Download to read offline












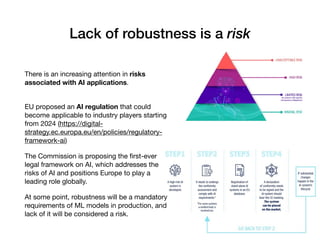


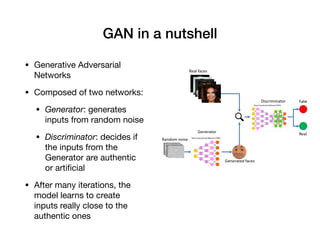







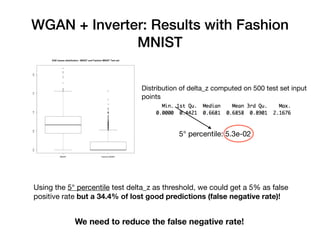

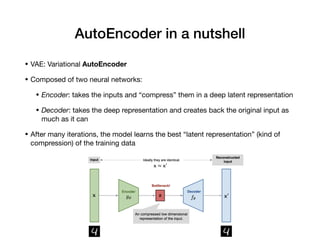
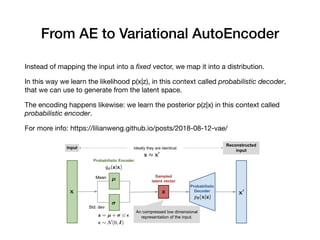


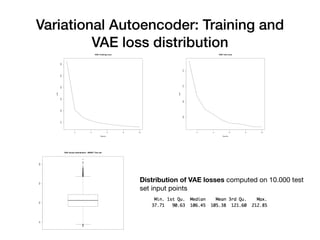

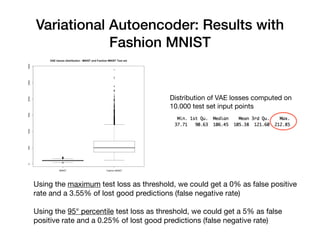





Davide Posillipo's presentation at the Milan AI meetup focused on robustness metrics for deep learning models, highlighting the need for reliable predictions in critical applications. He discussed two approaches for assessing model robustness: a GAN-based method that evaluates prediction stability and a variational autoencoder (VAE) that measures encoding-decoding loss to determine if new input data comes from the same distribution as the training set. The presentation emphasized that implementing effective robustness metrics will be essential for compliance with upcoming AI regulations in the EU.



































































