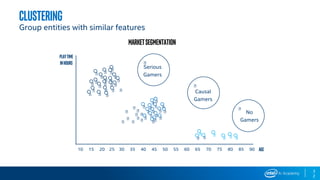
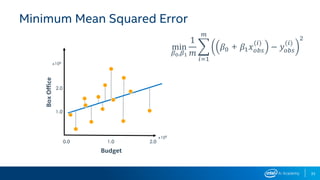
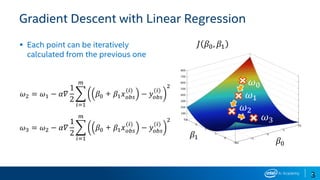
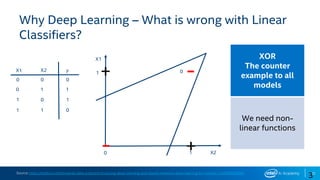
Download as PDF, PPTX
































![LeNet-5
How many total weights in the network?
Conv1: 1*6*5*5 + 6 = 156
Conv3: 6*16*5*5 + 16 = 2416
FC1: 400*120 + 120 = 48120
FC2: 120*84 + 84 = 10164
FC3: 84*10 + 10 = 850
Total: = 61706
Less than a single FC layer with [1200x1200] weights!
Note that Convolutional Layers have relatively few weights.
52](https://image.slidesharecdn.com/msbuild2019-190510214349/85/Microsoft-Build-2019-Intel-AI-Workshop-52-320.jpg)
















![performanceGUIDE
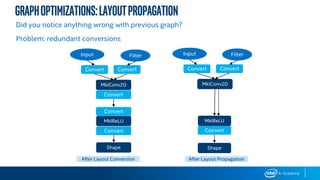
Setting the threading model correctly
We provide best settings for popular CNN models. (https://ai.intel.com/tensorflow-optimizations-
intel-xeon-scalable-processor)
os.environ["KMP_BLOCKTIME"] = "1"
os.environ["KMP_AFFINITY"] = "granularity=fine,compact,1,0"
os.environ["KMP_SETTINGS"] = "0"
os.environ["OMP_NUM_THREADS"] = “56"
https://www.tensorflow.org/performance/performance_
guide#tensorflow_with_intel_mkl_dnn
Example setting MKL variables with python os.environ :](https://image.slidesharecdn.com/msbuild2019-190510214349/85/Microsoft-Build-2019-Intel-AI-Workshop-83-320.jpg)





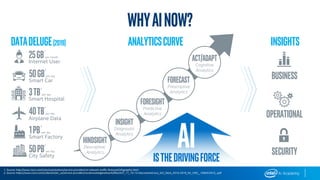
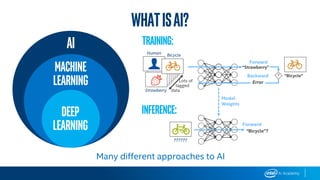
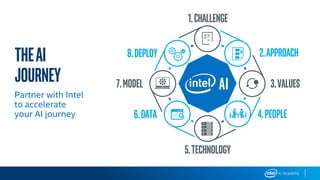
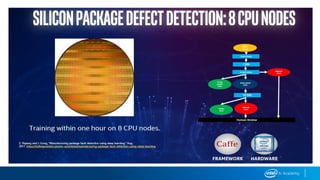
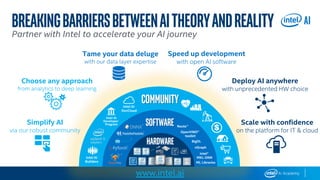
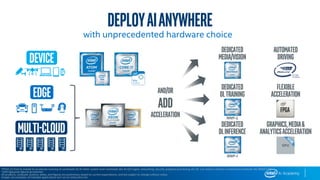
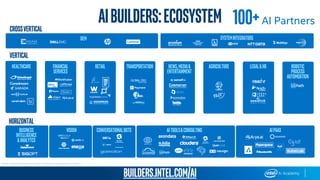
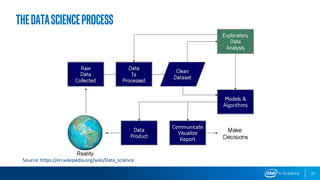
This document provides an overview of Intel’s products, services, and technologies in AI, including performance data and case studies highlighting the application of machine learning and deep learning. It emphasizes the importance of consulting the latest information for accurate performance and specifications, as they are subject to change. Intel encourages collaboration and offers various resources for developers and partners to accelerate AI implementation across diverse sectors.




















































































