Downloaded 489 times


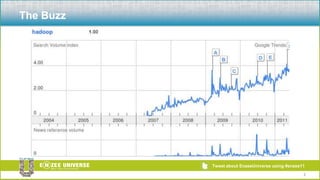


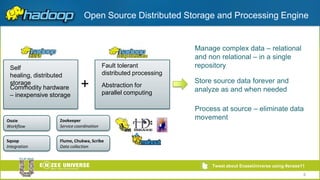
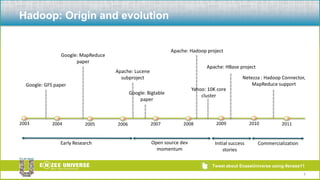

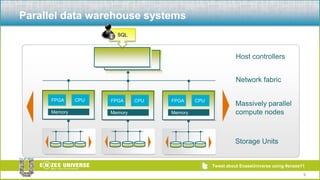
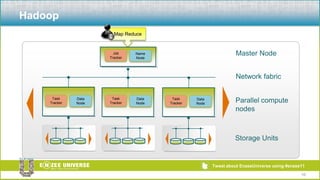
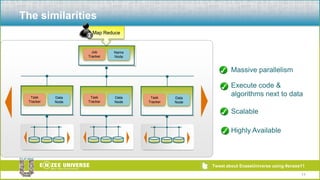
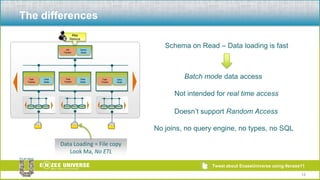



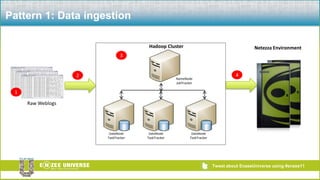
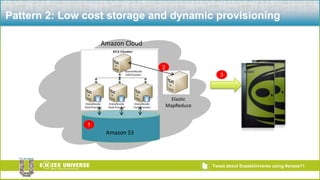

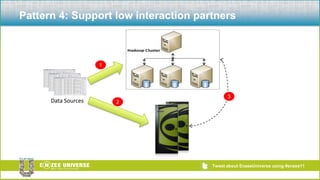
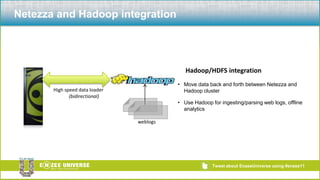


The document discusses the relationship between Hadoop and Netezza, framing them as complementary technologies rather than competitors. It outlines the evolution of both systems, their functionalities, and the contexts in which they coexist, such as data ingestion and analysis. Key use cases for their integration include handling unstructured data, low-cost storage, and the need for flexible data processing architectures.

























![[db tech showcase Tokyo 2017] C34: Replacing Oracle Database at DBS Bank ~Ora...](https://cdn.slidesharecdn.com/ss_thumbnails/replacingoracledatabaseatdbsbankdbtechshowcasetokyosept2017-170911075631-thumbnail.jpg?width=640&height=640&fit=bounds)
















































