Downloaded 14 times






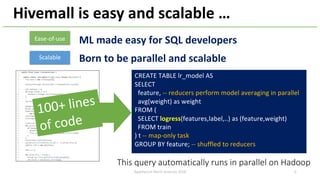
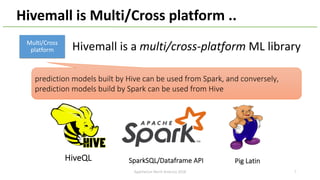
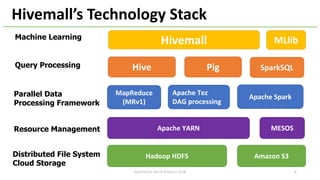














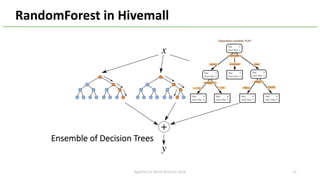



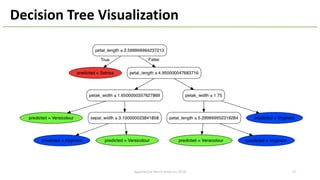
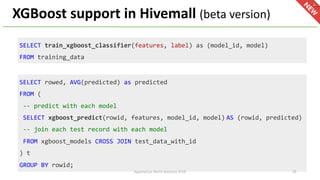


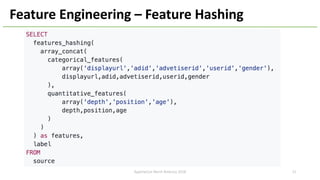





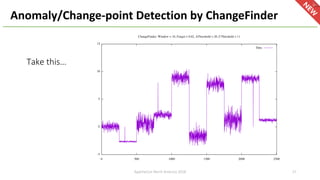
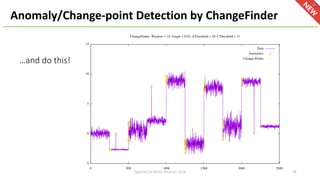
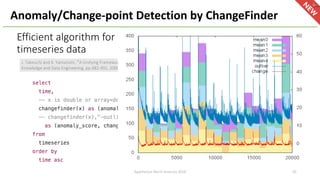


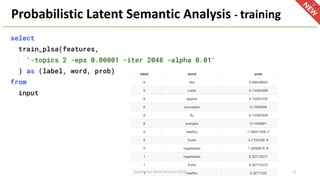
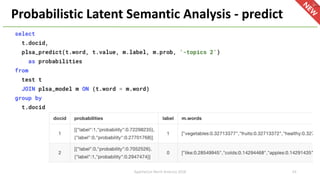




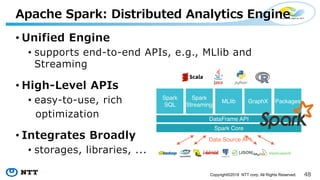


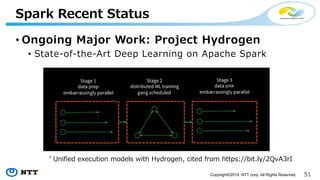
















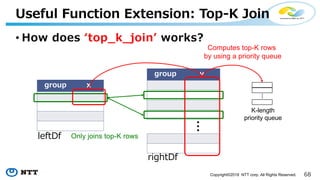
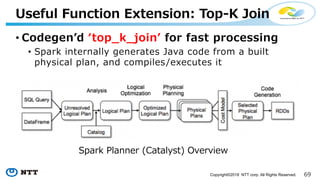




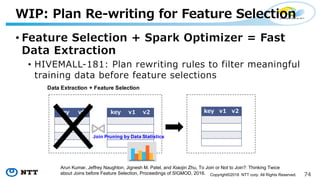



The document introduces Apache Hivemall v0.5.0, a scalable machine learning library for Hadoop and Spark, highlighting its features, such as anomaly detection, topic modeling, and support for various algorithms and utilities. It details the multi-platform capabilities that allow models created in Hive to be used in Spark and vice versa. Upcoming enhancements in future releases include support for Spark 2.3 and advanced algorithms like field-aware factorization machines and XGBoost.








































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














