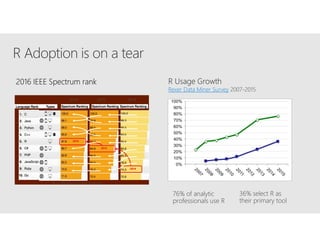
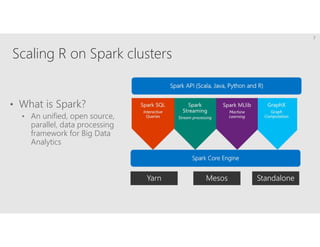
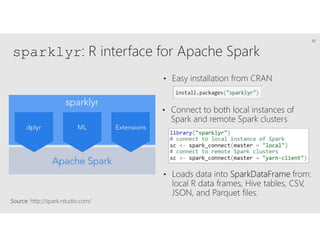
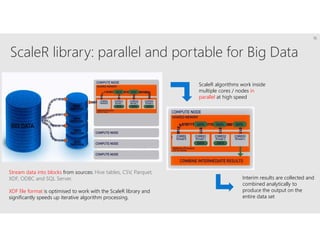
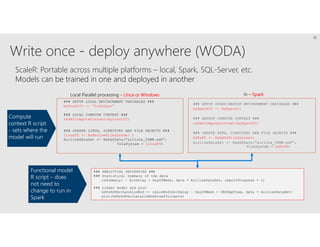
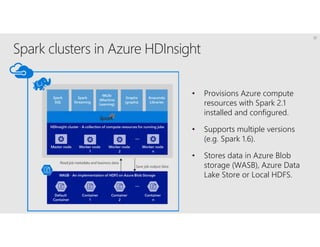
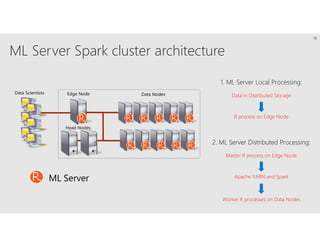
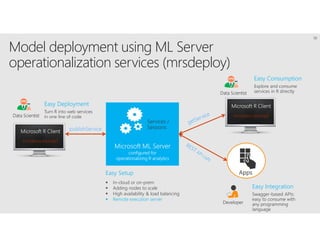
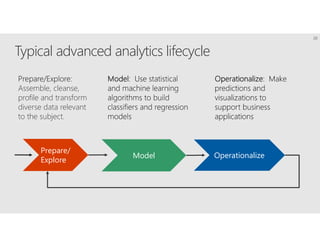
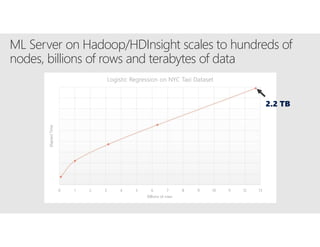
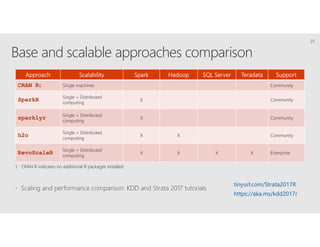
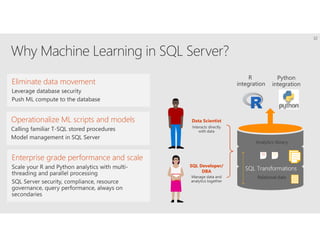
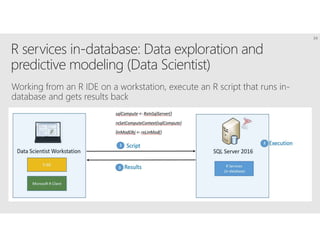
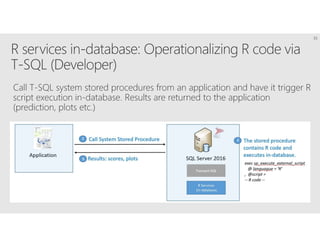
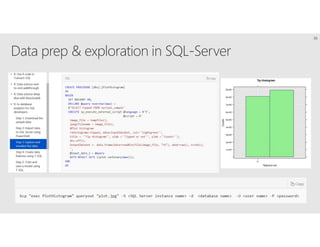
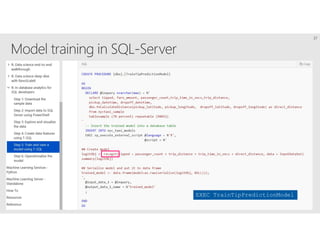
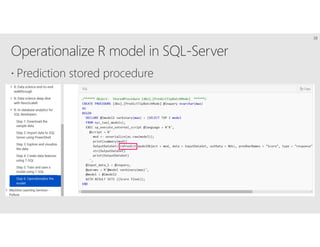
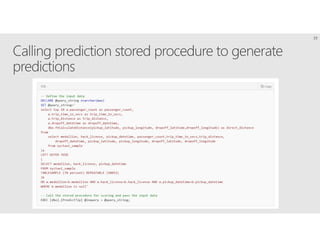
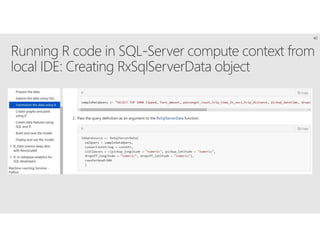
R is a popular statistical programming language used for data analysis and machine learning. It has over 3 million users and is taught widely in universities. While powerful, R has some scaling limitations for big data. Several Apache Spark integrations with R like SparkR and sparklyr enable distributed, parallel processing of large datasets using R on Spark clusters. Other options for scaling R include H2O for in-memory analytics, Microsoft ML Server for on-premises scaling, and ScaleR for portable parallel processing across platforms. These solutions allow R programs and models to be trained on large datasets and deployed for operational use on big data in various cloud and on-premises environments.










































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











