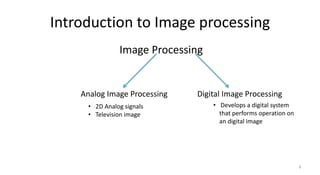
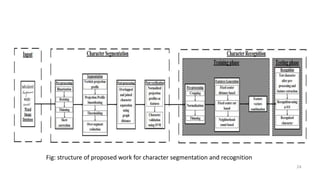
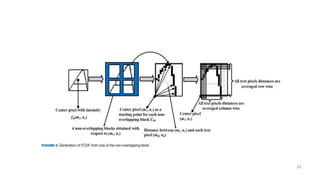
The document provides an overview of image processing and pattern recognition, detailing concepts, applications, and specific research papers. It discusses the goals of image processing, such as enhancing images and enabling machine vision, and outlines the discipline of pattern recognition focused on classifying objects. Two research papers are summarized, one on feature selection for handwritten character recognition and another on character segmentation and recognition algorithms for Indian document images, both showcasing the evolution of techniques and their effectiveness in various scenarios.