Download as PDF, PPTX





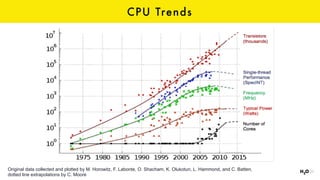


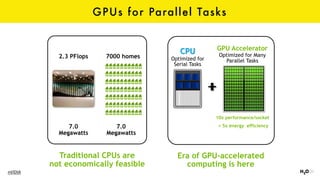
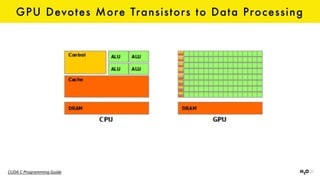


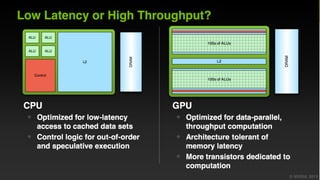




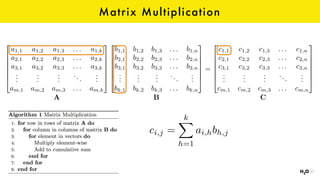


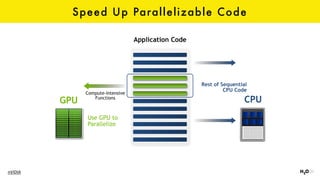

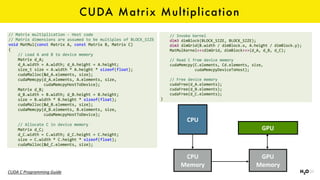
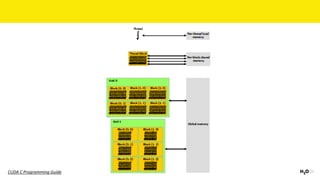
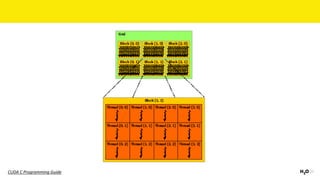



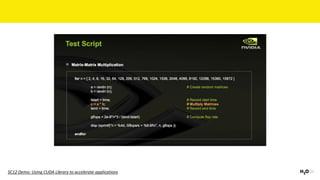

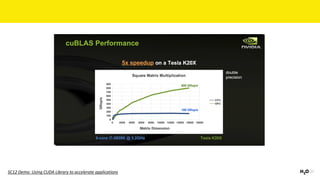



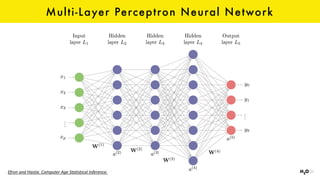

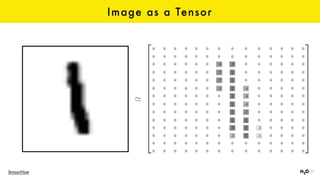
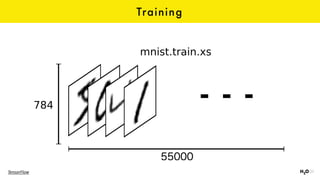
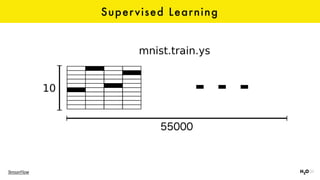
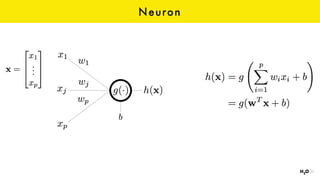
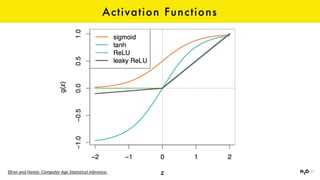
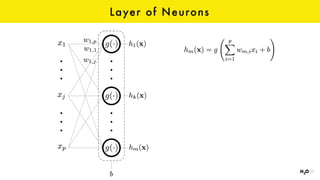
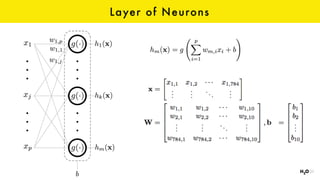
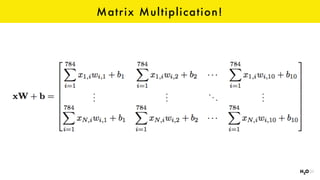
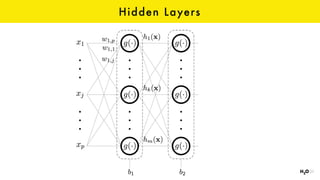



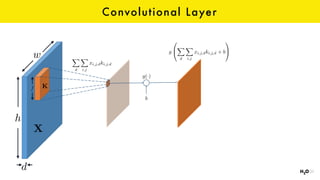
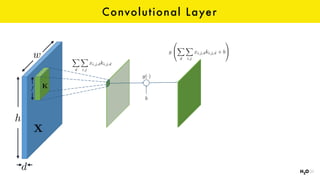

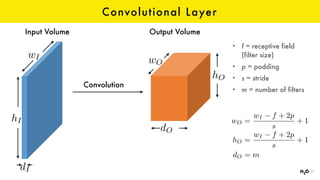



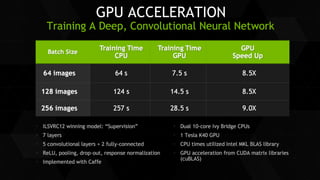

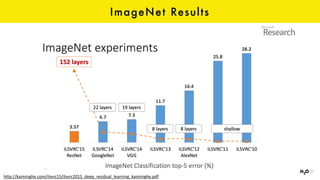
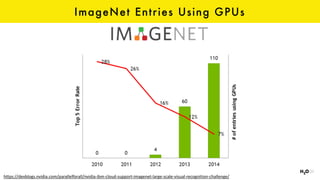
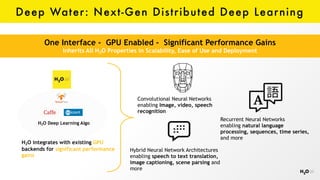

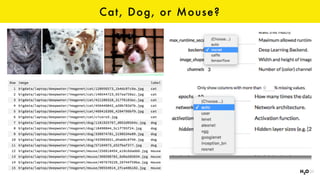


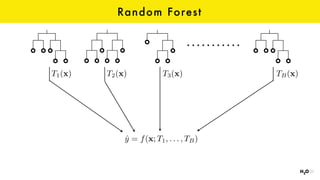
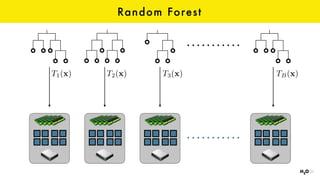
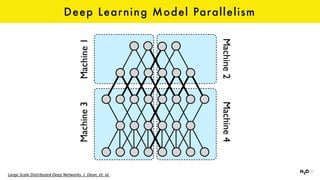

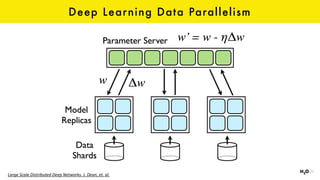
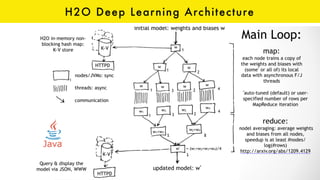
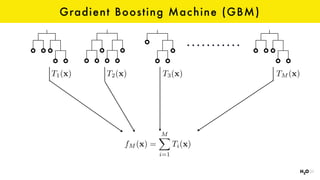
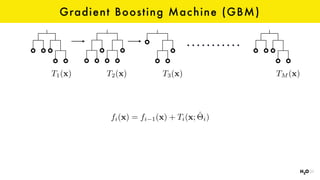
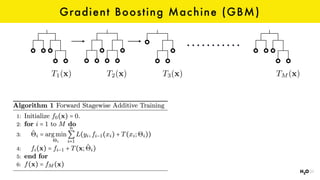
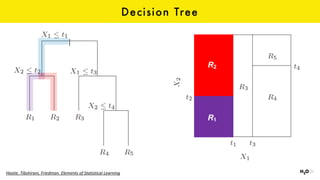
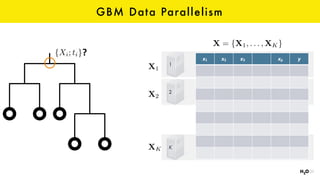
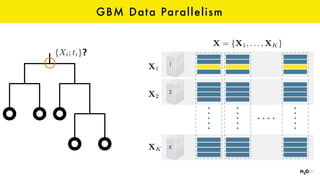
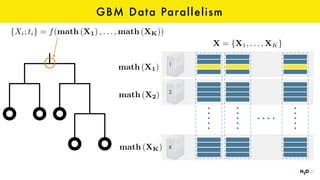
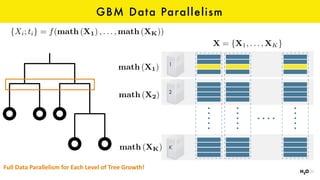
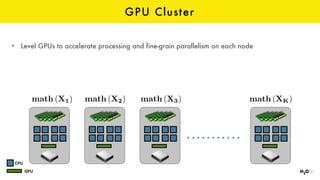
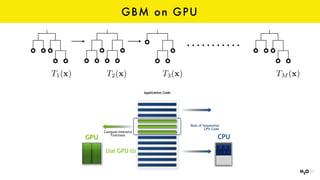

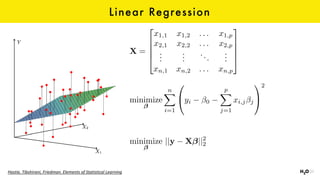
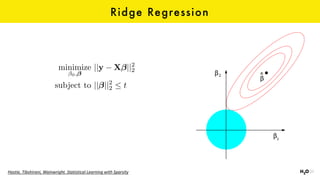
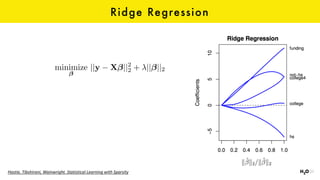
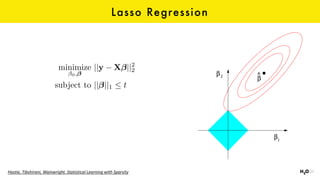
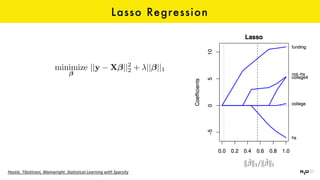









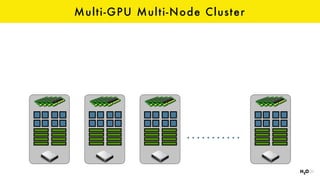
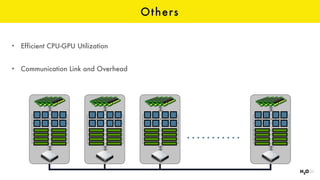

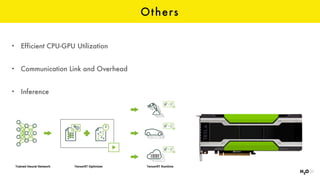



The document discusses the role of GPUs in machine learning, highlighting their efficiency over traditional CPUs for parallel tasks, particularly in deep learning applications. It introduces CUDA as a programming model for leveraging GPU capabilities and explores various computing paradigms such as model and data parallelism. The advantages of GPU-accelerated computing are presented alongside the impacts on machine learning methods like convolutional neural networks and gradient boosting machines.













![[TGDF 2019] Mali GPU Architecture and Mobile Studio](https://cdn.slidesharecdn.com/ss_thumbnails/tgdfgpuarchitecturemobilestudio-190717043007-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[db analytics showcase Sapporo 2018] B33 H2O4GPU and GoAI: harnessing the pow...](https://cdn.slidesharecdn.com/ss_thumbnails/dbassapporo2018b33-180627021956-thumbnail.jpg?width=640&height=640&fit=bounds)













































