Downloaded 14 times







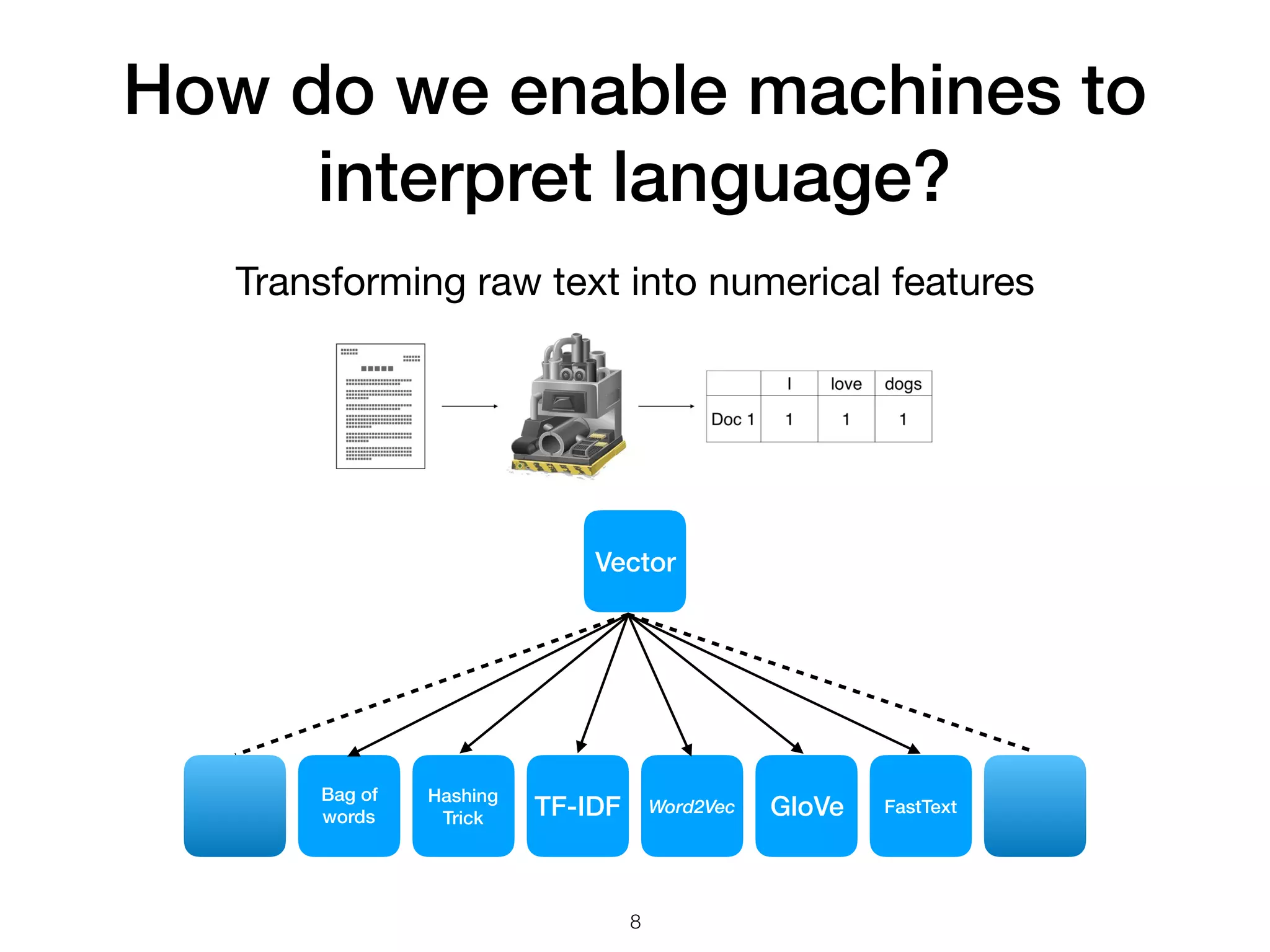

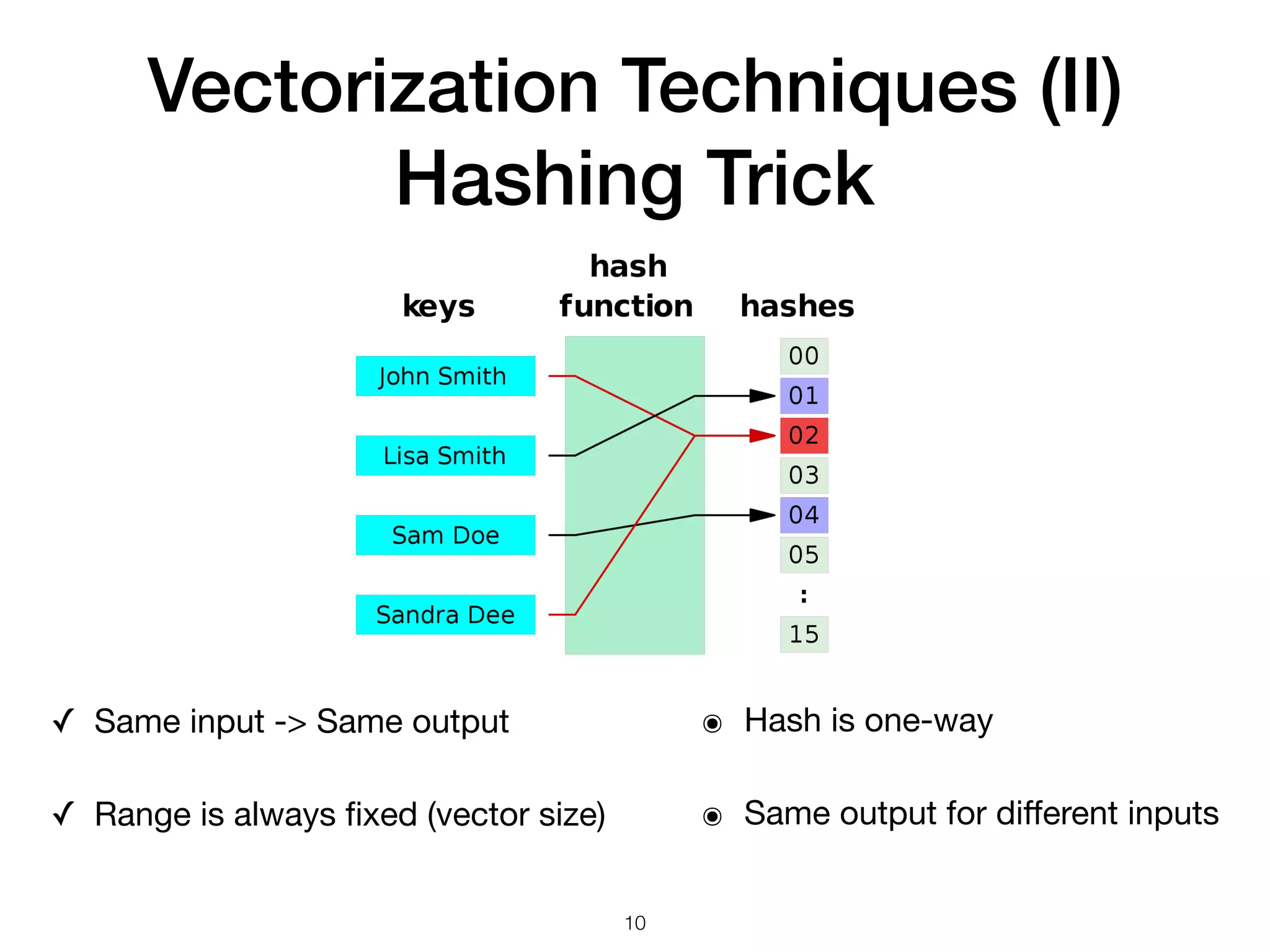


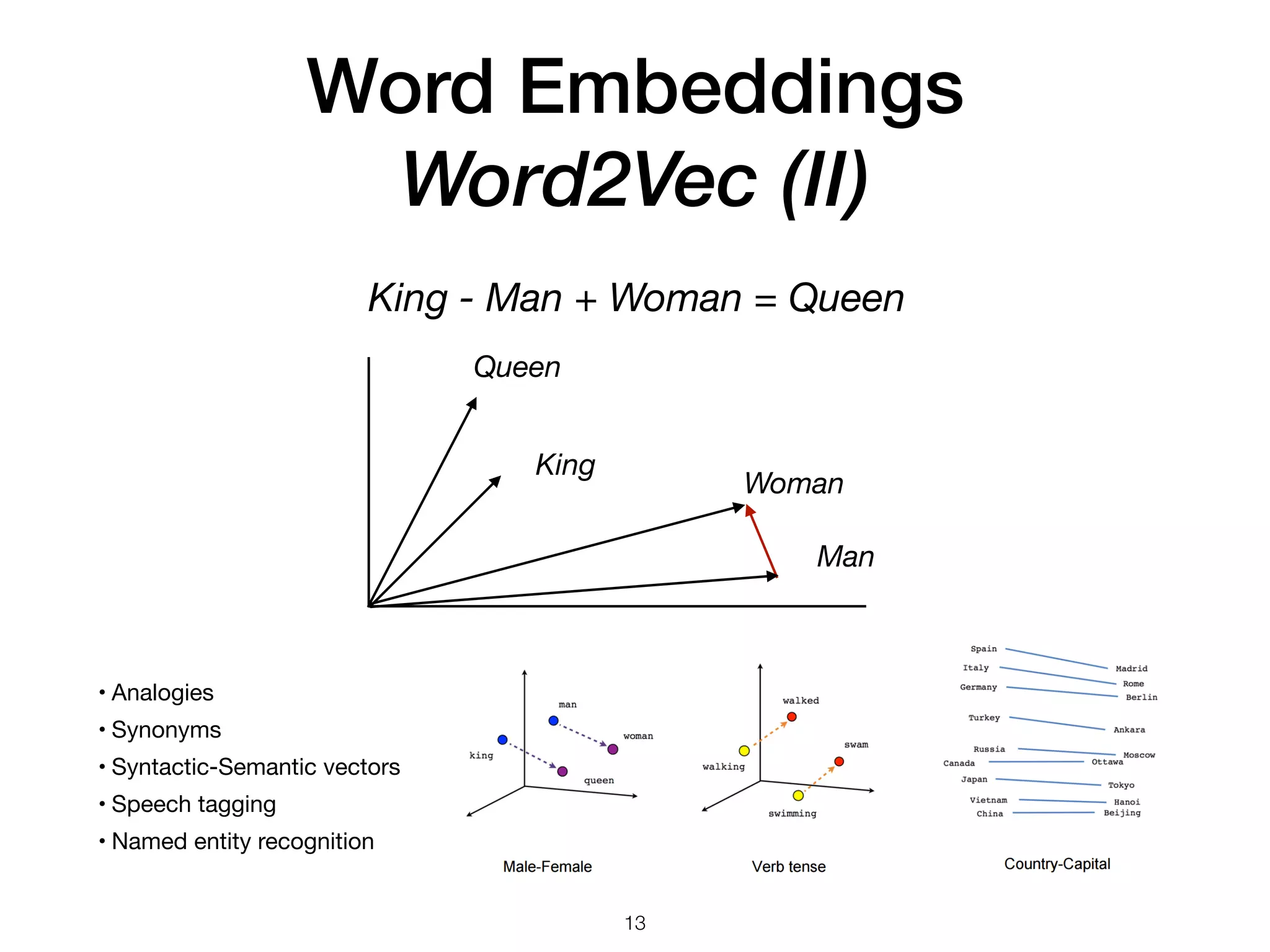
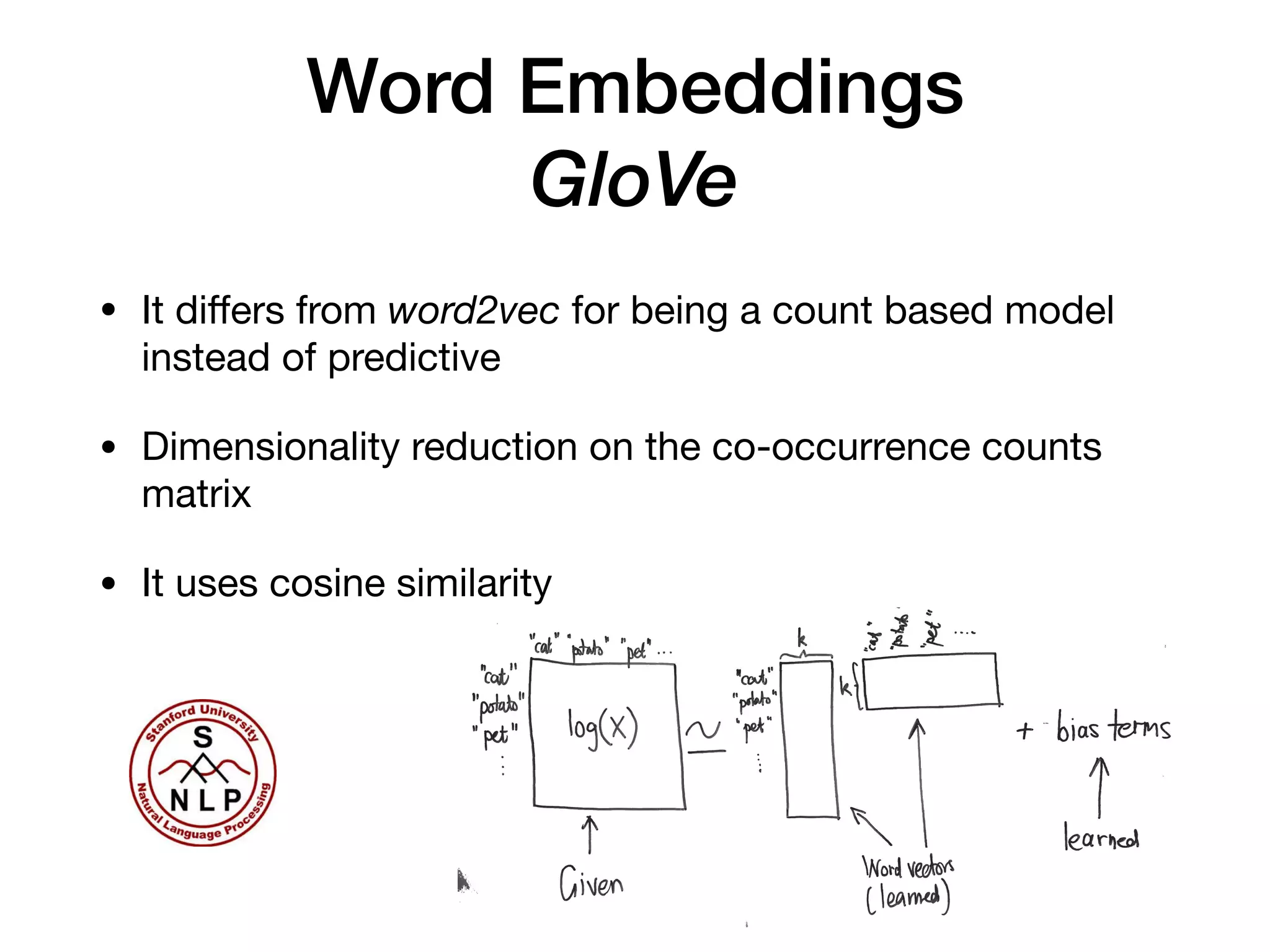


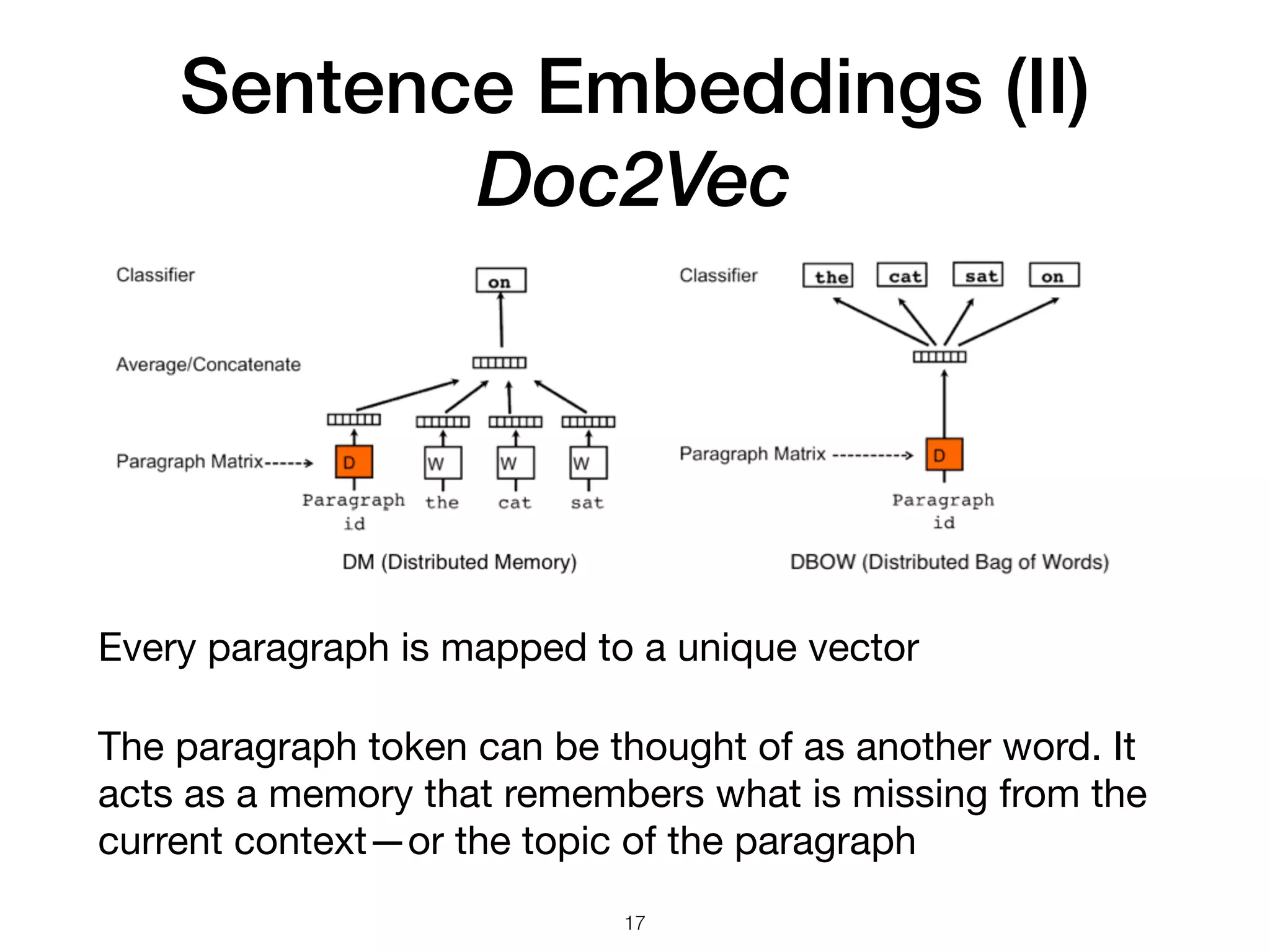

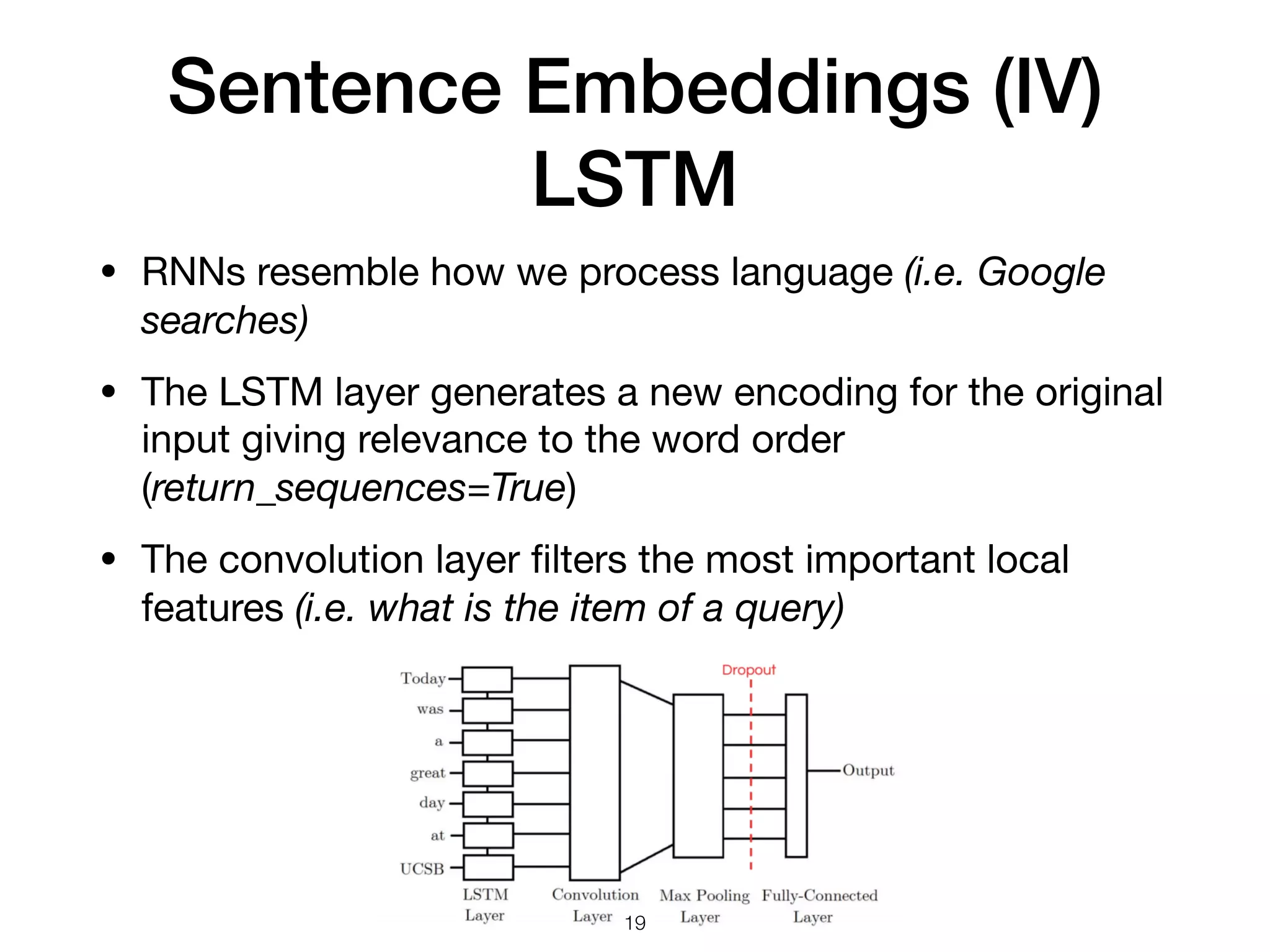



The document discusses natural language processing (NLP), its techniques, and applications such as machine translation and sentiment analysis. It covers vectorization methods including bag of words, tf-idf, and various word embeddings like Word2Vec and GloVe. The presentation concludes with lessons learned in NLP research and experimentation strategies for improving text representation.











































































