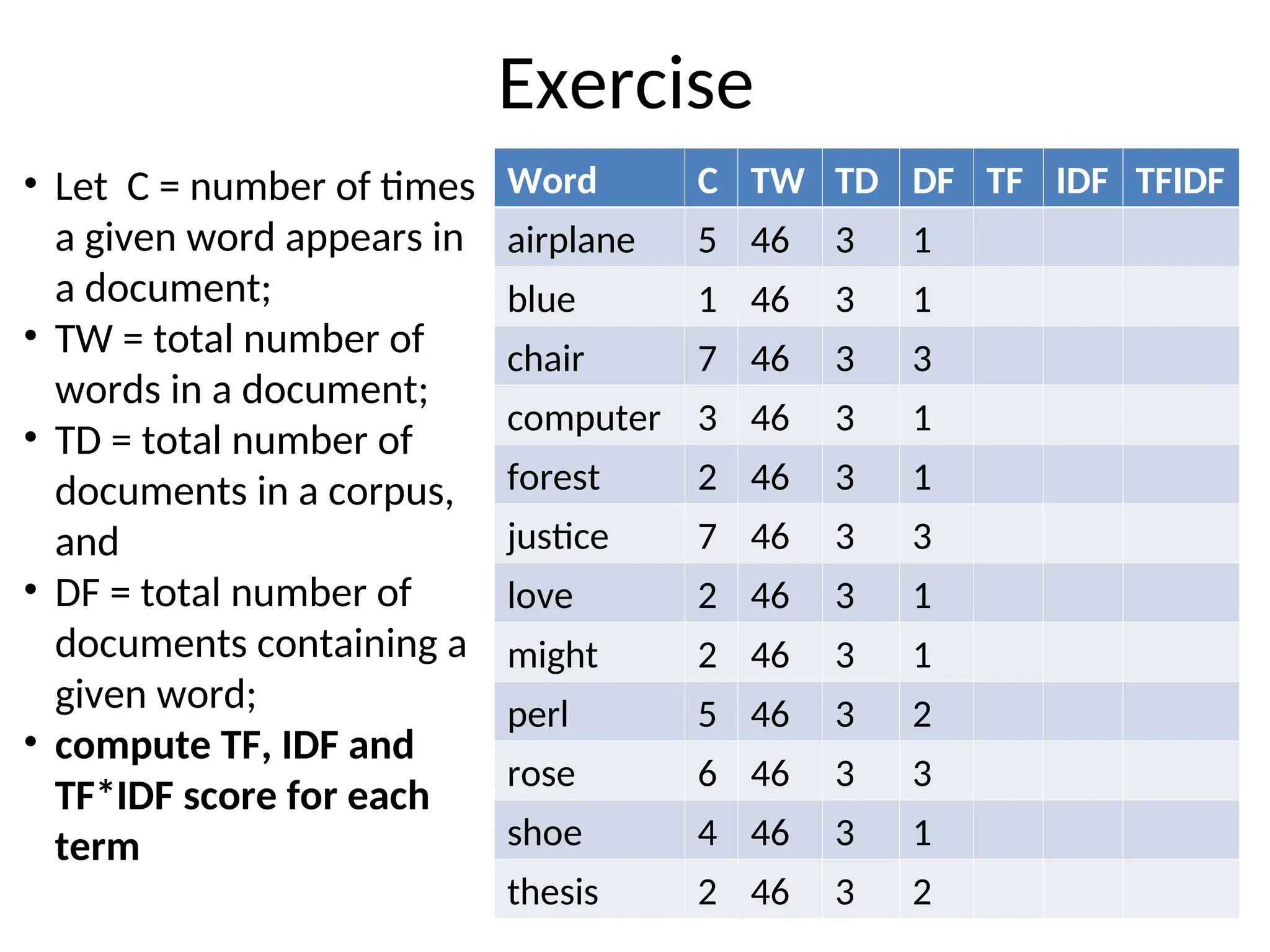
The document discusses term weighting and similarity measures in information retrieval. It explains the significance of term-document matrices, binary and non-binary weights, as well as term frequency (tf), inverse document frequency (idf), and tf*idf weighting techniques to improve document relevance ranking. Additionally, it covers similarity measures such as Euclidean distance, inner product, and cosine similarity for evaluating the relevance between documents and queries.












![Computing TF-IDF: An Example
• Assume collection contains 10,000 documents and statistical
analysis shows that document frequencies (DF) of three
terms are: A(50), B(1300), C(250). And also term
frequencies (TF) of these terms are: A(3), B(2), C(1).
Compute TF*IDF for each term?
A: tf = 3/3=1.00; idf = log2(10000/50) = 7.644; tf*idf = 7.644
B: tf = 2/3=0.67; idf = log2(10000/1300) = 2.943; tf*idf = 1.962
C: tf = 1/3=0.33; idf = log2(10000/250) = 5.322; tf*idf = 1.774
• Query is also treated as a short document and also tf-idf
weighted.
wij = (0.5 + [0.5*tfij ])* log2 (N/ dfi)
13](https://image.slidesharecdn.com/3termweighting-240918100415-ac7ff691/75/information-retrieval-term-Weighting-ppt-13-2048.jpg)








![Example 1: Computing Cosine Similarity
98
.
0
42
.
0
64
.
0
]
)
7
.
0
(
)
2
.
0
[(
*
]
)
8
.
0
(
)
4
.
0
[(
)
7
.
0
*
8
.
0
(
)
2
.
0
*
4
.
0
(
)
,
(
2
2
2
2
2
D
Q
sim
• Let say we have query vector Q = (0.4, 0.8); and also
document D1 = (0.2, 0.7). Compute their similarity
using cosine?](https://image.slidesharecdn.com/3termweighting-240918100415-ac7ff691/75/information-retrieval-term-Weighting-ppt-23-2048.jpg)




































































