Downloaded 11 times








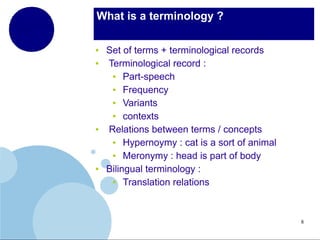


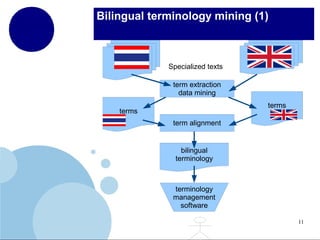
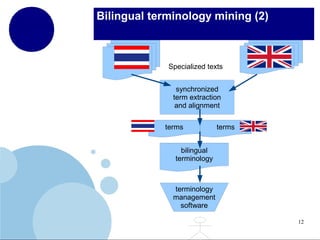


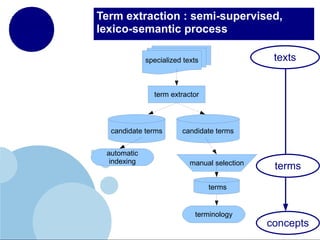


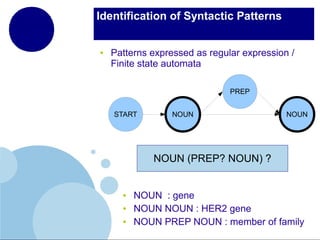







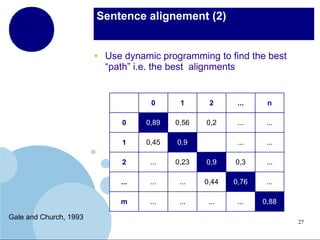











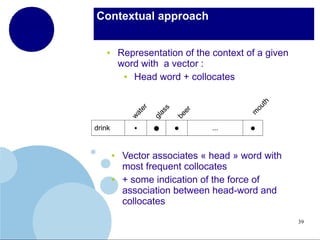




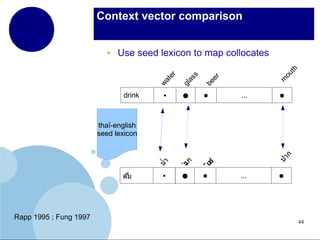


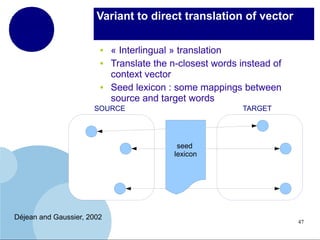
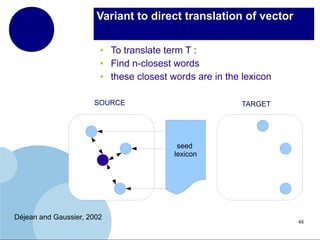
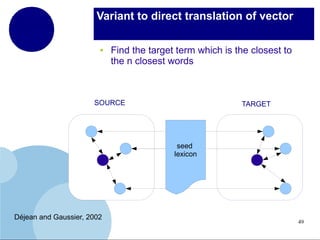
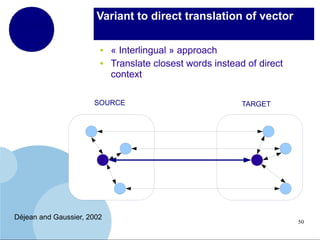
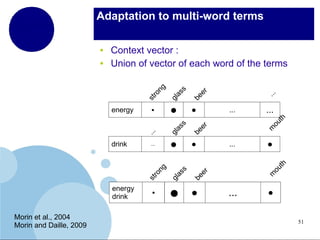




The document presents a comprehensive overview of terminology mining in bilingual contexts, focusing on term extraction and alignment within specialized texts. It discusses the definition of terms, the processes of term extraction, and the use of parallel and comparable corpora for bilingual terminology mining. The methodologies highlighted include semi-supervised processes, context vector approaches, and the challenges encountered, such as polysemy and low-frequency words.

































































































