Downloaded 14 times








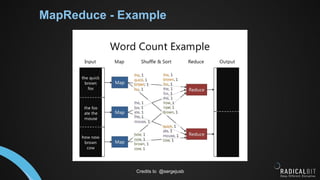


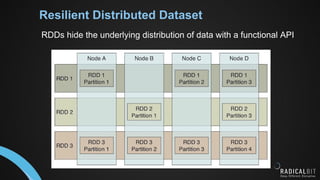
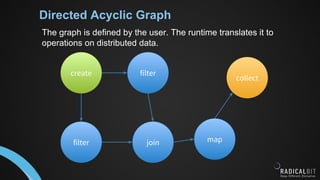






This document provides an introduction to distributed computing engines for data processing. It discusses what distributed computing systems are and how they address the problem of data and tasks being too large for a single machine. It then covers key distributed computing systems like Hadoop, Spark and Flink. For each system, it summarizes what it is, when and where it originated, why it was created, and how it works at a high level. It also provides brief examples of common use cases for each system today.











































































































