Download as PDF, PPTX




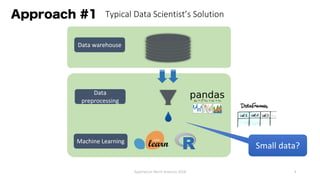
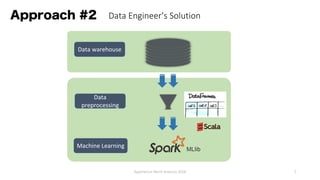
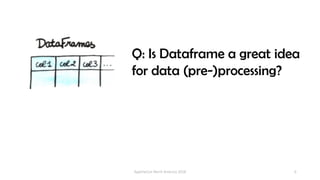

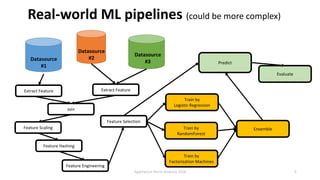


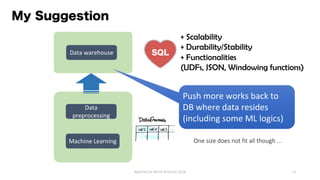







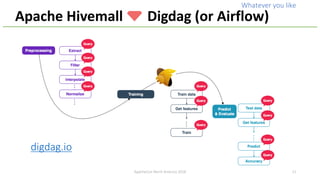

The document discusses the idea behind Apache Hivemall, which is an open-source machine learning library that allows running machine learning on large datasets stored in data warehouses. It addresses concerns about scalability, data movement, and tools when performing machine learning on big data. It suggests pushing more machine learning logic, like data preprocessing, back to the database where the data resides for better performance and stability. Hivemall provides machine learning functions that can be used within SQL queries on Hadoop systems like Hive and Spark SQL, enabling parallel and distributed machine learning.







































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)















