Downloaded 30 times




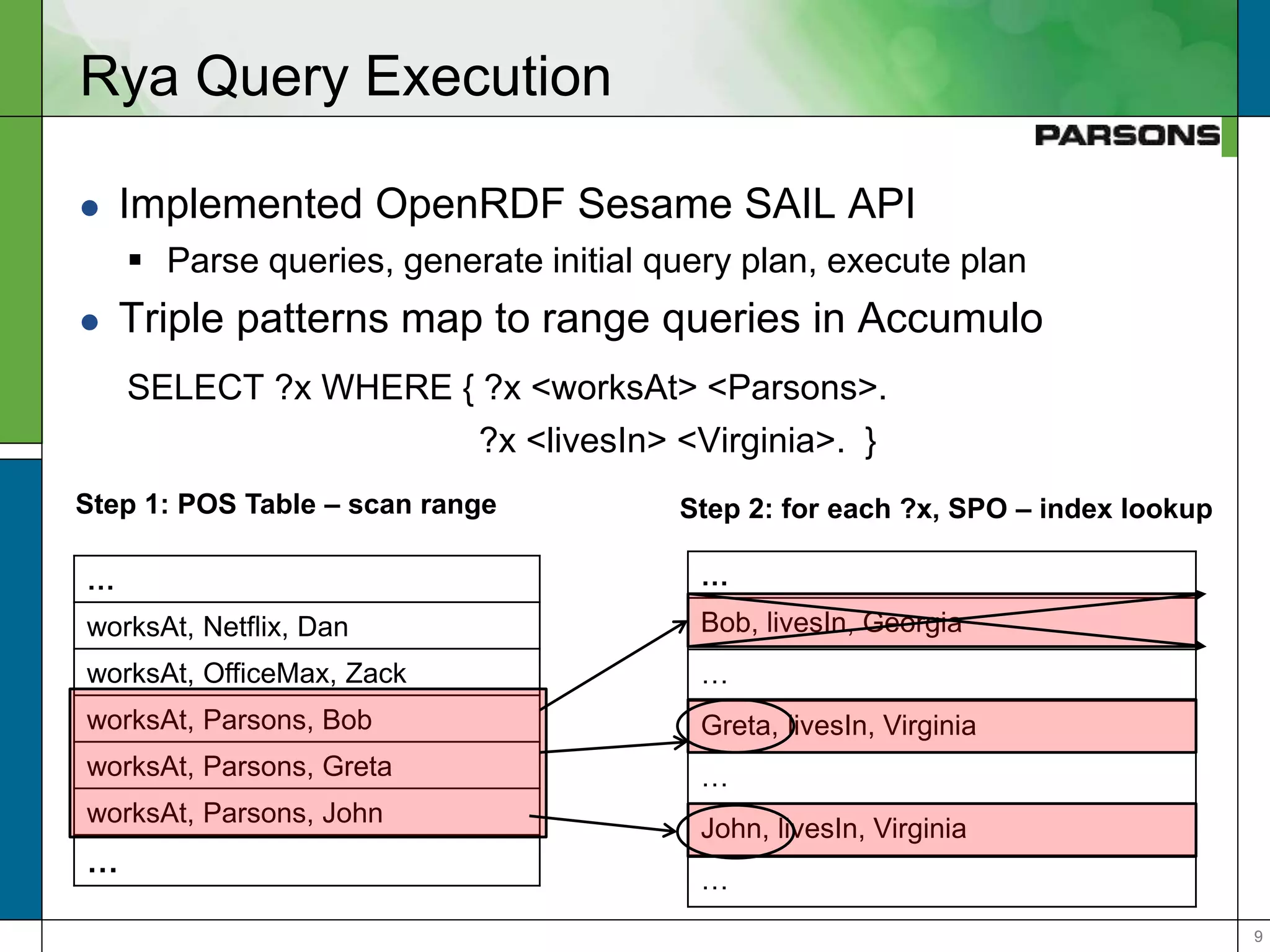
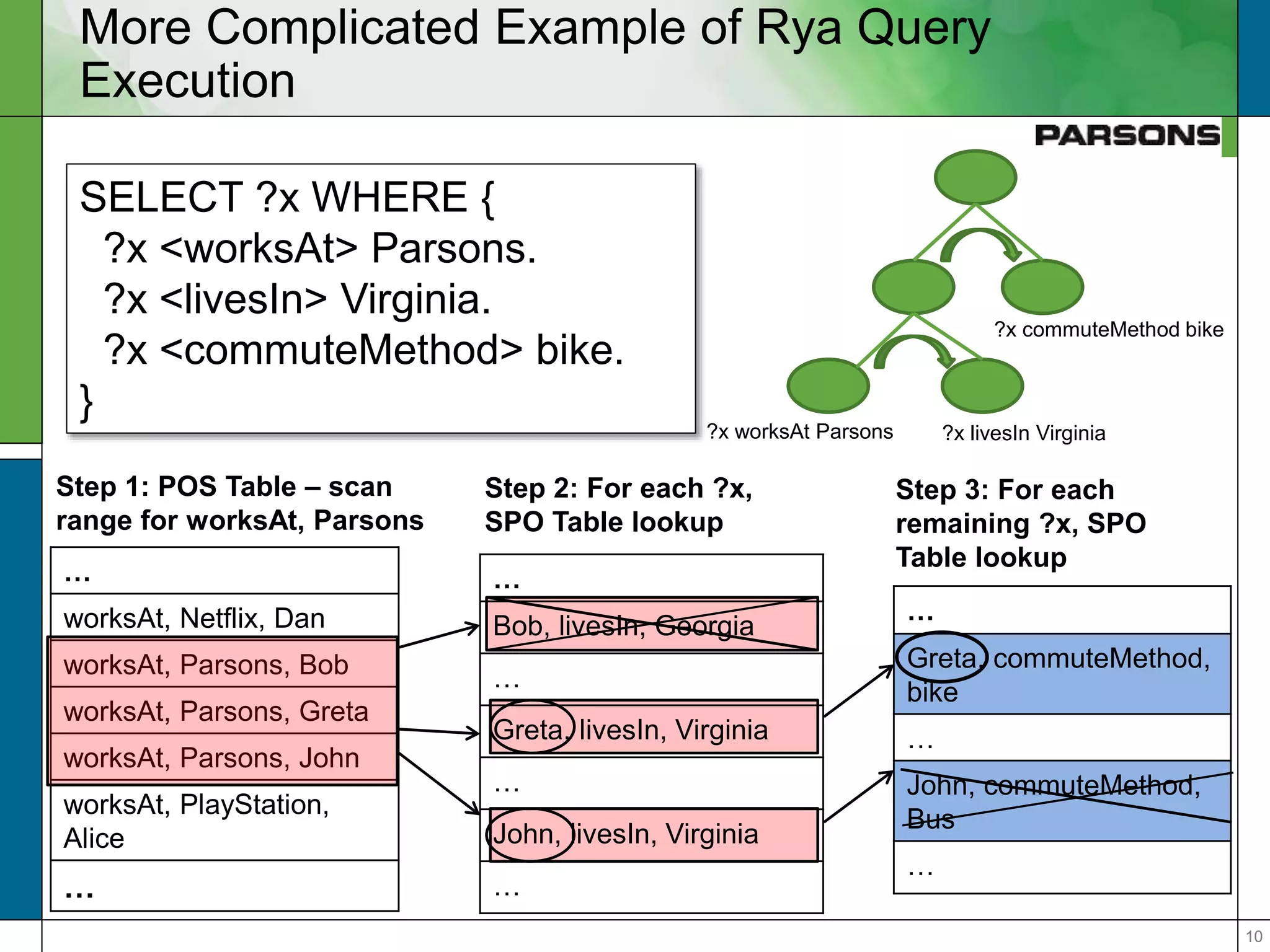









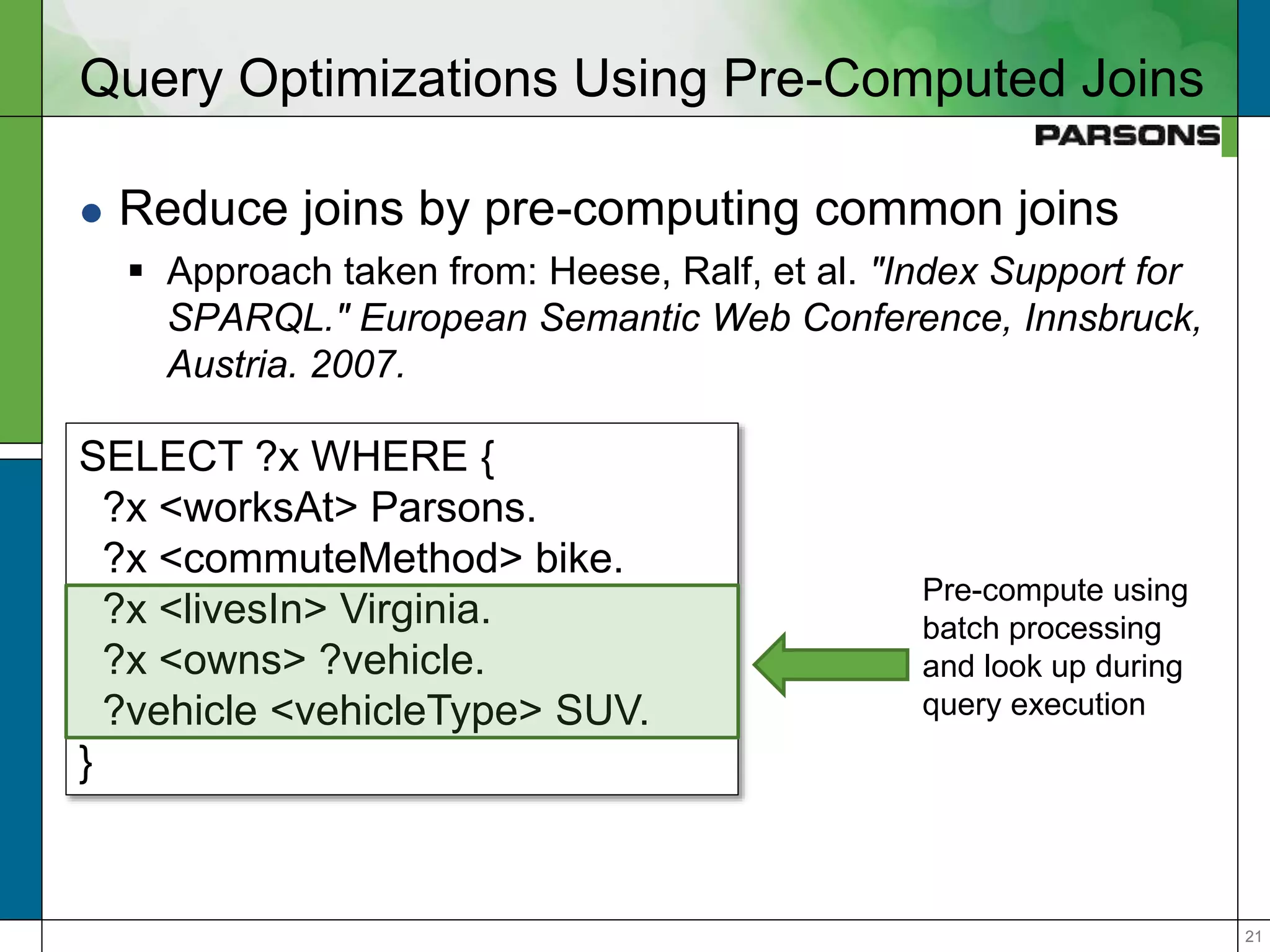
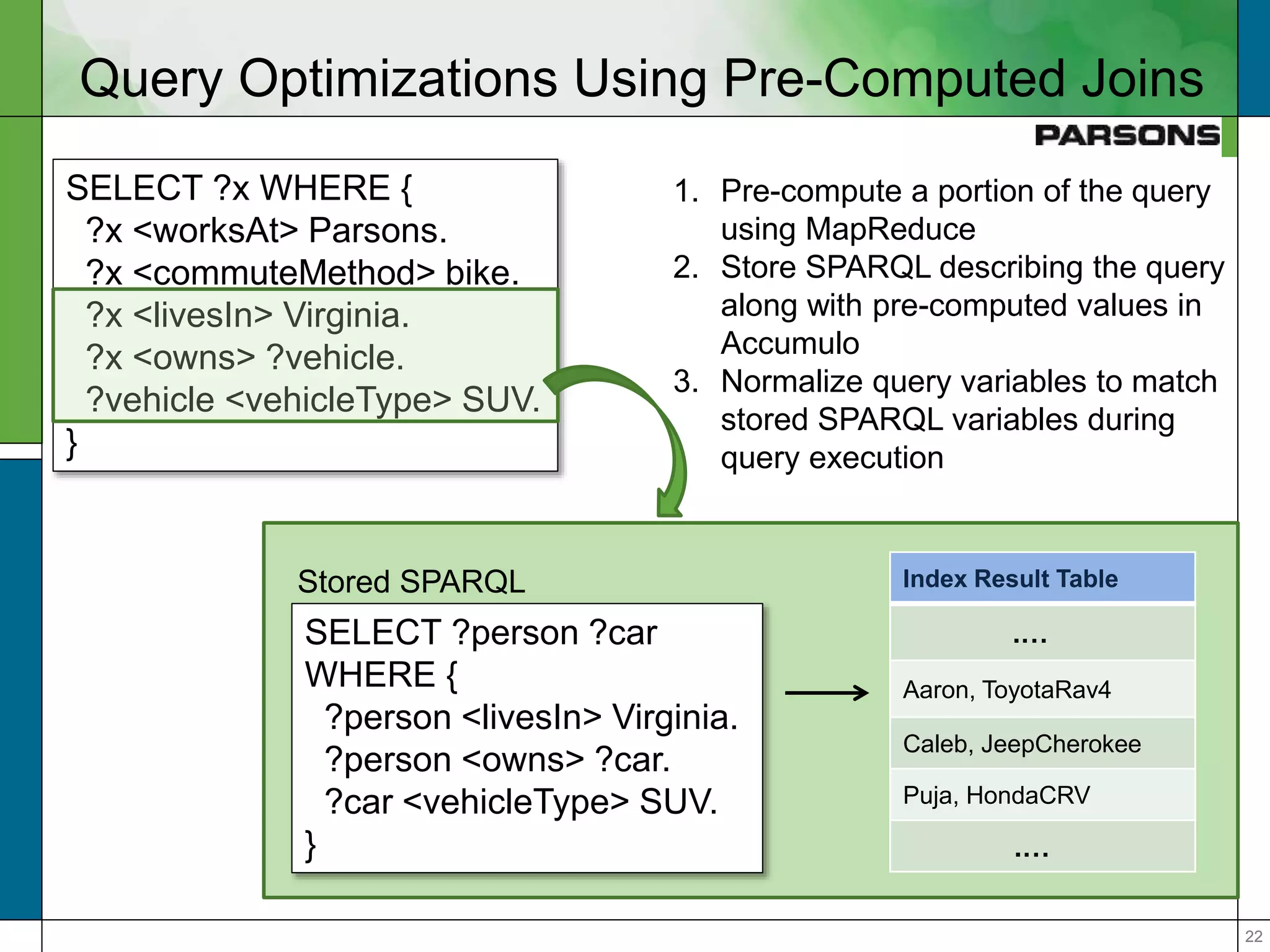
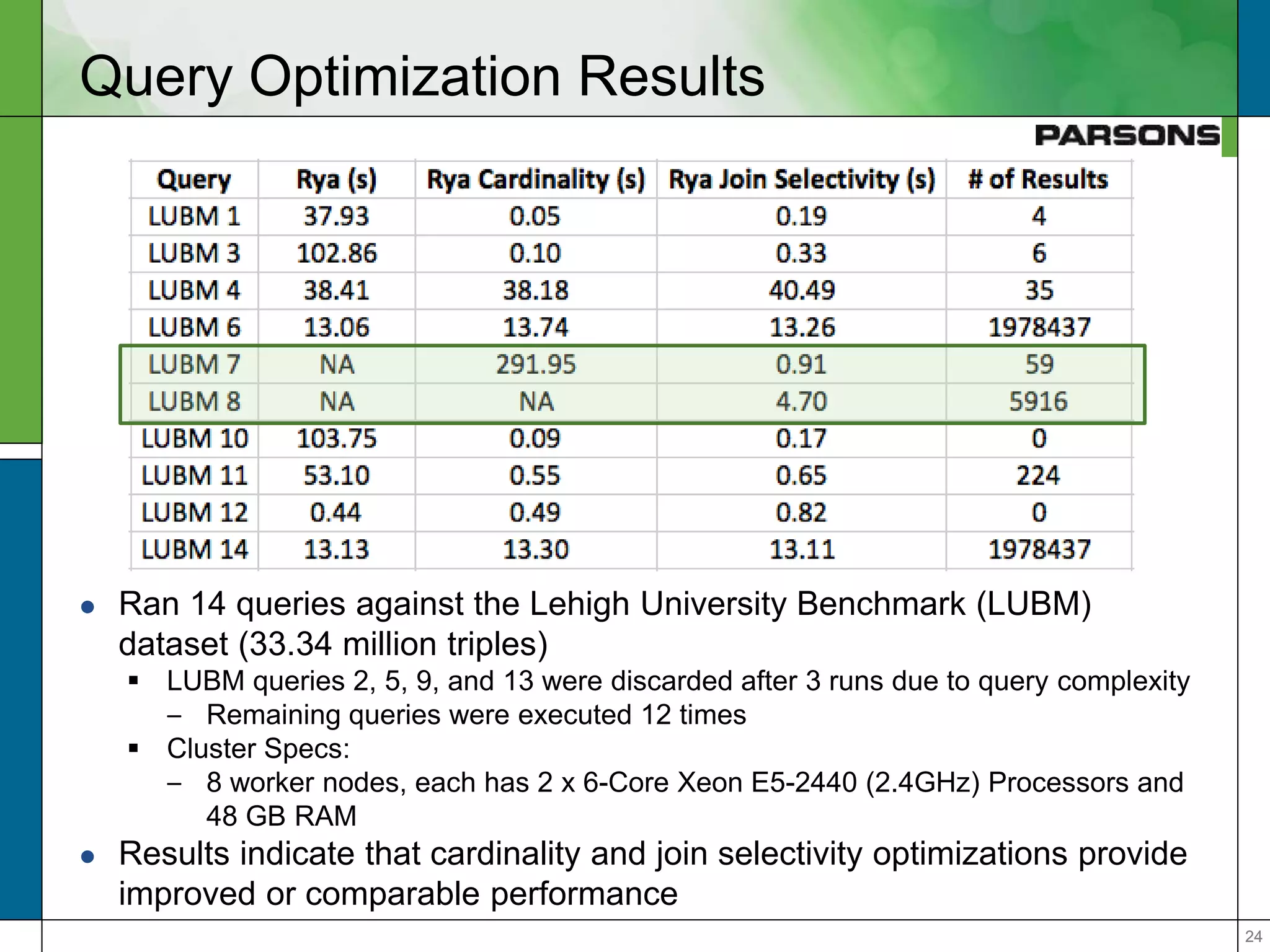









The document outlines optimizations for real-time graph queries in Rya, a triplestore built on Accumulo, focusing on improving query execution through cardinality estimation and join selectivity. It highlights challenges in scalability and responsiveness due to large datasets and explores techniques such as pre-computed joins and optimized query planning to enhance performance. Results indicate that these optimizations significantly improve query response times, particularly for complex queries.


































































