Download as PDF, PPTX






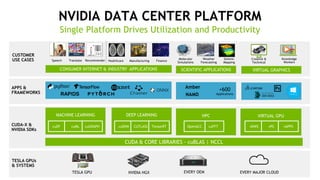




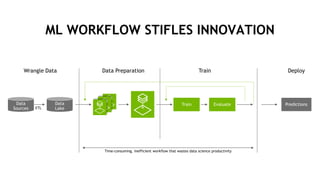
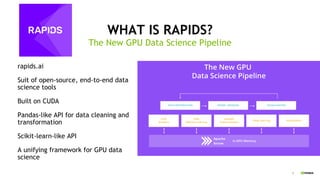
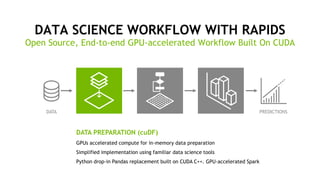
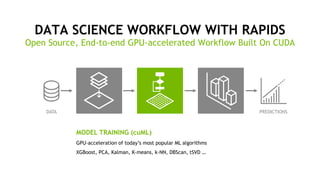
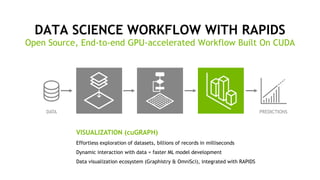
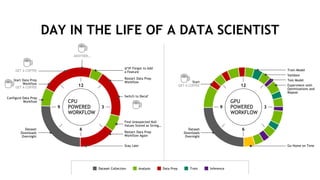


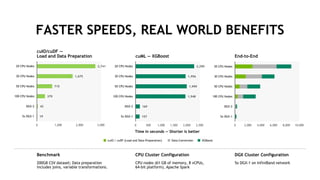



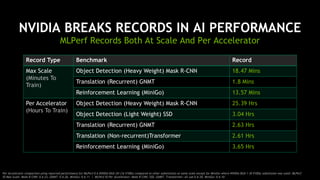
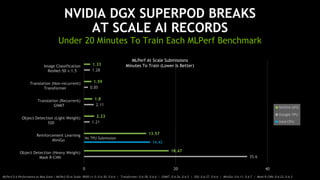
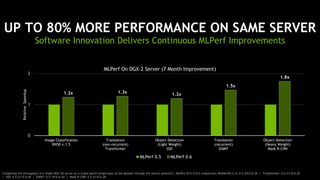




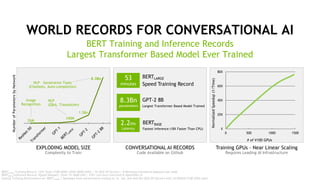

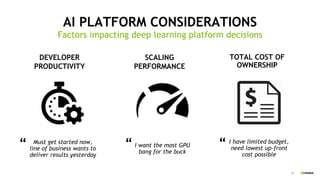
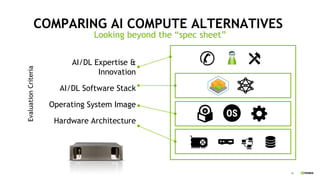
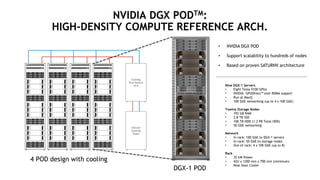

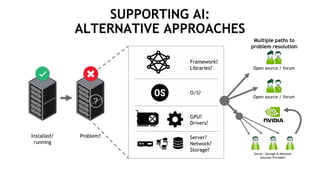
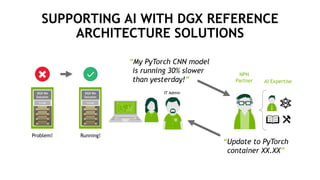
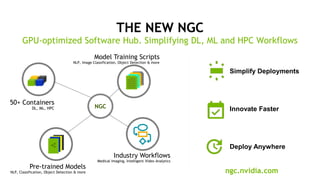


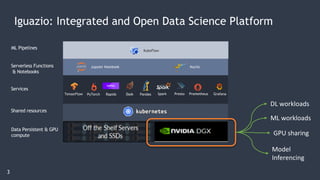



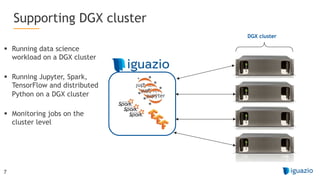
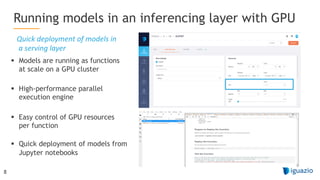
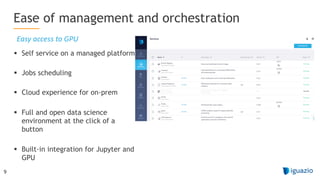
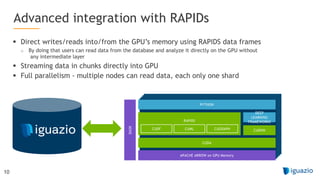
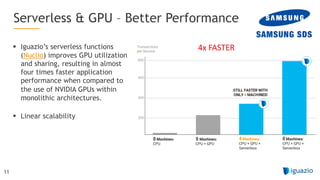
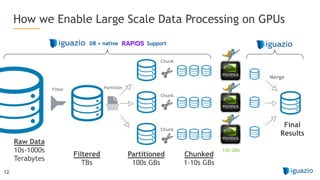

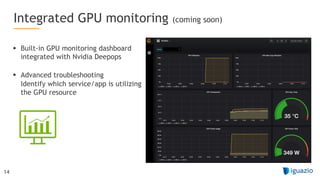


The document outlines a comprehensive agenda for a session on accelerating data science using GPUs, featuring presentations from NVIDIA and Iguazio experts on deep learning, machine learning, and GPU-accelerated data science solutions. It discusses the benefits of the RAPIDS open-source library for data preparation, model training, and visualization, highlighting its transformative impact across various industries including healthcare and finance. Additionally, it presents NVIDIA's advanced GPU technologies and their record-breaking performance in machine learning benchmarks.














































































