Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Gruter
1,206 views
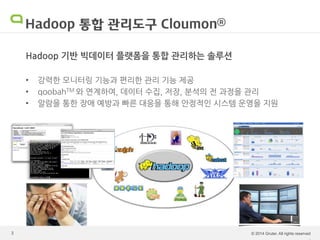
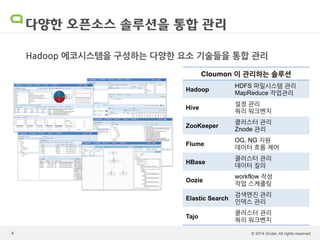
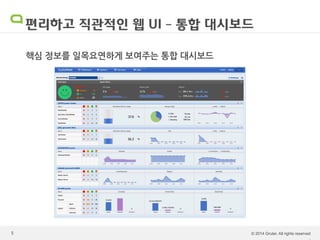
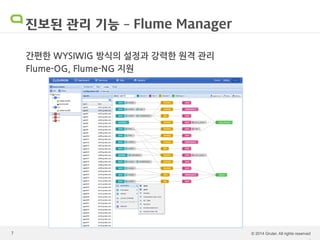
Cloumon sw제품설명회 발표자료
Cloumon Enterprise - Hadoop monitoring & management solution by Gruter
Software
◦
Read more
7
Save
Share
Embed
Embed presentation
1
/ 14
2
/ 14
3
/ 14
4
/ 14
5
/ 14
6
/ 14
7
/ 14
8
/ 14
9
/ 14
10
/ 14
11
/ 14
12
/ 14
13
/ 14
14
/ 14
More Related Content
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: SNS 서비스 아키텍쳐 구축 사례
by
Gruter
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: Tajo와 SQL-on-Hadoop
by
Gruter
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: Bioinformatics Data를 위한 Hadoop기반...
by
Gruter
PDF
[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안
by
치완 박
PPTX
Io t에서 big data를 통합하는 통합 빅데이터 플랫폼 flamingo_클라우다인_김병곤 대표이사
by
uEngine Solutions
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: 온라인 컨텐츠 서비스를 위한 빅데이터 구축 사례
by
Gruter
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: 인터넷 쇼핑몰의 실시간 분석 플랫폼 구축 사례
by
Gruter
PPTX
DeView2013 Big Data Platform Architecture with Hadoop - Hyeong-jun Kim
by
Gruter
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: SNS 서비스 아키텍쳐 구축 사례
by
Gruter
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: Tajo와 SQL-on-Hadoop
by
Gruter
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: Bioinformatics Data를 위한 Hadoop기반...
by
Gruter
[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안
by
치완 박
Io t에서 big data를 통합하는 통합 빅데이터 플랫폼 flamingo_클라우다인_김병곤 대표이사
by
uEngine Solutions
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: 온라인 컨텐츠 서비스를 위한 빅데이터 구축 사례
by
Gruter
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: 인터넷 쇼핑몰의 실시간 분석 플랫폼 구축 사례
by
Gruter
DeView2013 Big Data Platform Architecture with Hadoop - Hyeong-jun Kim
by
Gruter
Similar to Cloumon sw제품설명회 발표자료
PDF
Flamingo project v4
by
BYOUNG GON KIM
PDF
OpenSource Big Data Platform : Flamingo Project
by
BYOUNG GON KIM
PDF
OpenSource Big Data Platform - Flamingo 소개와 활용
by
BYOUNG GON KIM
PDF
OpenSource Big Data Platform - Flamingo v7
by
BYOUNG GON KIM
PPTX
[경북] I'mcloud information
by
startupkorea
PDF
하둡 알아보기(Learn about Hadoop basic), NetApp FAS NFS Connector for Hadoop
by
SeungYong Baek
PDF
빅데이터 기술 현황과 시장 전망(2014)
by
Channy Yun
PPTX
An introduction to hadoop
by
MinJae Kang
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: GRUTER의 빅데이터 플랫폼 및 전략 소개
by
Gruter
PDF
빅데이터, big data
by
H K Yoon
PPTX
Apache spark 소개 및 실습
by
동현 강
PDF
201210 그루터 빅데이터_플랫폼_아키텍쳐_및_솔루션_소개
by
Gruter
PDF
서울 하둡 사용자 모임 발표자료
by
Teddy Choi
PDF
SQL-on-Hadoop 그리고 Tajo - Tech Planet 2013
by
Hyunsik Choi
PPTX
Big data application architecture 요약2
by
Seong-Bok Lee
KEY
Distributed Programming Framework, hadoop
by
LGU+
PPT
Hadoop Introduction (1.0)
by
Keeyong Han
PDF
고성능 빅데이터 수집 및 분석 솔루션 - 티맥스소프트 허승재 팀장
by
eungjin cho
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: 보안 로그 분석을 위한 빅데이터 시스템 구축 사례
by
Gruter
PPTX
Hadoop administration
by
Ryan Guhnguk Ahn
Flamingo project v4
by
BYOUNG GON KIM
OpenSource Big Data Platform : Flamingo Project
by
BYOUNG GON KIM
OpenSource Big Data Platform - Flamingo 소개와 활용
by
BYOUNG GON KIM
OpenSource Big Data Platform - Flamingo v7
by
BYOUNG GON KIM
[경북] I'mcloud information
by
startupkorea
하둡 알아보기(Learn about Hadoop basic), NetApp FAS NFS Connector for Hadoop
by
SeungYong Baek
빅데이터 기술 현황과 시장 전망(2014)
by
Channy Yun
An introduction to hadoop
by
MinJae Kang
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: GRUTER의 빅데이터 플랫폼 및 전략 소개
by
Gruter
빅데이터, big data
by
H K Yoon
Apache spark 소개 및 실습
by
동현 강
201210 그루터 빅데이터_플랫폼_아키텍쳐_및_솔루션_소개
by
Gruter
서울 하둡 사용자 모임 발표자료
by
Teddy Choi
SQL-on-Hadoop 그리고 Tajo - Tech Planet 2013
by
Hyunsik Choi
Big data application architecture 요약2
by
Seong-Bok Lee
Distributed Programming Framework, hadoop
by
LGU+
Hadoop Introduction (1.0)
by
Keeyong Han
고성능 빅데이터 수집 및 분석 솔루션 - 티맥스소프트 허승재 팀장
by
eungjin cho
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: 보안 로그 분석을 위한 빅데이터 시스템 구축 사례
by
Gruter
Hadoop administration
by
Ryan Guhnguk Ahn
More from Gruter
PDF
MelOn 빅데이터 플랫폼과 Tajo 이야기
by
Gruter
PDF
Introduction to Apache Tajo: Future of Data Warehouse
by
Gruter
PDF
Expanding Your Data Warehouse with Tajo
by
Gruter
PDF
Introduction to Apache Tajo: Data Warehouse for Big Data
by
Gruter
PPTX
Introduction to Apache Tajo
by
Gruter
PDF
스타트업사례로 본 로그 데이터분석 : Tajo on AWS
by
Gruter
PDF
What's New Tajo 0.10 and Its Beyond
by
Gruter
PDF
Big data analysis with R and Apache Tajo (in Korean)
by
Gruter
PDF
Efficient In‐situ Processing of Various Storage Types on Apache Tajo
by
Gruter
PDF
Tajo TPC-H Benchmark Test on AWS
by
Gruter
PDF
Data analysis with Tajo
by
Gruter
PDF
Gruter TECHDAY 2014 Realtime Processing in Telco
by
Gruter
PPTX
Gruter TECHDAY 2014 MelOn BigData
by
Gruter
PDF
Gruter_TECHDAY_2014_04_TajoCloudHandsOn (in Korean)
by
Gruter
PPTX
Gruter_TECHDAY_2014_03_ApacheTajo (in Korean)
by
Gruter
PDF
Gruter_TECHDAY_2014_01_SearchEngine (in Korean)
by
Gruter
PPTX
Apache Tajo - BWC 2014
by
Gruter
PPTX
Elastic Search Performance Optimization - Deview 2014
by
Gruter
PPTX
Hadoop security DeView 2014
by
Gruter
PPTX
Vectorized processing in_a_nutshell_DeView2014
by
Gruter
MelOn 빅데이터 플랫폼과 Tajo 이야기
by
Gruter
Introduction to Apache Tajo: Future of Data Warehouse
by
Gruter
Expanding Your Data Warehouse with Tajo
by
Gruter
Introduction to Apache Tajo: Data Warehouse for Big Data
by
Gruter
Introduction to Apache Tajo
by
Gruter
스타트업사례로 본 로그 데이터분석 : Tajo on AWS
by
Gruter
What's New Tajo 0.10 and Its Beyond
by
Gruter
Big data analysis with R and Apache Tajo (in Korean)
by
Gruter
Efficient In‐situ Processing of Various Storage Types on Apache Tajo
by
Gruter
Tajo TPC-H Benchmark Test on AWS
by
Gruter
Data analysis with Tajo
by
Gruter
Gruter TECHDAY 2014 Realtime Processing in Telco
by
Gruter
Gruter TECHDAY 2014 MelOn BigData
by
Gruter
Gruter_TECHDAY_2014_04_TajoCloudHandsOn (in Korean)
by
Gruter
Gruter_TECHDAY_2014_03_ApacheTajo (in Korean)
by
Gruter
Gruter_TECHDAY_2014_01_SearchEngine (in Korean)
by
Gruter
Apache Tajo - BWC 2014
by
Gruter
Elastic Search Performance Optimization - Deview 2014
by
Gruter
Hadoop security DeView 2014
by
Gruter
Vectorized processing in_a_nutshell_DeView2014
by
Gruter
Cloumon sw제품설명회 발표자료
1.
©2014 Gruter. All
rights reserved.
2.
빅데이터
3.
통합
4.
관리
5.
솔루션
6.
7.
Cloumon®
8.
Enterprise
9.
10.
(주)그루터 contact@gruter.com
11.
12.
© 2014 Gruter.
All rights reserved .
13.
2
14.
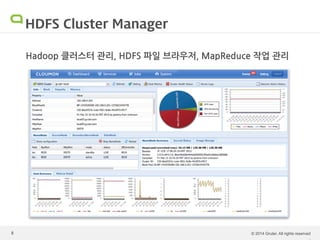
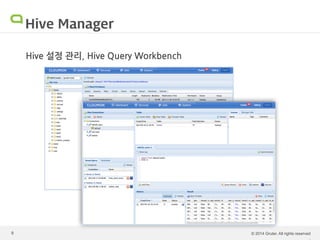
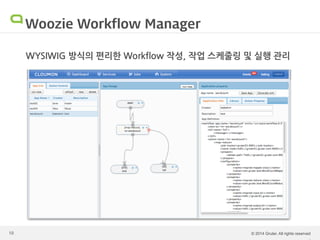
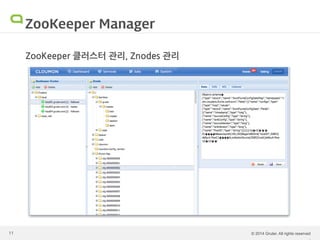
Hadoop 운영의 어려움 Hadoop은










![[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/open-technet-summit-2014-140313001107-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


































