Download as PDF, PPTX

















![PCI
• PCI BDF .
– PCI
• 1
• NIC 1
• SR-IOV VF
$ lspci –tv
... snip ... 2 GbE
-[0000:00]-+-00.0 Intel Corporation 5500 I/O Hub to ESI Port
+-01.0-[01]--+-00.0 Broadcom Corporation NetXtreme II BCM5716 Gigabit Ethernet
| -00.1 Broadcom Corporation NetXtreme II BCM5716 Gigabit Ethernet
+-03.0-[05]--
+-07.0-[06]----00.0 Intel Corporation 82599EB 10-Gigabit SFI/SFP+ Network Connect
+-09.0-[03]--
... snip ...
.
19](https://image.slidesharecdn.com/jssst2012-tutorial-takano-120824073031-phpapp02/85/I-O-I-O-19-320.jpg)





















![• Linux
• QEMU/KVM
– QEMU PCI
– libvirt Virt-manager
→
• Open vSwitch 1.6.1
• PCI & SR-IOV
" Intel Gigabit ET dual port server adapter [SR-IOV ]
" Intel Ethernet Converged Network Adapter X520-LR1 [SR-IOV ]
" Mellanox ConnectX-2 QDR Infiniband HCA
Broadcom on board GbE NIC (BMC5709)
Brocade BR1741M-k 10 Gigabit Converged HCA
42](https://image.slidesharecdn.com/jssst2012-tutorial-takano-120824073031-phpapp02/85/I-O-I-O-42-320.jpg)




![SR-IOV VF
• VF
# modprobe –r ixgbe max_vfs VF
# modprobe ixgbe max_vfs=8 • OS VF PCI
$ lspci –tv
... snip ...
-[0000:00]-+-00.0 Intel Corporation 5500 I/O Hub to ESI Port
+-01.0-[01]--+-00.0 Broadcom Corporation NetXtreme II BCM5716 Gigabit Ethernet
Physical Function (PF)
| -00.1 Broadcom Corporation NetXtreme II BCM5716 Gigabit Ethernet
+-03.0-[05]--
+-07.0-[06]----00.0 Intel Corporation 82599EB 10-Gigabit SFI/SFP+ Network Connect
| +-10.0 Intel Corporation 82599 Ethernet Controller Virtual Function
| +-10.2 Intel Corporation 82599 Ethernet Controller Virtual Function
| +-10.4 Intel Corporation 82599 Ethernet Controller Virtual Function
Virtual Function (VF)
| +-10.6 Intel Corporation 82599 Ethernet Controller Virtual Function
| +-11.0 Intel Corporation 82599 Ethernet Controller Virtual Function
| +-11.2 Intel Corporation 82599 Ethernet Controller Virtual Function
| +-11.4 Intel Corporation 82599 Ethernet Controller Virtual Function
| -11.6 Intel Corporation 82599 Ethernet Controller Virtual Function
+-09.0-[03]--
... snip ...
47](https://image.slidesharecdn.com/jssst2012-tutorial-takano-120824073031-phpapp02/85/I-O-I-O-47-320.jpg)

![SR-IOV OS
• OS VF PCI
$ cat /proc/interrupts
CPU0 CPU1
...snip...
29: 114941 114133 PCI-MSI-edge eth1-rx-0
$ lspci
30: 77616 78385 PCI-MSI-edge eth1-tx-0
00:00.0 Host bridge: Intel Corporation 440FX - 82441FX PMC [Natoma] (rev 02)
31: 5 5 PCI-MSI-edge eth1:mbx
00:01.0 ISA bridge: Intel Corporation 82371SB PIIX3 ISA [Natoma/Triton II]
00:01.1 IDE interface: Intel Corporation 82371SB PIIX3 IDE [Natoma/Triton II]
00:01.3 Bridge: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 03)
00:02.0 VGA compatible controller: Cirrus Logic GD 5446
00:03.0 Ethernet controller: Red Hat, Inc Virtio network device
00:04.0 SCSI storage controller: Red Hat, Inc Virtio block device
00:05.0 Ethernet controller: Intel Corporation 82599 Ethernet Controller
Virtual Function (rev 01)
49](https://image.slidesharecdn.com/jssst2012-tutorial-takano-120824073031-phpapp02/85/I-O-I-O-49-320.jpg)















![MPI Point-to-Point
10000
(higher is better) 2.4 GB/s qperf
3.2 GB/s
1000
Bandwidth [MB/sec]
100
PCI KVM
10
Bare Metal
Bare Metal
KVM
1
1 10 100 1k 10k 100k 1M 10M 100M 1G
Message size [byte] Bare Metal:
65](https://image.slidesharecdn.com/jssst2012-tutorial-takano-120824073031-phpapp02/85/I-O-I-O-65-320.jpg)
![NPB BT-MZ:
(higher is better)
300 100
Performance [Gop/s total]
250 Degradation of PE: 80
Parallel efficiency [%]
KVM: 2%, EC2 CCI: 14%
200
Bare Metal 60
150 KVM
Amazon EC2
40
100 Bare Metal (PE)
KVM (PE)
20
50 Amazon EC2 (PE)
0 0
1 2 4 8 16
EC2 Cluster compute Number of nodes
instances (CCI)
66](https://image.slidesharecdn.com/jssst2012-tutorial-takano-120824073031-phpapp02/85/I-O-I-O-66-320.jpg)
![Bloss:
Rank 0 Rank 0 N
MPI OpenMP Bcast
760 MB
Liner Solver
(require 10GB mem.
Reduce
1 GB
coarse-grained MPI comm.
Parallel Efficiency 1 GB
120 Bcast Eigenvector calc.
(higher is better) Gather
100 350 MB
Parallel Efficiency [%]
80
60
Degradation of PE:
40
KVM: 8%, EC2 CCI: 22%
20 Bare Metal
KVM
Amazon EC2
Ideal
0
1 2 4 8 16
Number of nodes 67](https://image.slidesharecdn.com/jssst2012-tutorial-takano-120824073031-phpapp02/85/I-O-I-O-67-320.jpg)









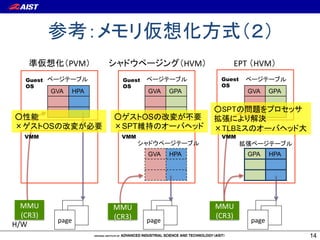
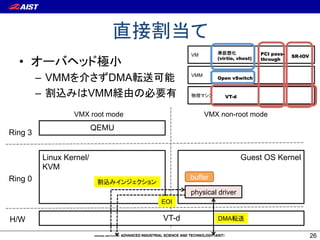
This document discusses different methods for virtualizing I/O in virtual machines. It covers virtual I/O approaches like virtio, PCI passthrough, and SR-IOV. It also explains the role of the VMM/hypervisor in managing I/O between VMs and physical devices using techniques like VT-d, Open vSwitch, and single root I/O virtualization. Finally, it discusses emerging standards for virtual switching like virtual Ethernet bridging.











































































































