Download as PDF, PPTX





![ScaleYourInnovation 9
Adaptingtoinnovation
Many efforts to improve efficiency
▪ Batching
▪ Reduce bit width
▪ Sparse weights
▪ Sparse activations
▪ Weight sharing
▪ Compact network
SparseCNN
[CVPR’15]
Spatially SparseCNN
[CIFAR-10 winner ‘14]
Pruning
[NIPS’15]
TernaryConnec
t [ICLR’16]
BinaryConnect
[NIPS’15]
DeepComp
[ICLR’16]
HashedNets
[ICML’15]
XNORNet
SqueezeNet
I
X
W
=
···
···
O
3 2
1 3
13
1
3
Shared Weights
LeNet
[IEEE}
AlexNet
[ILSVRC’12}
VGG
[ILSVRC’14}
GoogleNet
[ILSVRC’14}
ResNet
[ILSVRC’15}
I W O
2
3](https://image.slidesharecdn.com/aisupercomputecrashcourse-oisv2-181115021808/85/AI-Crash-Course-Supercomputing-9-320.jpg)
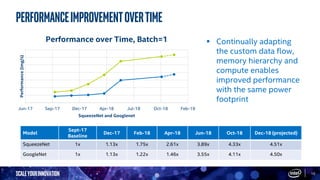

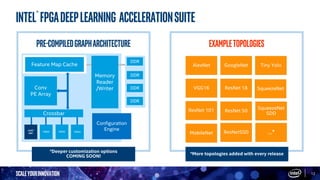







The document discusses the advantages of Intel FPGAs in accelerating AI workloads across various applications, emphasizing their flexibility and low latency for deep learning tasks. It introduces the OpenVINO toolkit, enabling seamless deployment of AI models on Intel FPGAs, and highlights performance improvements in different neural network architectures over time. Additionally, it presents use cases demonstrating the effectiveness of FPGAs in real-time AI inferencing and large-scale image processing.























































































