Download as PDF, PPTX












![Software Maturily
CloudStack Issue Our action Status
cloudstack-agent jsvc gets too large virtual memory space Patch Fixed
listUsageRecords generates NullPointerExceptions for
expunging instances
Patch Fixed
Duplicate usage records when listing large number of records /
Small page sizes return duplicate results
Backporting Fixed
Public key content is overridden by template's meta data when
you create a instance
Bug report Fixed
Migration of aVM with volumes in local storage to another
host in the same cluster is failing
Backporting Fixed
Negative ref_cnt of template(snapshot/volume)_store_ref
results in out-of-range error in MySQL
Patch (not merged) Fixed
[S3] Parallel deployment makes reference count of a cache in
NFS secondary staging store negative(-1)
Patch (not merged) Unresolved
Can't create proper template fromVM on S3 secondary
storage environment
Patch Fixed
Fails to attach a volume (is made from a snapshot) to aVM
with using local storage as primary storage
Bug report Unresolved](https://image.slidesharecdn.com/isgc2015-150319211546-conversion-gate01/85/AIST-Super-Green-Cloud-lessons-learned-from-the-operation-and-the-performance-evaluation-of-HPC-cloud-17-320.jpg)



![0 5 10 15 20 25 30 35
0
200
400
600
800
1000
Number of nodes
Deploytime[second]
●
●
●
●
●
● no cache
cache on NFS/SS
cache on local node
Virtual Cluster Deployment
Breakdown (second)
Device attach!
(before OS boot)
90
OS boot 90
FS creation (mkfs) 90
transfer from !
RADOS to SS
transfer from SS to !
local node
VM
VM
RADOS
NFS/SS
Compute!
node
VM](https://image.slidesharecdn.com/isgc2015-150319211546-conversion-gate01/85/AIST-Super-Green-Cloud-lessons-learned-from-the-operation-and-the-performance-evaluation-of-HPC-cloud-21-320.jpg)

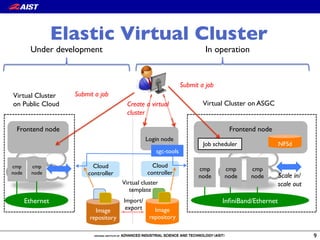
![MPI Point-to-point
communication
23
6.00GB/s
5.72GB/s
5.73GB/s
IMB
Message size [Byte]
Bandwidth[MB/sec]
101
102
103
104
105
10610−1
101
102
103
104
BM
PCI passthrough
SR−IOV
The overhead is less than 5% with large message,
though it is up to 30% with small message.](https://image.slidesharecdn.com/isgc2015-150319211546-conversion-gate01/85/AIST-Super-Green-Cloud-lessons-learned-from-the-operation-and-the-performance-evaluation-of-HPC-cloud-23-320.jpg)
![Message size [Byte]
Executiontime[microsecond]
101
102
103
104
105
106101
102
103
104
105
BM
PCI passthrough
SR−IOV
MPI Collectives
Time [microsecond]
BM 6.87 (1.00)
PCI passthrough 8.07 (1.17)
SR-IOV 9.36 (1.36)
Message size [Byte]
Executiontime[microsecond]
101
102
103
104
105
106101
102
103
104
105
BM
PCI passthrough
SR−IOV
Message size [Byte]
Executiontime[microsecond]
101
102
103
104
105
106101
102
103
104
105
BM
PCI passthrough
SR−IOV
Message size [Byte]
Executiontime[microsecond]
101
102
103
104
105
106101
102
103
104
BM
PCI passthrough
SR−IOV
Message size [Byte]
Executiontime[microsecond]
101
102
103
104
105
106101
102
103
104
BM
PCI passthrough
SR−IOV
ReuceBcast
AllreduceAllgather Alltoall
The performance of SR-IOV is comparable to
that of PCI passthrough while unexpected
performance degradation is often observed
Barrier](https://image.slidesharecdn.com/isgc2015-150319211546-conversion-gate01/85/AIST-Super-Green-Cloud-lessons-learned-from-the-operation-and-the-performance-evaluation-of-HPC-cloud-24-320.jpg)
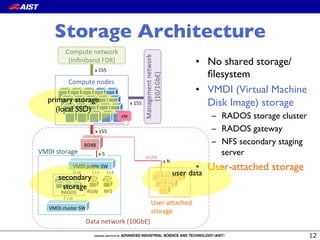
![LAMMPS: MD simulator
• EAM benchmark:
– Fixed problem size (1M
atoms)
– #proc: 20 - 160
• VCPU pinning reduces
performance fluctuation.
• Performance overhead
of PCI passthrough and
SR-IOV is about 13 %.
20 40 60 80 100 120 140 160
0
10
20
30
40
50
60
Number of processes
Executiontime[second]
●
●
●
●
●
● BM
PCI passthrough
PCI passthrough w/ vCPU pin
SR−IOV
SR−IOV w/ vCPU pin](https://image.slidesharecdn.com/isgc2015-150319211546-conversion-gate01/85/AIST-Super-Green-Cloud-lessons-learned-from-the-operation-and-the-performance-evaluation-of-HPC-cloud-25-320.jpg)





This document discusses lessons learned from operating the AIST Super Green Cloud (ASGC), a fully virtualized high-performance computing (HPC) cloud system. It summarizes key findings from the first six months of operation, including performance evaluations of SR-IOV virtualization and HPC applications. It also outlines conclusions and future work, such as improving data movement efficiency across hybrid cloud environments.





































































































