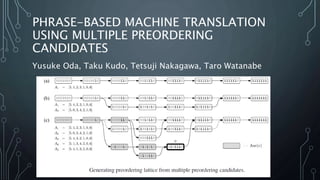
The document summarizes the 26th International Conference on Computational Linguistics (COLING) held in Osaka, Japan in December 2016. Over 1100 presenters attended, with 1039 papers submitted and a 32% acceptance rate. Key areas included neural networks, machine translation, dialog systems, and natural language processing applications. Plenary speakers addressed topics such as universal dependencies in parsing and grounded semantics for hybrid machine translation. The conference featured presentations and posters on recent research advances, including character-level named entity recognition, interactive attention for neural machine translation, and improving attention modeling for machine translation.