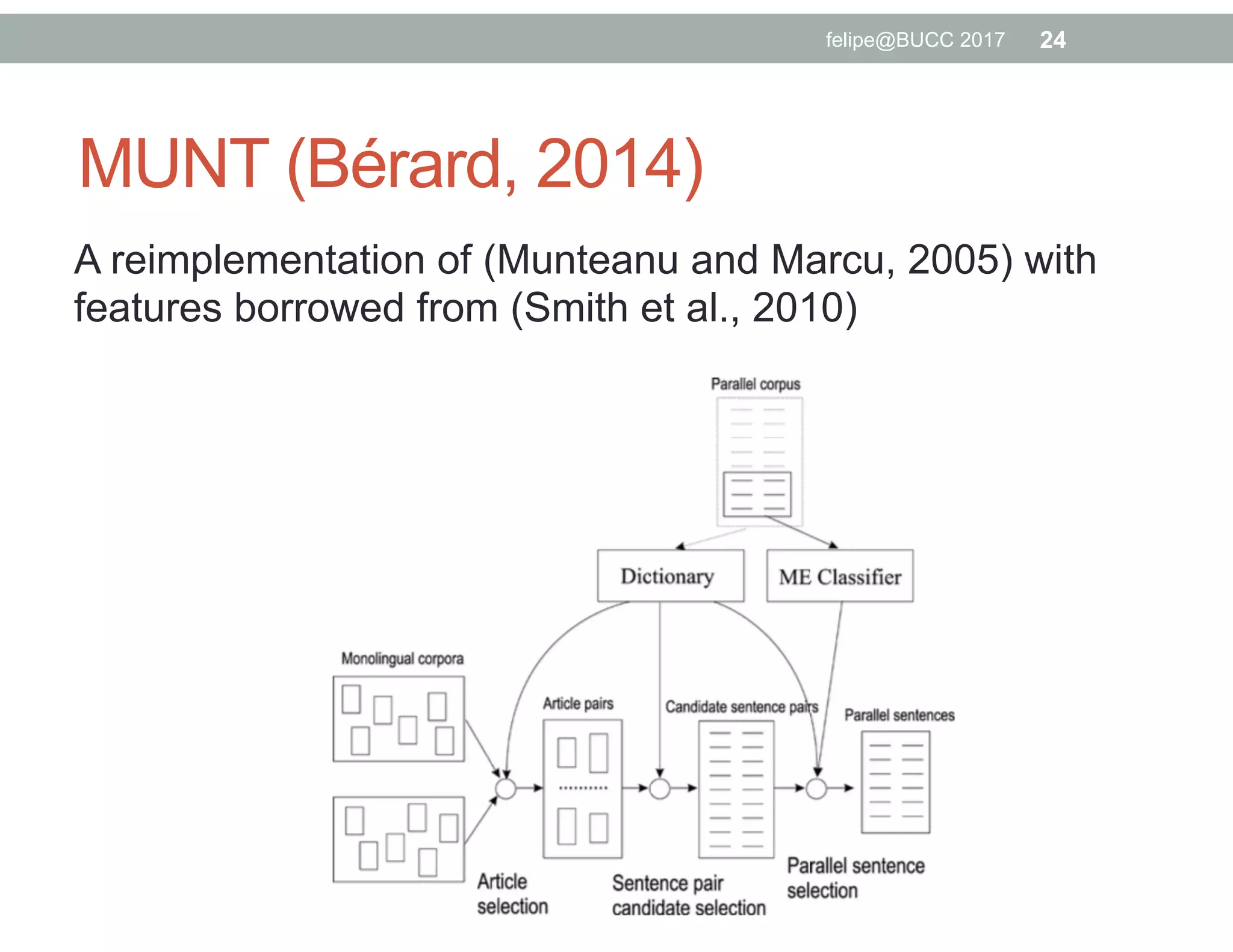




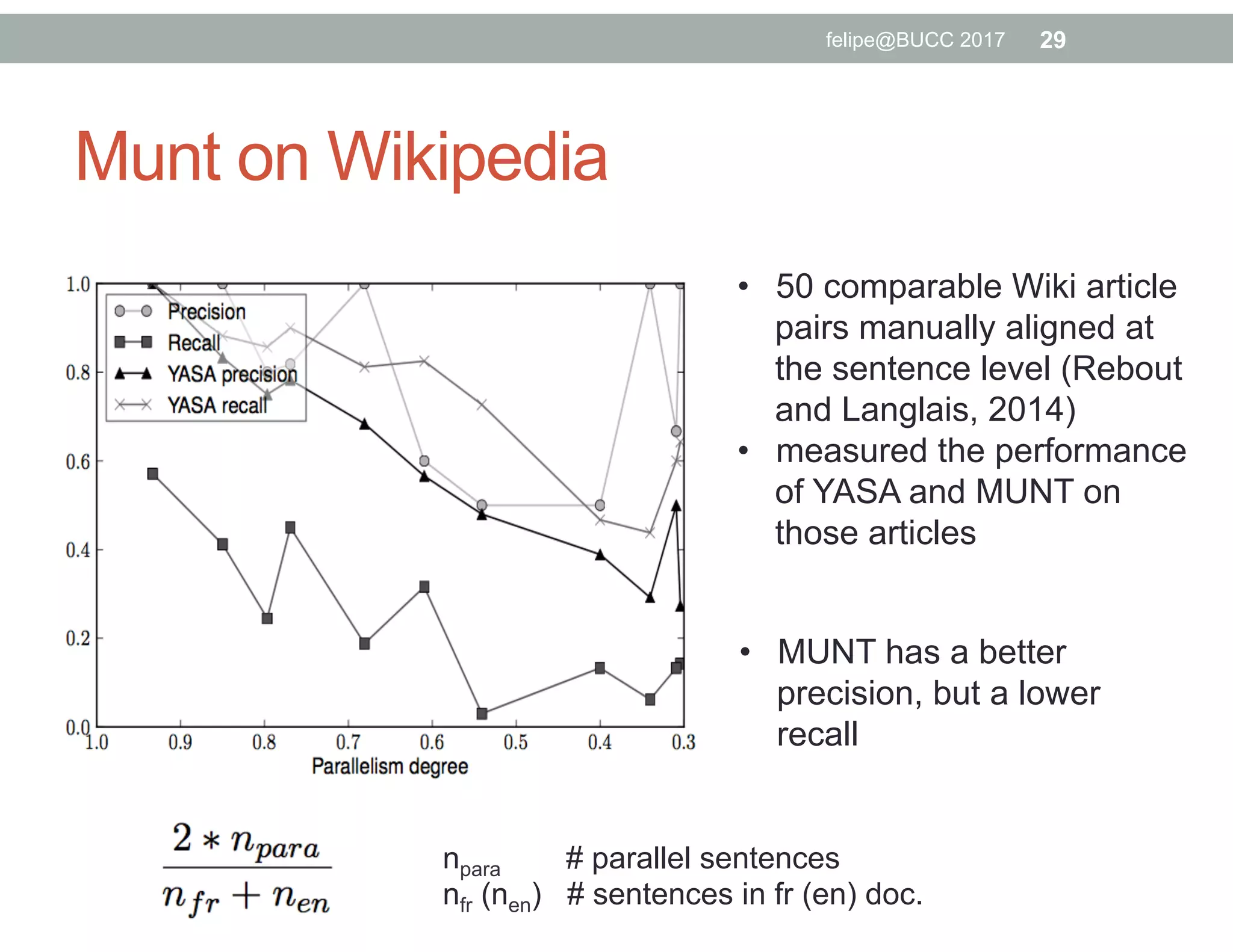




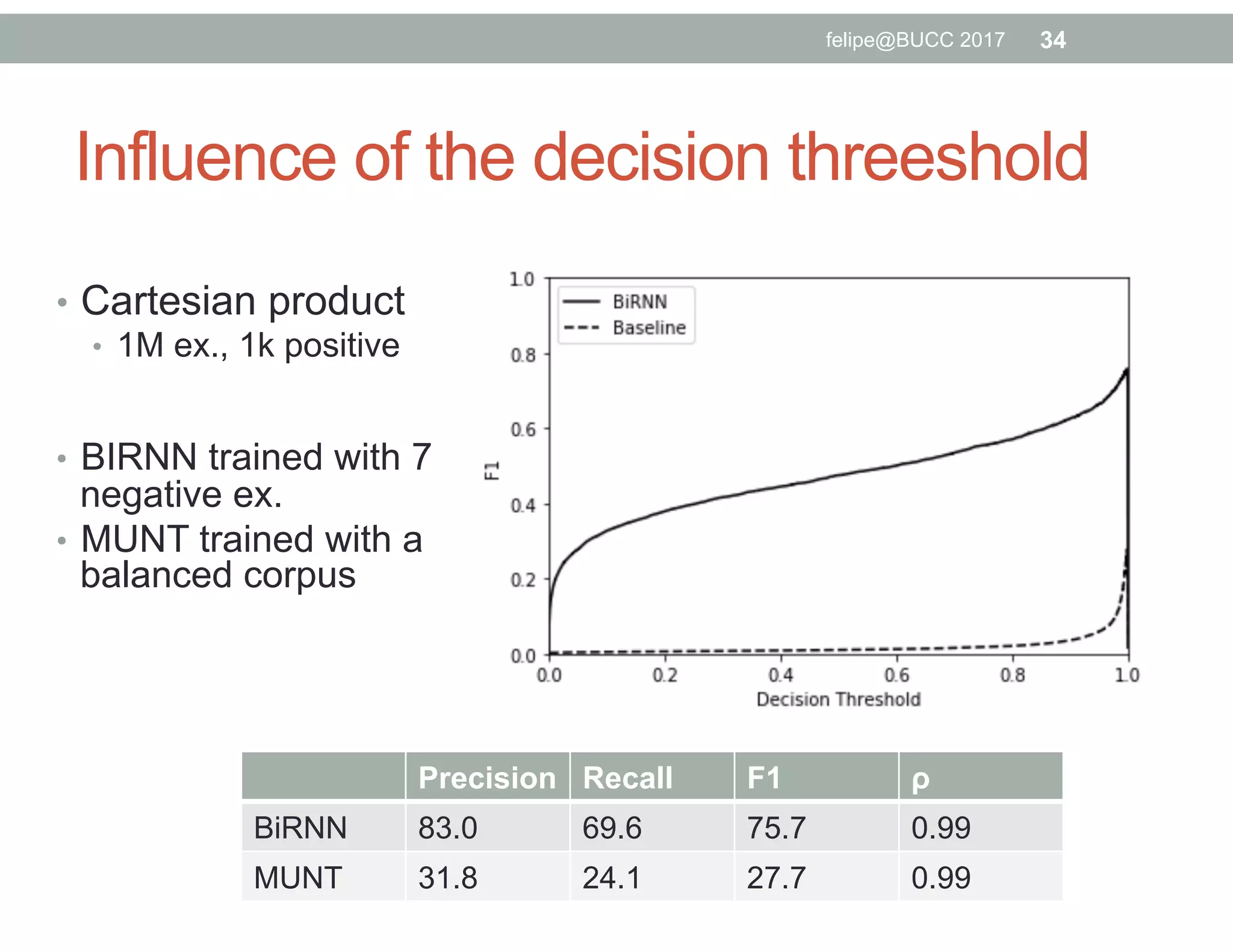
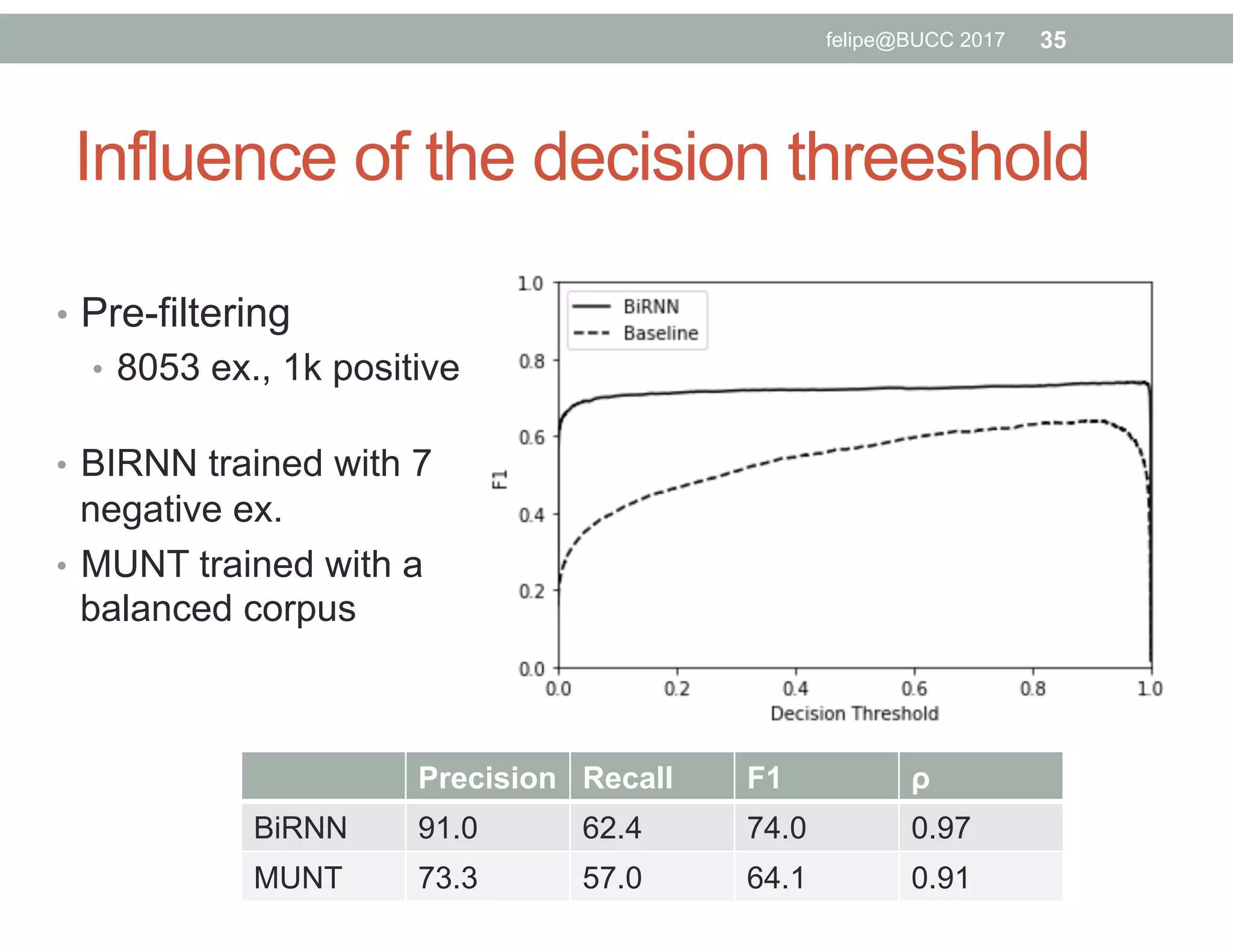
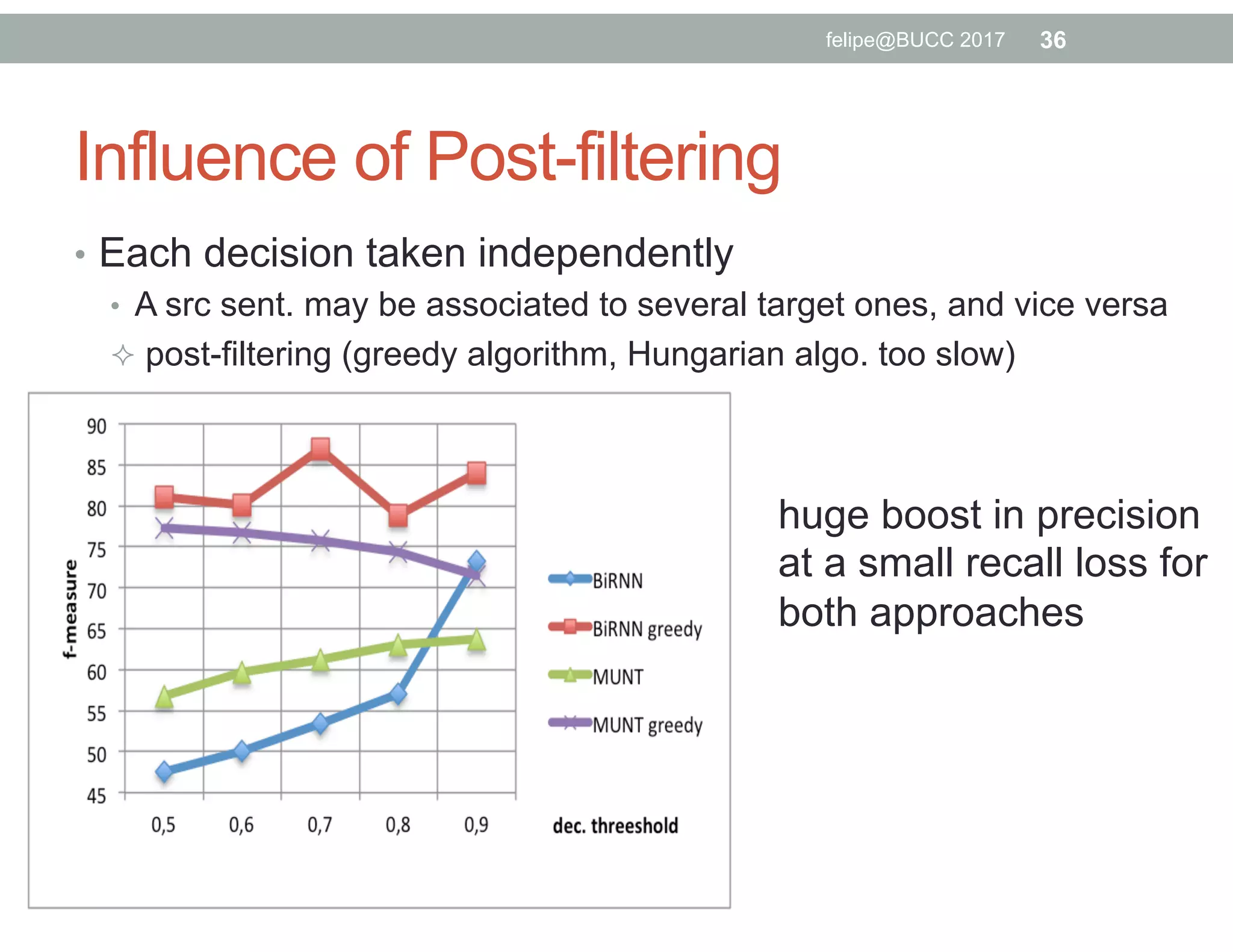




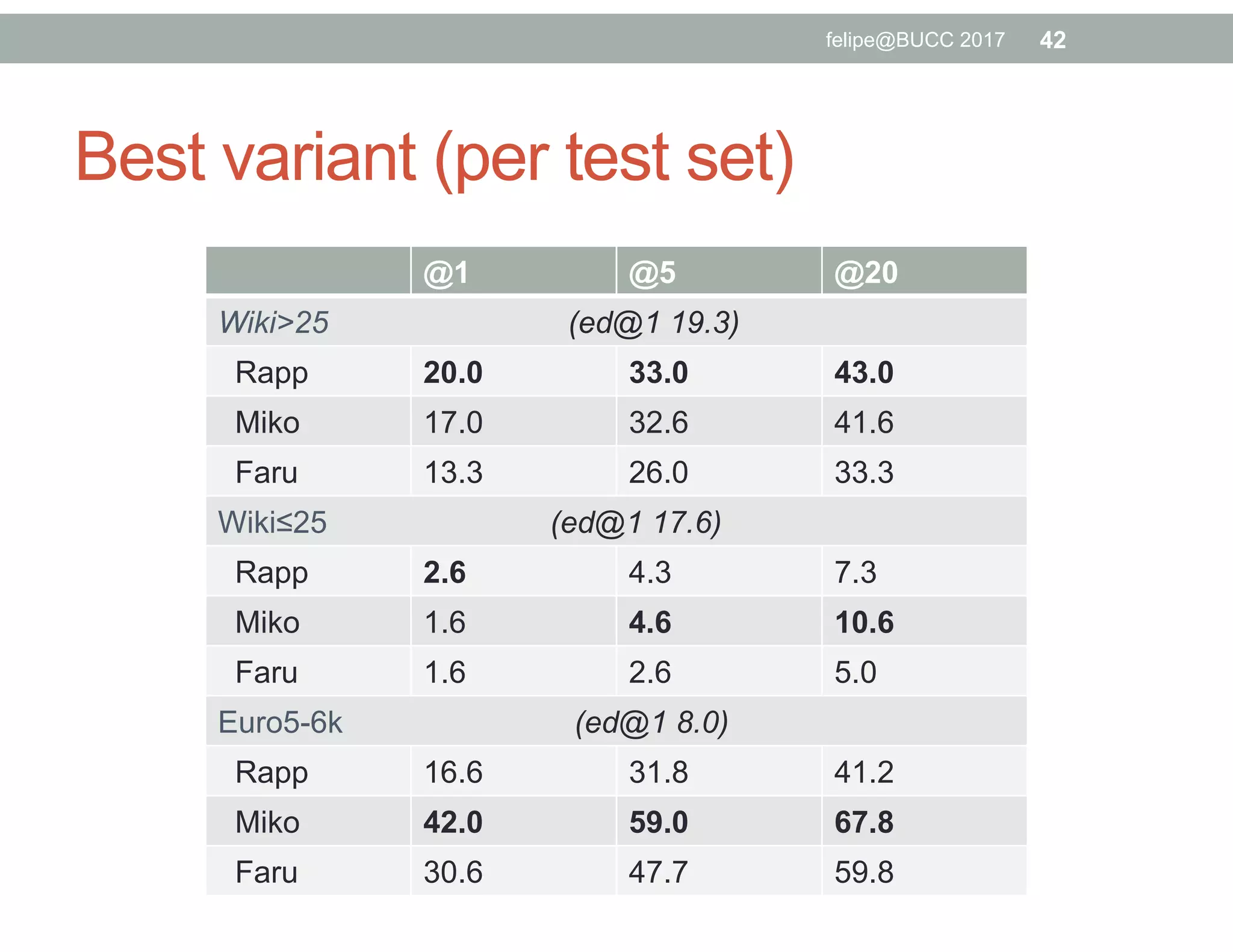

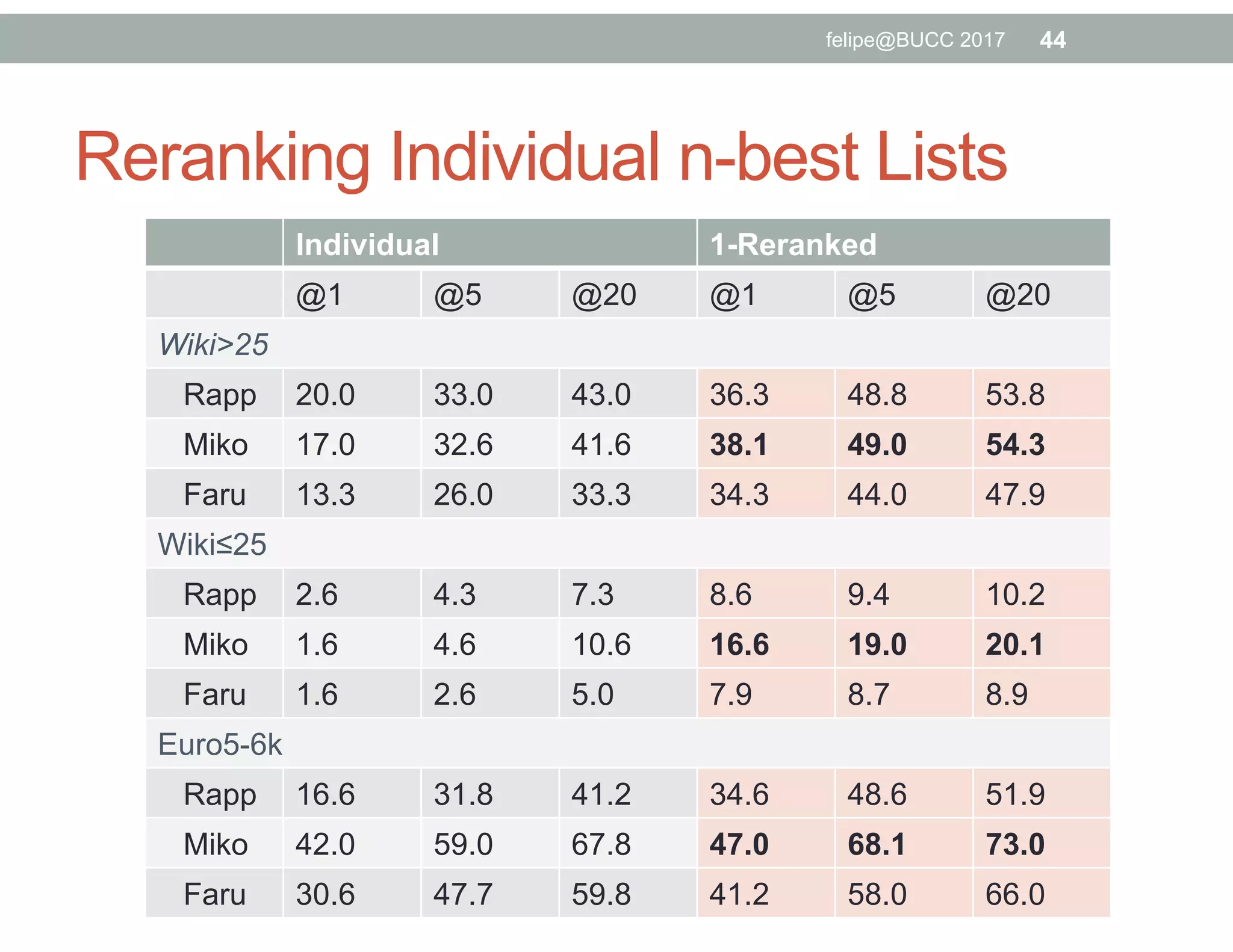
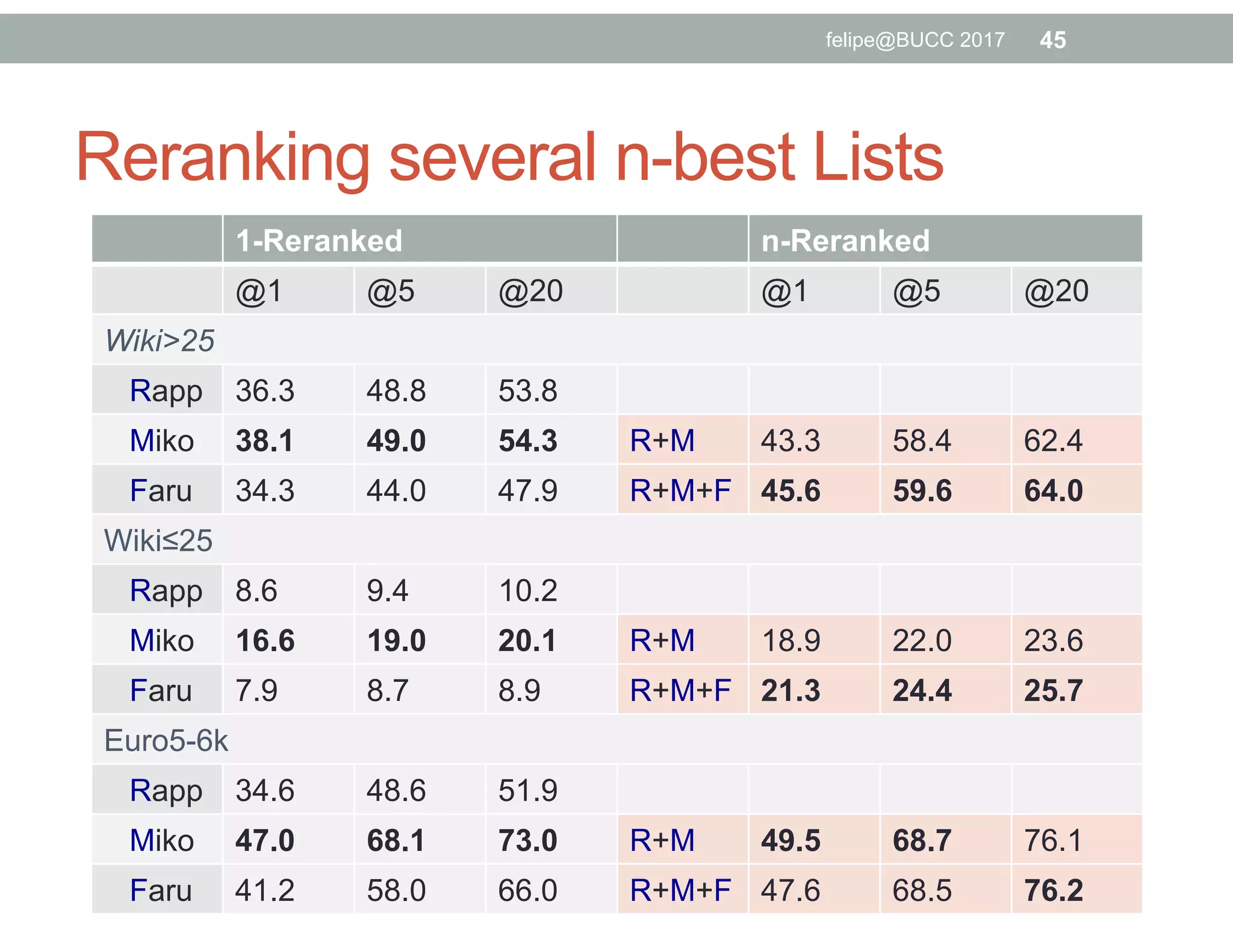


The document discusses various approaches to identifying parallel material in comparable corpora, including identifying parallel documents, sentence pairs, and word pairs. It describes methods such as Paradocs for identifying parallel documents using light document representations and classification. It also discusses the MUNT approach for identifying parallel sentence pairs using alignment-based features and pre-filtering, and evaluates MUNT on Wikipedia data, finding that it identifies a high percentage of parallel and quasi-parallel sentences. Finally, it describes the BUCC 2017 shared task on detecting parallel sentences in Wikipedia data.




































































































