Download as PDF, PPTX







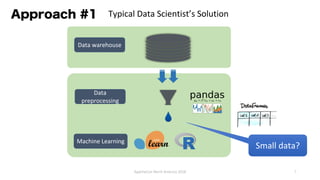
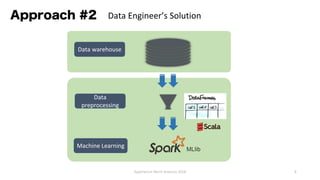
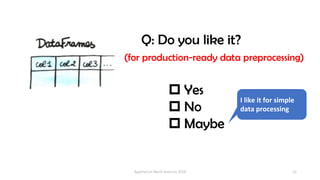






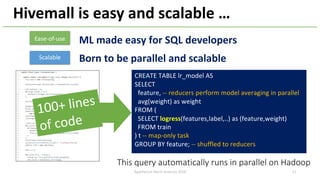
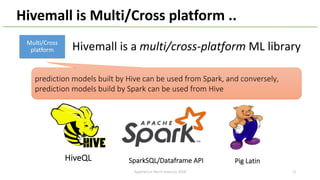
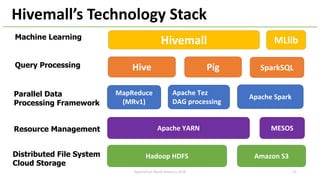








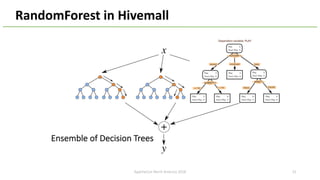



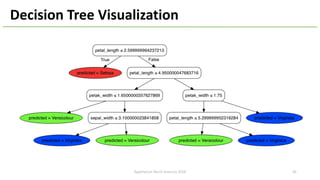
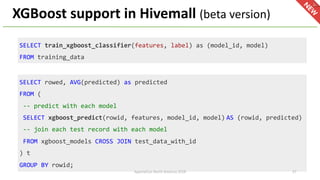


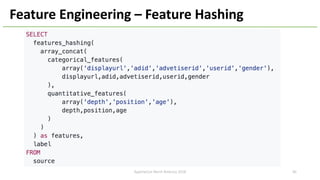





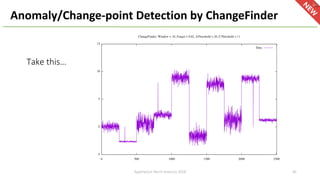
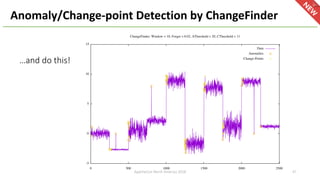


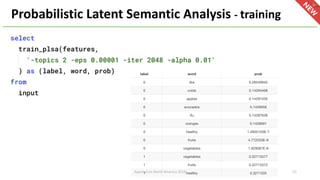
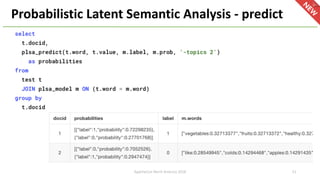




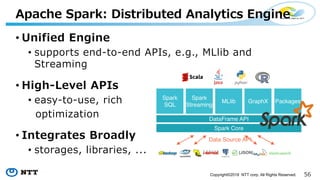


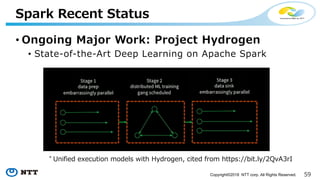
















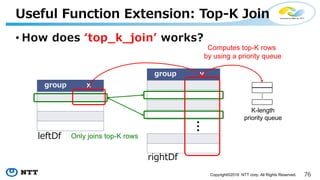
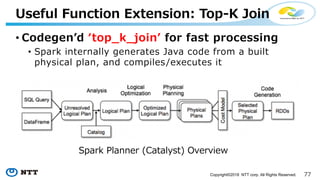




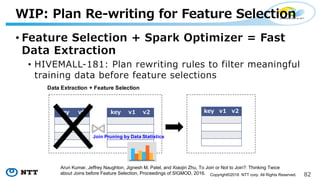



The document provides an overview of Apache Hivemall v0.5.0, a scalable machine learning library for Hive and Spark, highlighting its features, enhancements, and planned updates. Key new offerings in this version include algorithms for anomaly detection, topic modeling, and improved integration with Spark, along with plans for future updates in v0.5.2. The presentation discusses the library's functionality, addressing concerns about data preprocessing and providing insights into various machine learning algorithms supported by Hivemall.























































































