Big Data Platform Field Case in MelOn (in Korean)
- Presented by Byeong-hwa Yoon, engineer manager at Loen Entertainment
- at Gruter TECHDAY 2014 Oct. 29 Seoul, Korea
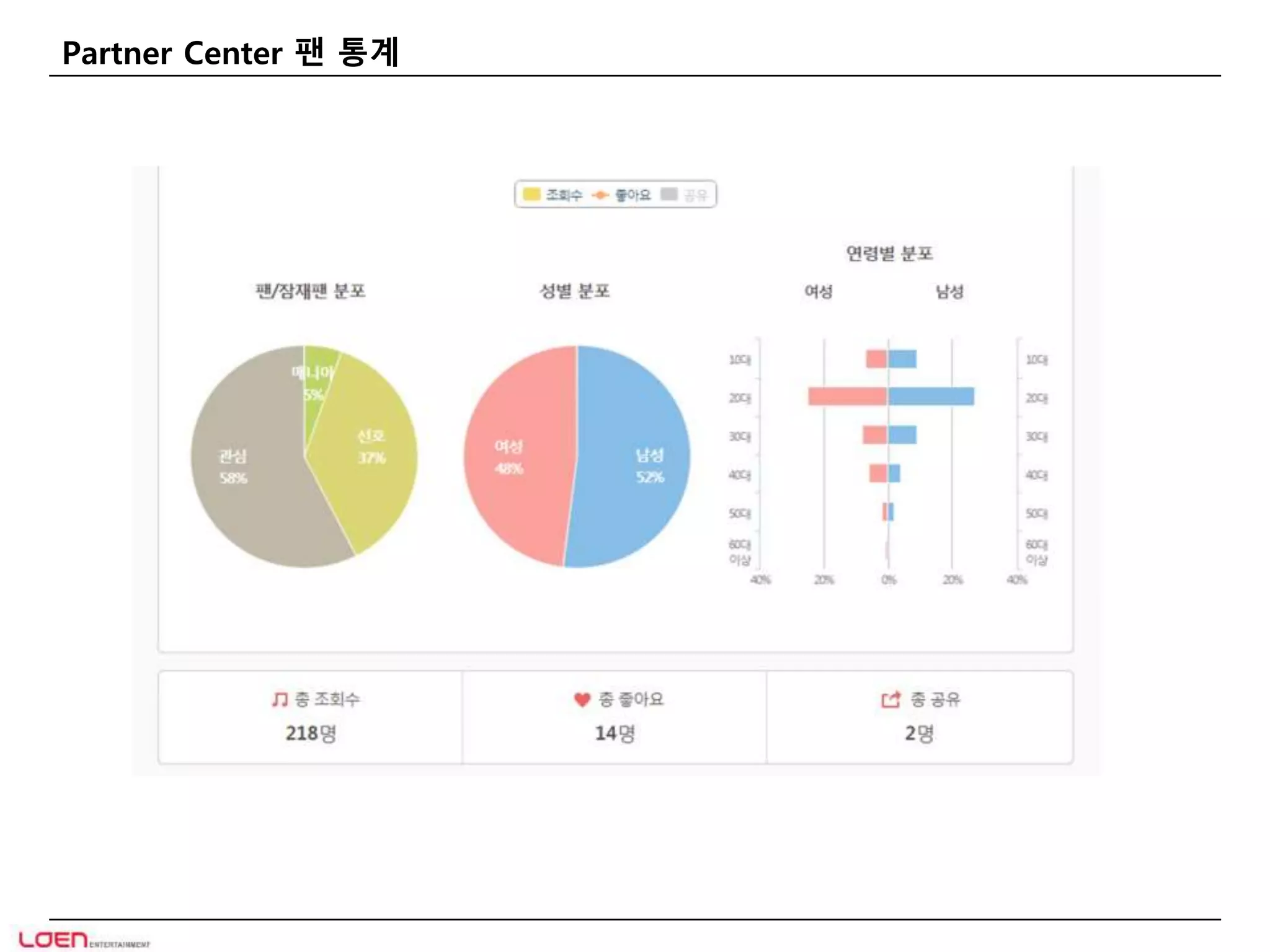
MelOn 친밀도
•아티스트 친밀도를 이용한 재미
• 친구들과의 인기도 공유
• 이용자 X 아티스트 수의 데이터양
13.
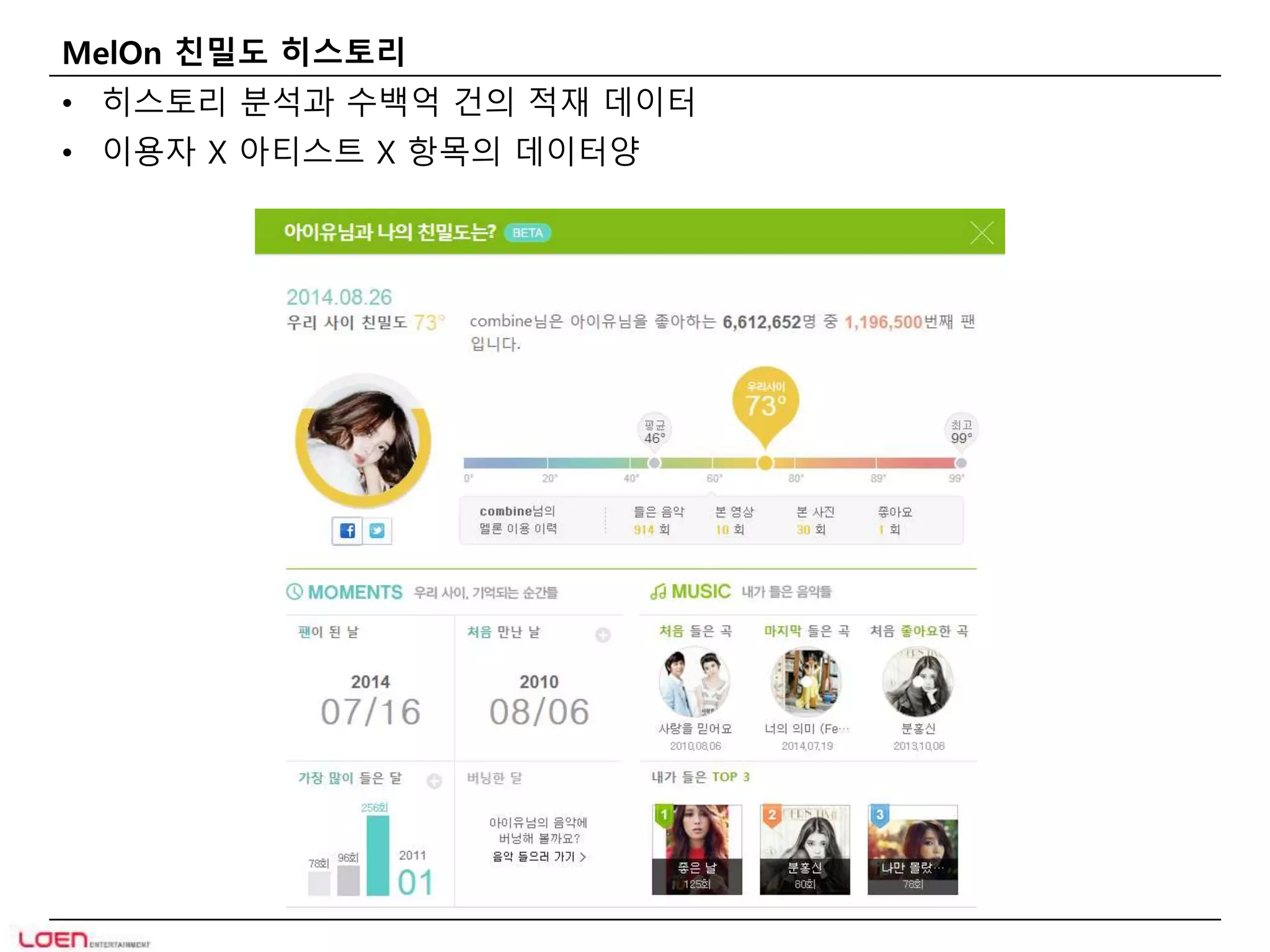
MelOn 친밀도 히스토리
• 히스토리 분석과 수백억 건의 적재 데이터
• 이용자 X 아티스트 X 항목의 데이터양
14.
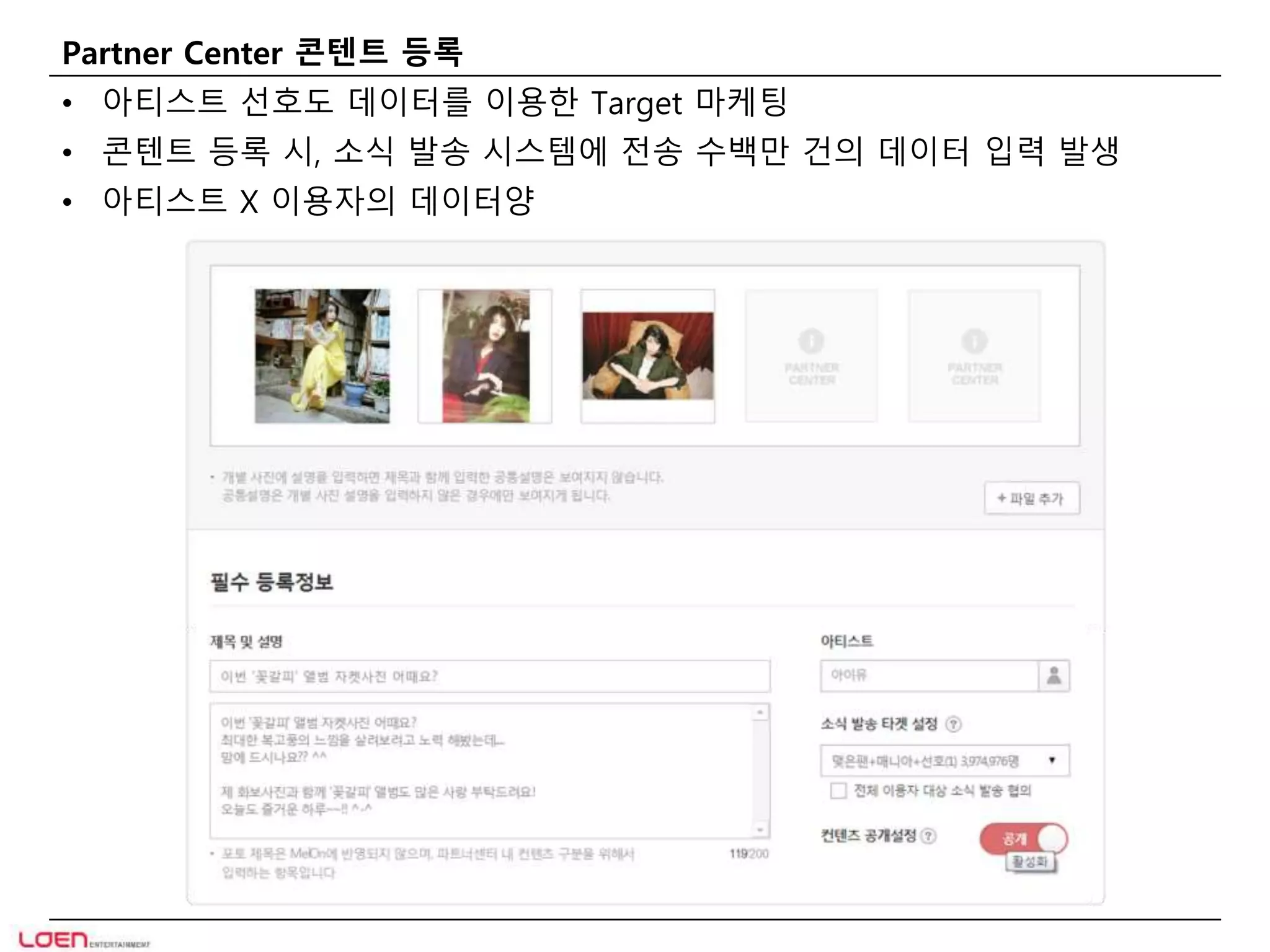
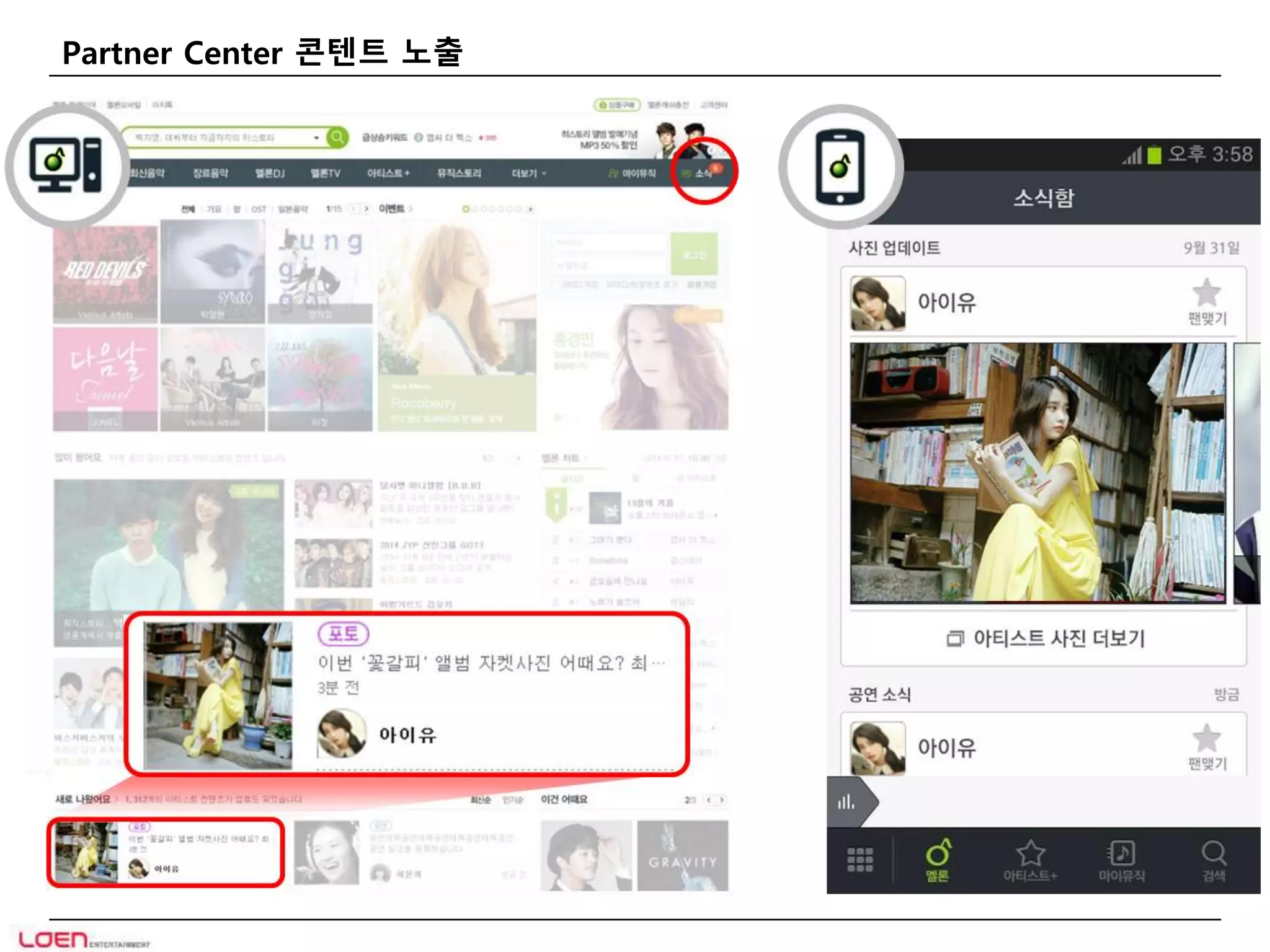
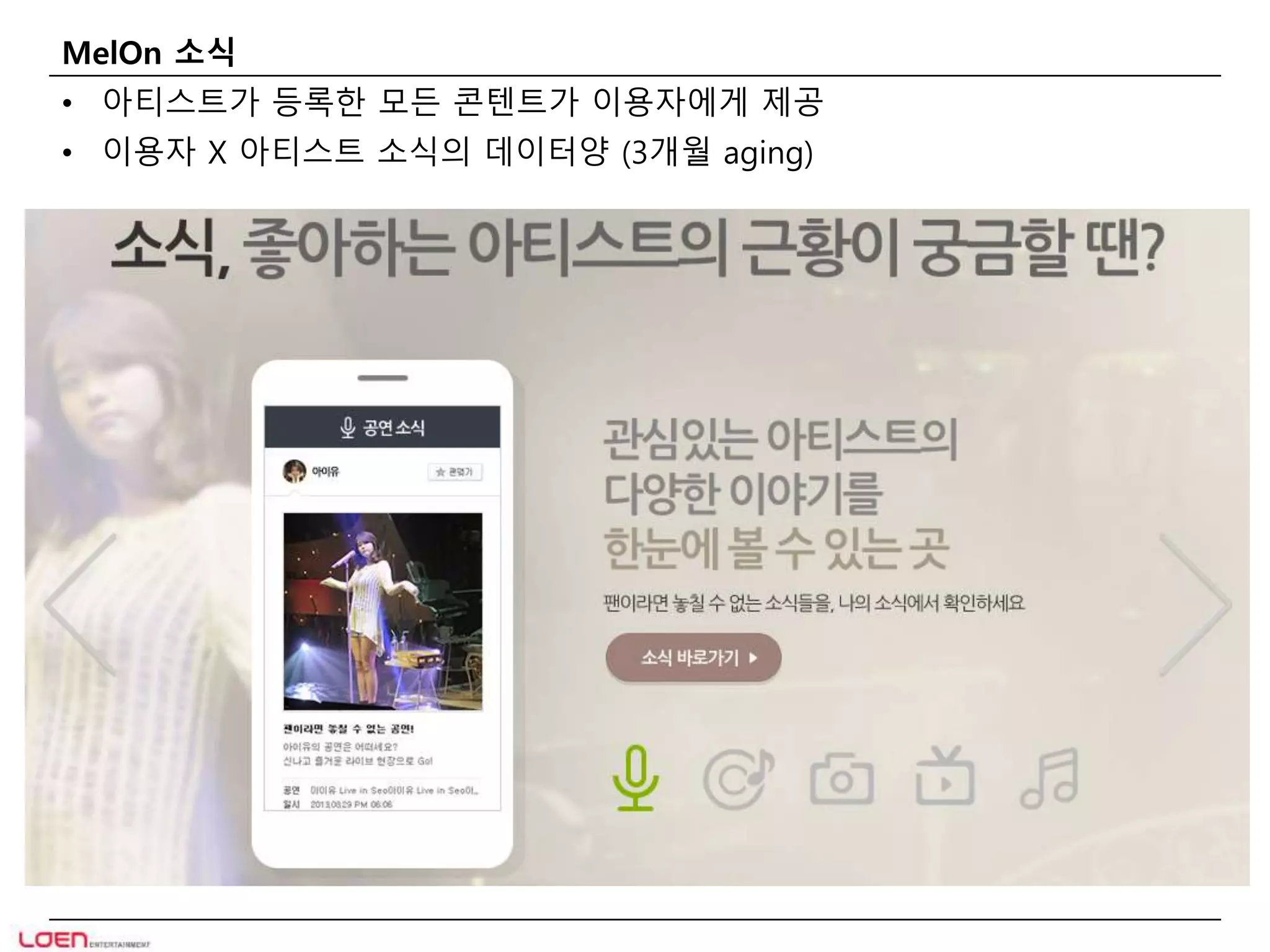
MelOn 소식
•아티스트가 등록한 모든 콘텐트가 이용자에게 제공
• 이용자 X 아티스트 소식의 데이터양 (3개월 aging)
15.
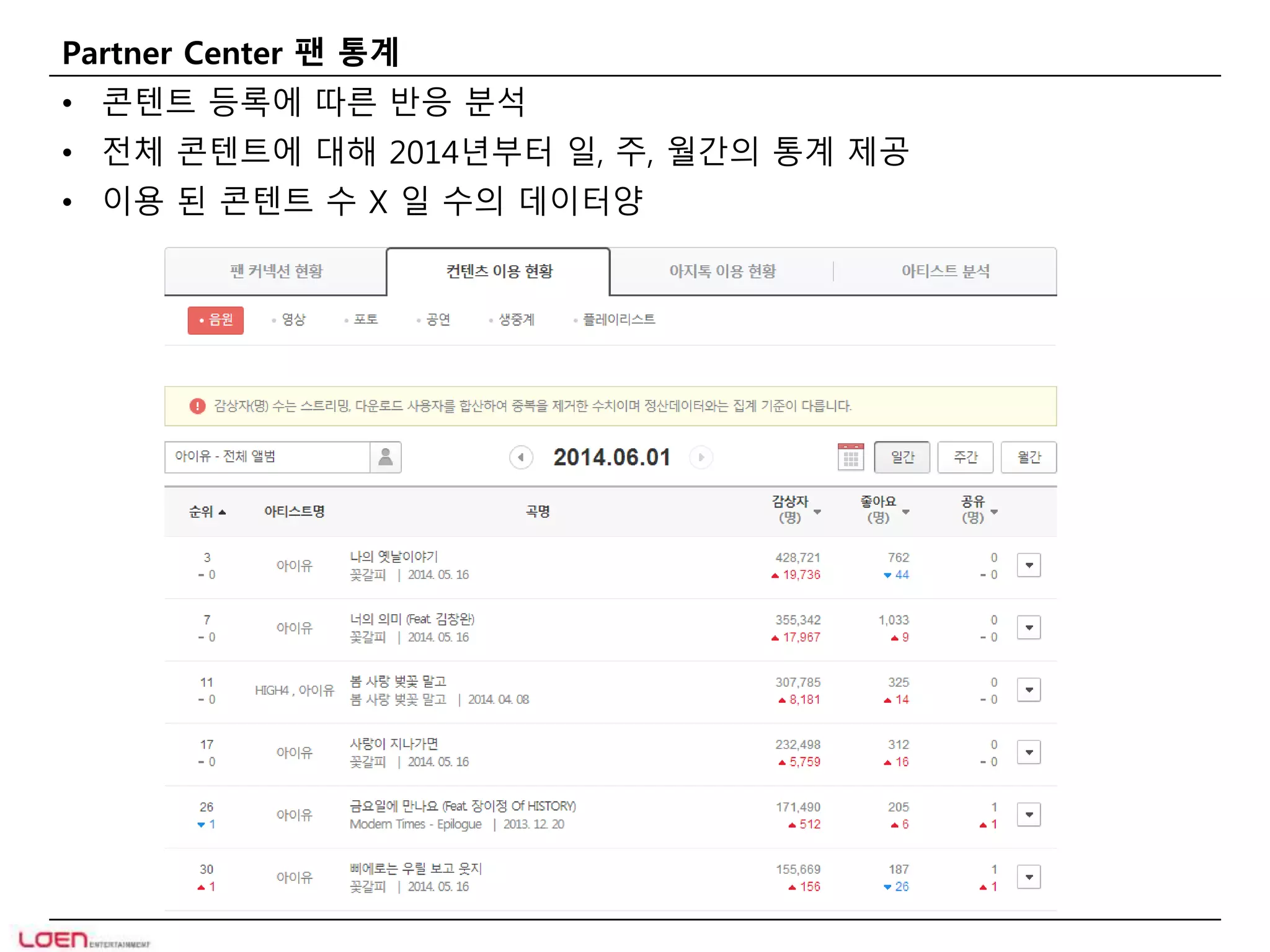
BIG DATA Volume?
• 총 10년간 음원 소비 이력 = 877억건+
• 일 평균 7천만+ 스트리밍 건수
• 월 평균 1,200만+ UV(Unique Visitors)
• 아티스트와 이용자 연결? 아티스트 X 이용자 = 43억건+
• 이용자별 아티스트 친밀도 히스토리? 아티스트 X 이용자 X 항목 = 745억+
• 컨텐츠 이용 통계? 320만곡 X 365일 = 10억건+
• 일 2TB+ 데이터 생성. 현재 300TB+ 사용 중
(최소한의 정보만 적재를 원칙으로 하며, 서비스에 따라 Aging 정책 적용 중)
16.
MelOn 빅데이터의 현재
• 공존! Hadoop이 잘하는 것과 Netezza가 잘하는 것은 분명 다름
DW 분석계
~ 2011
서비스 분석계
2012 ~
17.
빅데이터 솔루션 선택기준
• 분석 관점
• 기존 자바와 오라클을 이용한 배치 애플리케이션의 한계
• 방대한양의 분석 결과 보관 및 재사용
• 다양한 분석 알고리즘 부재
• 서비스 관점
• 방대한양의 분석 결과 적재 가능
• 대량 데이터 온라인 입력, 조회 가능
• 2011년 RDBMS를 이용한 소식 서비스의 부하 경험
18.
빅데이터 솔루션 선택(2011년하반기 시점)
• 오픈 소스 고민 사항
• 내부 인력 부재
• 안정성 불안
• 상용 솔루션
• 고비용 필요
• 알고리즘 개발 필요
• 레퍼런스 부족
• SPADE
• 지속적인 기술지원에 대한 의문
• MLCP 발전 따른 추가 개발 요소 필요
• 안정적 대용량 데이터 서비스
• 머신러닝 CF를 이용한 추천 필요
오픈 소스 기반 하둡, HBase, Mahout]
단, 기술 내재화를 가능케 할 파트너 필요
Hadoop 배포판
•프로젝트 최초 선택
• 2011년 HA 지원여부에 따른 선택 CDH4
• 현재 Apache Hadoop 2.5, HBase 0.98
MelOn CDH 5.0 (Hadoop 2.3, HBase 0.96)
21.
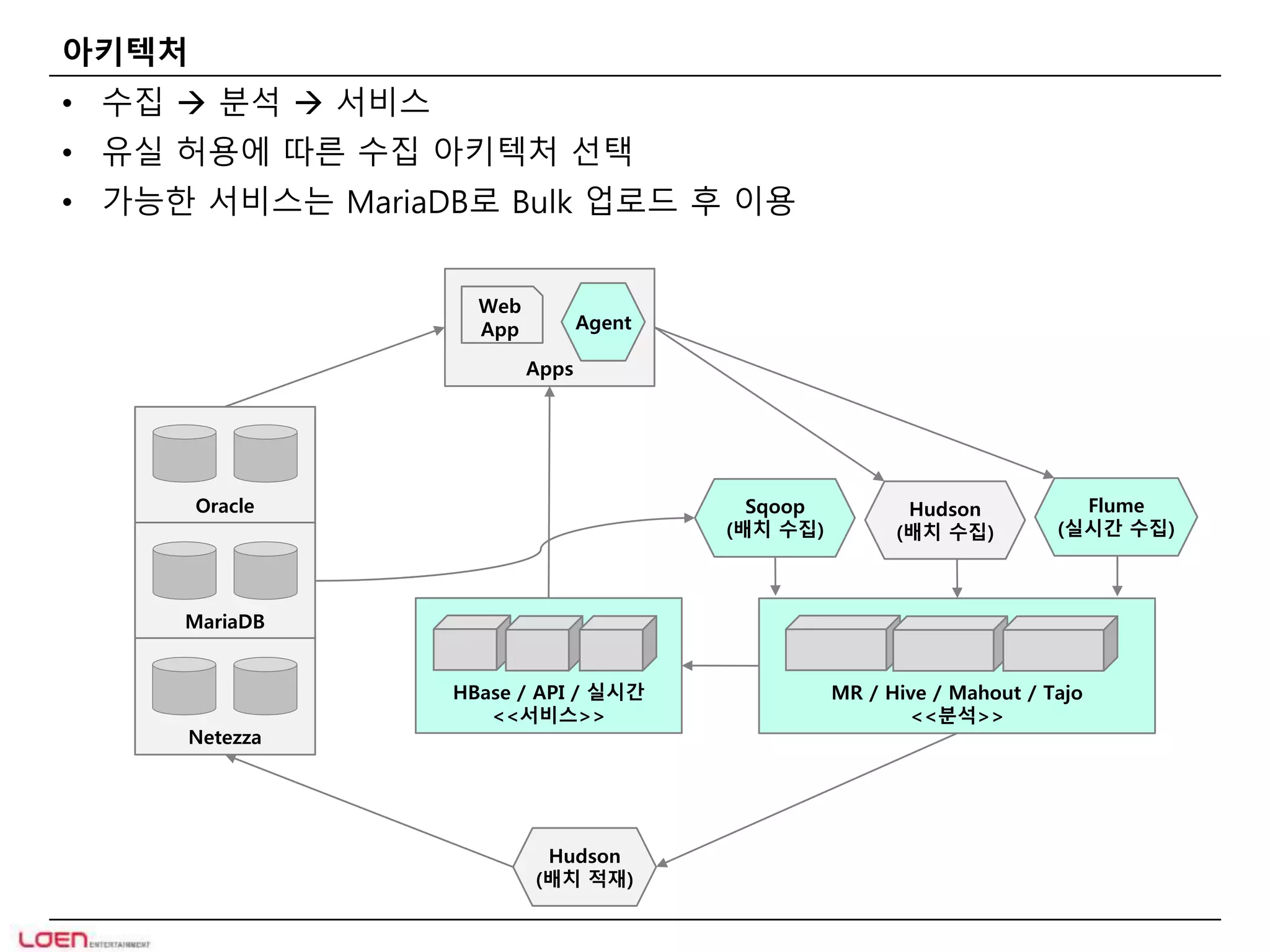
아키텍처
• 수집 분석 서비스
• 유실 허용에 따른 수집 아키텍처 선택
• 가능한 서비스는 MariaDB로 Bulk 업로드 후 이용
Web
App Agent
Apps
Hudson
(배치 수집)
MR / Hive / Mahout / Tajo
<<분석>>
Flume
(실시간 수집)
HBase / API / 실시간
<<서비스>>
Hudson
(배치 적재)
Sqoop
(배치 수집)
Oracle
MariaDB
Netezza
22.
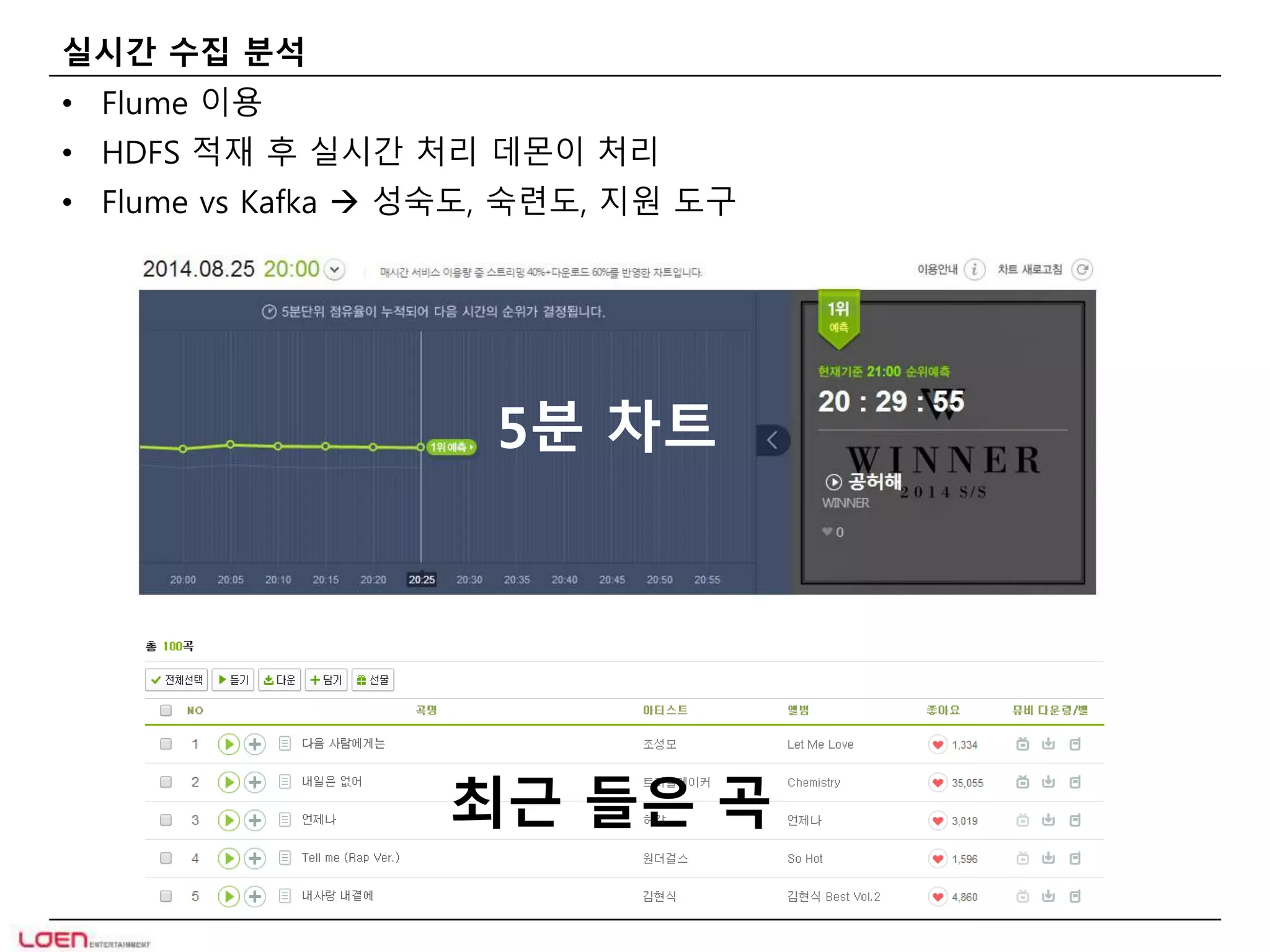
실시간 수집 분석
• Flume 이용
• HDFS 적재 후 실시간 처리 데몬이 처리
• Flume vs Kafka 성숙도, 숙련도, 지원 도구
5분 차트
최근 들은 곡
23.
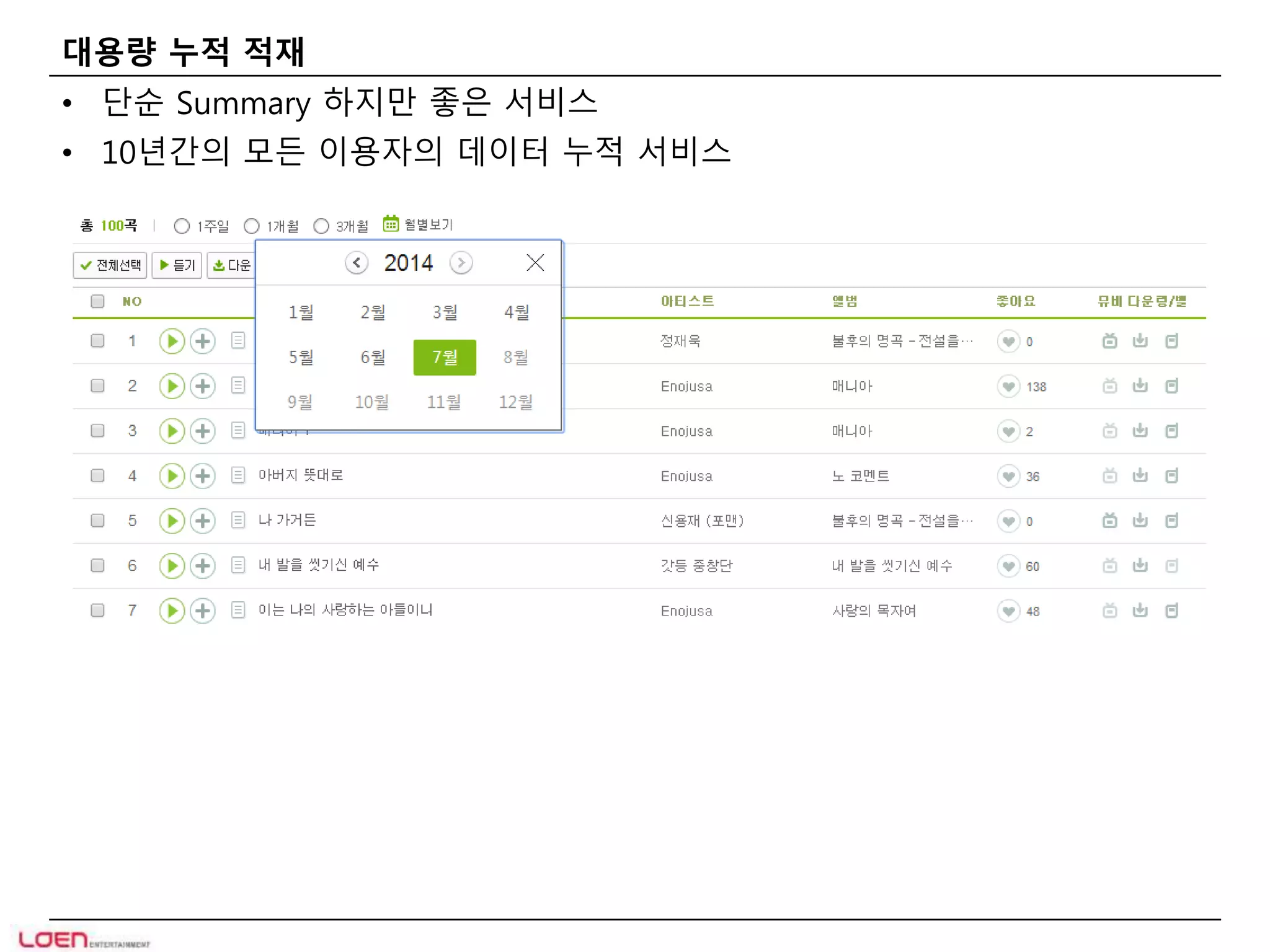
대용량 누적 적재
• 단순 Summary 하지만 좋은 서비스
• 10년간의 모든 이용자의 데이터 누적 서비스
24.
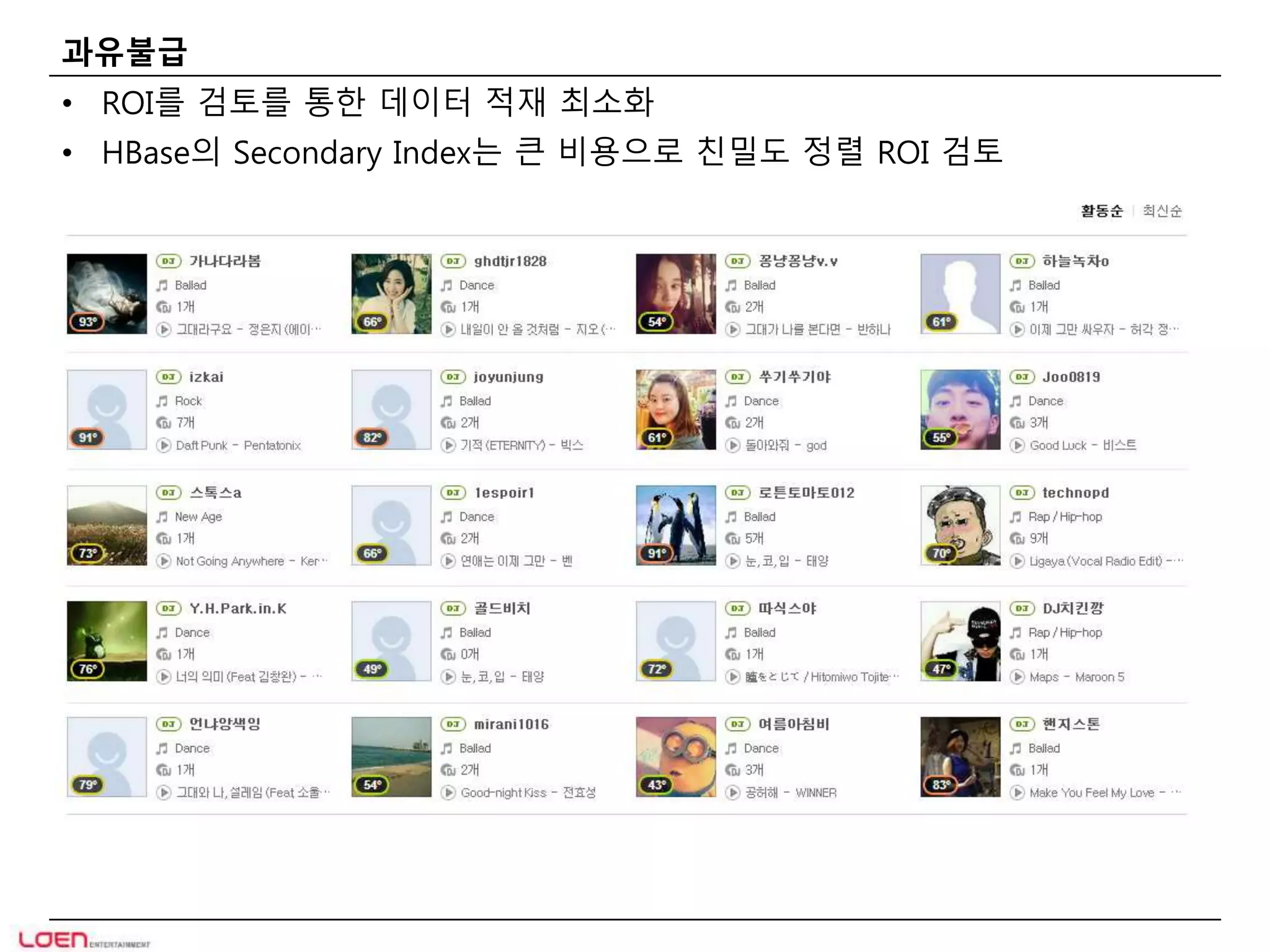
과유불급
• ROI를검토를 통한 데이터 적재 최소화
• HBase의 Secondary Index는 큰 비용으로 친밀도 정렬 ROI 검토
25.
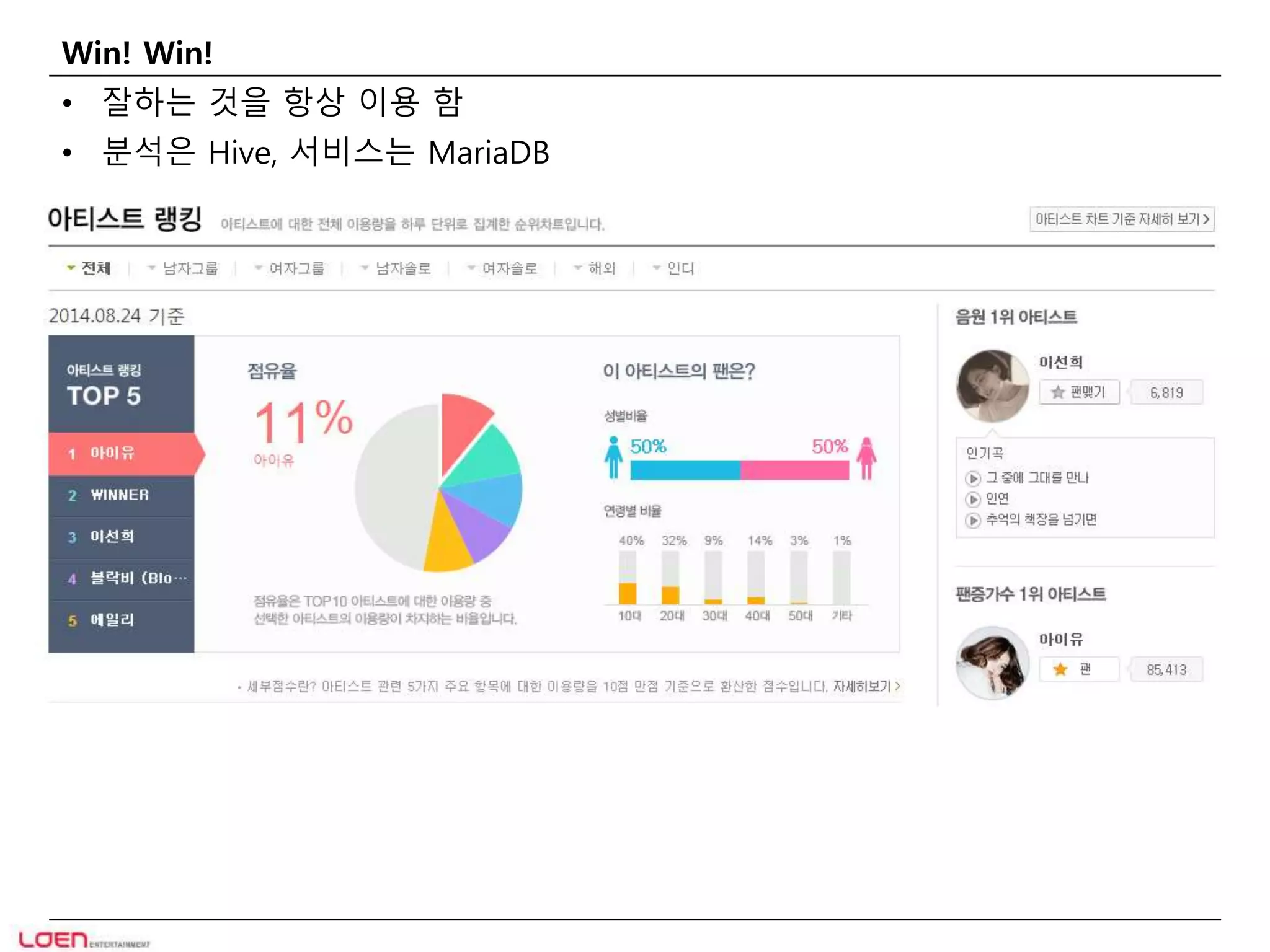
Win! Win!
•잘하는 것을 항상 이용 함
• 분석은 Hive, 서비스는 MariaDB
26.
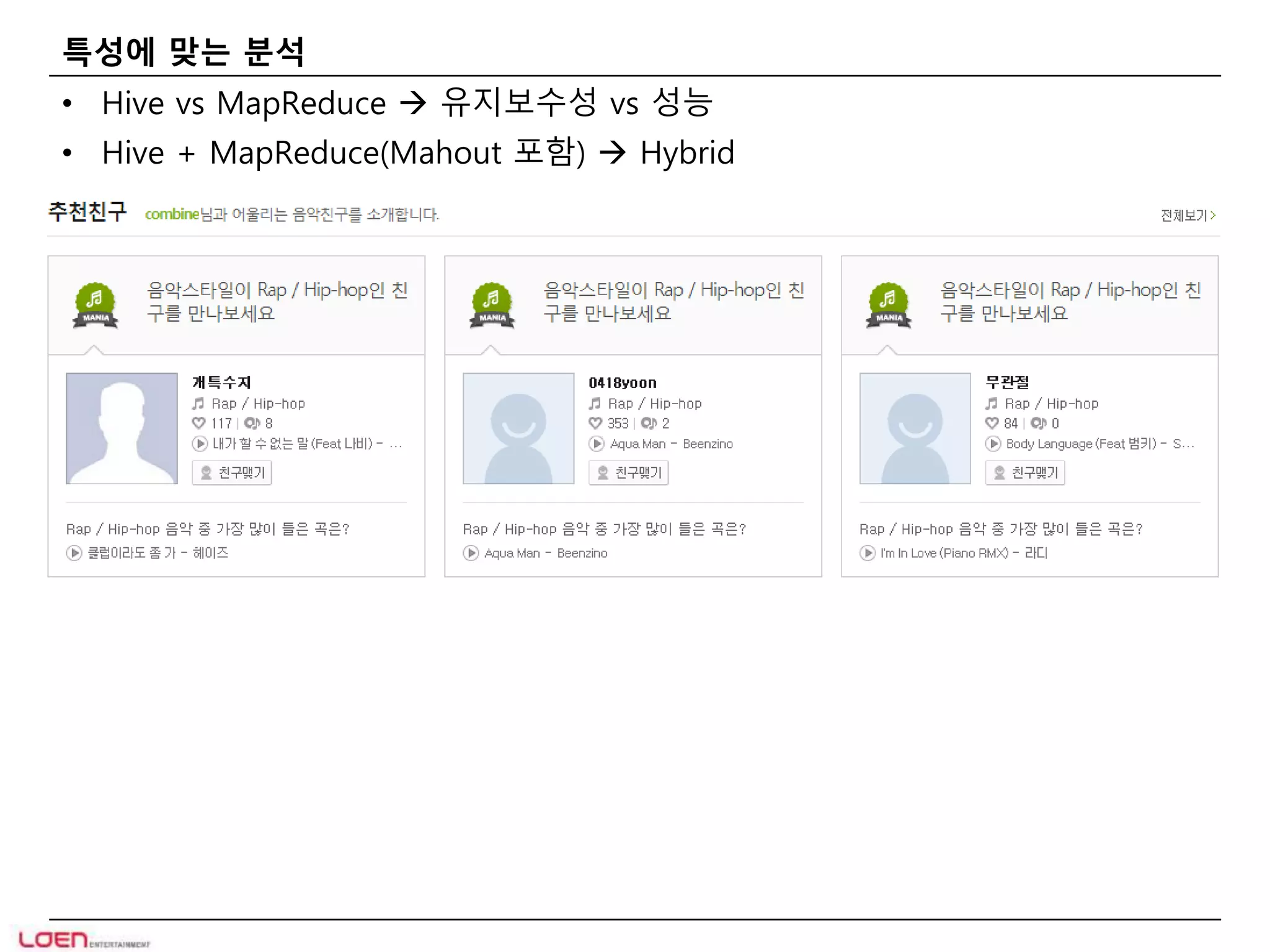
특성에 맞는 분석
• Hive vs MapReduce 유지보수성 vs 성능
• Hive + MapReduce(Mahout 포함) Hybrid
27.
내 것의 소중함
• 하둡 workflow 엔진 Oozie vs Hudson
• 관리측면에서 기 사용중인 Hudson 유지
• 2014년 8월 현재 417개 분석/적재 배치
28.
하둡에서 배운 점
• 간단한 연산도 신중히
• 데이터형 변환의 비용
• 실수 연수의 비용
• SimpleDateFormat 등 객체 재사용(온라인 애플리케이션에선 절대 재사용 안함)
• 네트워크 사용량 예측
• 클러스터간 데이터 복제 시 내부 네트워크 1g 모두 사용
• 10g로 내부 네트워크 전환
• 복제 시 전송량 제한
• 적당한 부하
• 무리한 워크로드는 장비 고장 유발
• 분석 배치 스케줄 분산 필요
• 하둡 버전 업그레이드는 신중히(CDH 4 5전환)
• Hive 내부 처리 변경(예: 수치 계산 ‘NaN’ null)
• 서비스에 맞는 튜닝
• 인터넷에는 오래된 가이드 또는 버전 별로 설정 다름
• 최신 하둡 버전은 더 많은 Heap 영역 요구
29.
인프라에서 배운 점
• No저비용
• 제한적인 상면 공간
• 유지보수 업체는 선택이 아닌 필수
• 10g 이더넷, HDD 등 자잘한 추가 비용
• 잦은 H/W 고장
• 분석 시 평균 로드가 70%이상. CPU 팬, 디스크, 컨트롤러, 메모리 등 다양함
• 운영계약이 필수가 되는 요인
• OMC 등의 장애 감지 시스템은 필수(프로세스, 로그, 시스템 상태 등 감시)
• 하둡 에코시스템에 특화된 모니터링 도구도 필수
• 주요 분석은 업무시간에 수행
• 제한된 운영 및 관제 인력
• 하둡 이해도의 한계
• 자동화 지원 도구(CMS 등) 필요. 마음은 chef 현실은 rsync
• 전문 관제 인력 전무. 매뉴얼 적인 업무 수행
• 인프라 입장의 하둡 플랫폼에 대해 지속적인 학습 필요
30.
개발에서 배운 점
• 하늘의 별 따기 하둡 개발자 모시기
• MelOn 만의 고민은 아님
• 개발자 백업 체계 문제
• 트러블슈팅의 한계
• 내부 스터디 및 전문 회사와 협력 관계 필수
• 프레임워크는 아니어도 공통화는 필수
• 데이터에 대한 시야
• 기획자/개발자 모두 필요
• 도메인 지식 필수, 통계적 마인드 필요.
• 사견은 MelOn에 데이터 사이언티스트는 있음.
• HBase 특성에 따른 제약
• Contingency Plan 필요에 따른 구현 난이도 향상
(2달간 한번도 발생한 적 없음)
• 정렬의 어려움
• 페이징처리의 제한
• 1천만건 이하는 MariaDB 이용
31.
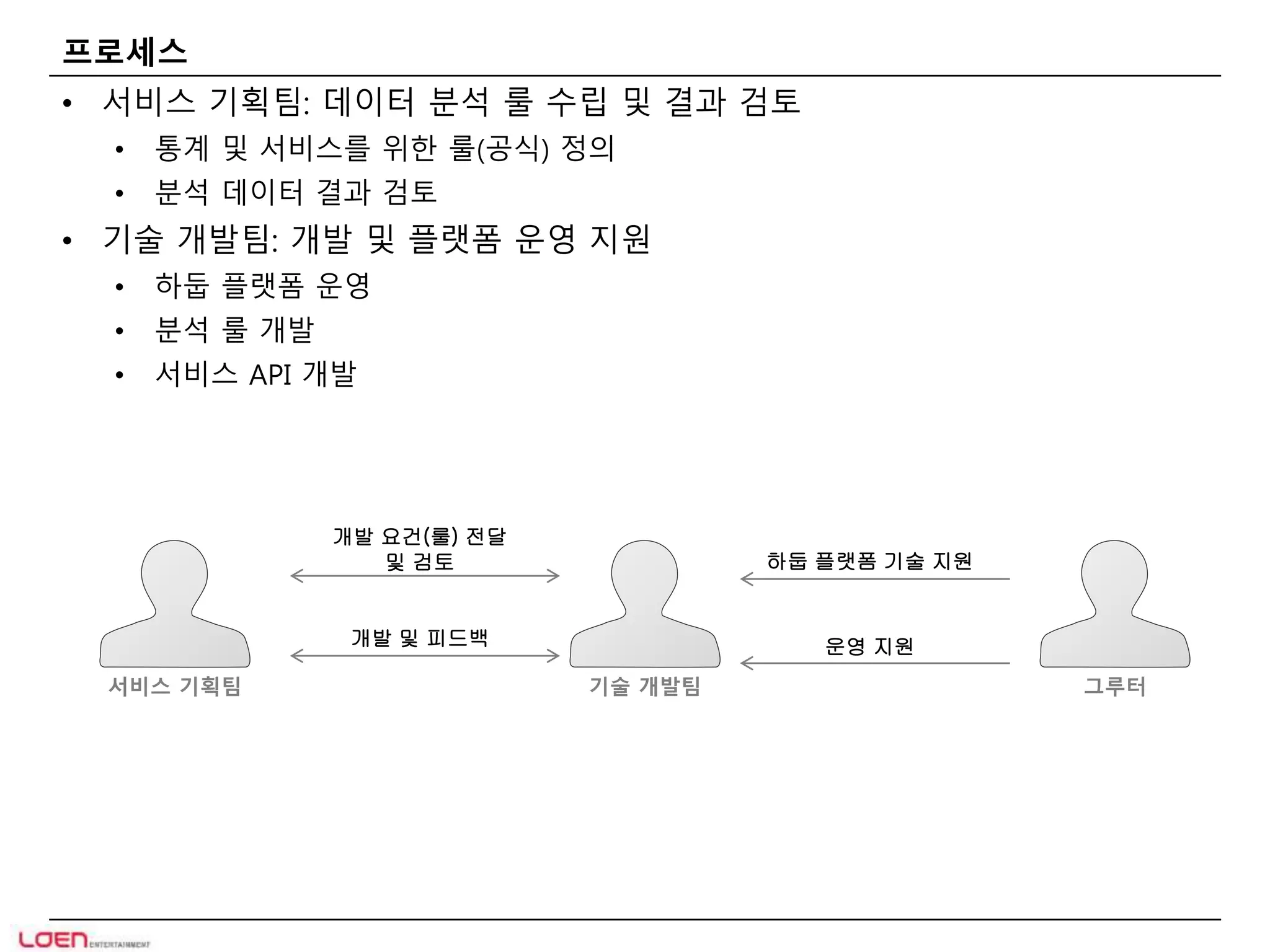
프로세스
• 서비스기획팀: 데이터 분석 룰 수립 및 결과 검토
• 통계 및 서비스를 위한 룰(공식) 정의
• 분석 데이터 결과 검토
• 기술 개발팀: 개발 및 플랫폼 운영 지원
• 하둡 플랫폼 운영
• 분석 룰 개발
• 서비스 API 개발
그루터
하둡 플랫폼 기술 지원
운영 지원
개발 요건(룰) 전달
및 검토
개발 및 피드백
서비스 기획팀 기술 개발팀
32.
향후 과제: 추천
• 소비가 쉽고, 콘텐트가 많은 MelOn
• 웨어러블 디바이스, 스마트카의 등장
• 추천은 반드시 필요
• MelOn이 생각하는 추천
• 메타 기반 추천
• 콘텐트 기반 추천
• 고객 이력 기반 추천
• 결론은 하이브리드와 이용자 컨텍스트에 대한 이해







![빅데이터 솔루션 선택(2011년 하반기 시점)
• 오픈 소스 고민 사항
• 내부 인력 부재
• 안정성 불안
• 상용 솔루션
• 고비용 필요
• 알고리즘 개발 필요
• 레퍼런스 부족
• SPADE
• 지속적인 기술지원에 대한 의문
• MLCP 발전 따른 추가 개발 요소 필요
• 안정적 대용량 데이터 서비스
• 머신러닝 CF를 이용한 추천 필요
오픈 소스 기반 하둡, HBase, Mahout]
단, 기술 내재화를 가능케 할 파트너 필요](https://image.slidesharecdn.com/grutertechday201402melonbigdata-141030203007-conversion-gate02/75/Gruter-TECHDAY-2014-MelOn-BigData-18-2048.jpg)













![[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/open-technet-summit-2014-140313001107-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























![제 19회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백발백준] : 백준봇 : 컨테이너 오케스트레이션 기반 백준 문제 추천 봇](https://cdn.slidesharecdn.com/ss_thumbnails/random-240209055922-328cce98-thumbnail.jpg?width=640&height=640&fit=bounds)
![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)









![[경북] I'mcloud openlight](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudopenlight-151105091914-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















