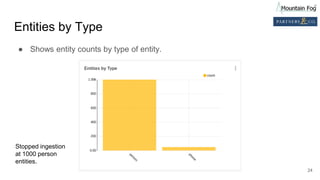
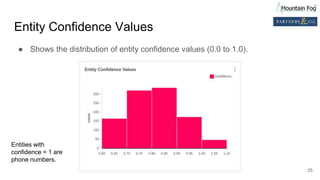
Downloaded 10 times











![NLP Operations - An Example
George Washington was president. He was the first president.
1. Language = eng
2. Sentences = [“George Washington was president.”, “He was
the first president.”]
3. Tokens = {[“George”, “Washington”, “was”, “president”],
[“He”, “was”, “the”, “first”, “president”]}
4. Entities = [“George Washington”]
17](https://image.slidesharecdn.com/thurs200pmsalon9improvingorganizationalknowledgewithnaturallanguageprocessingenricheddatapipelinesje-190604213906/85/Improving-Organizational-Knowledge-with-Natural-Language-Processing-Enriched-Data-Pipelines-17-320.jpg)
![Managing the NLP Models
NLP models are stored externally and pulled by the containers from S3/HTTP
when first needed.
NLP Microservice
Containers
S3 Bucket
containing models
Models organized in storage as: s3://nlp-models/[language]/[model-type]/[model-filename]
18](https://image.slidesharecdn.com/thurs200pmsalon9improvingorganizationalknowledgewithnaturallanguageprocessingenricheddatapipelinesje-190604213906/85/Improving-Organizational-Knowledge-with-Natural-Language-Processing-Enriched-Data-Pipelines-18-320.jpg)



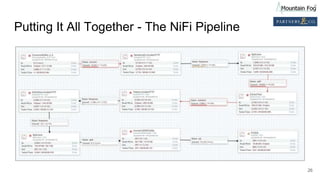
![The NiFi Flow
27
George Washington was president. He was the first president.
George Washington was president. He was the first president.
[“George”, “Washington”, “was”, “president”] [“He”, “was”, “the”, “first”, “president”]
[“George Washington”]
{entity: text: “George Washington”, confidence: 0.9}
INSERT INTO entities (TEXT, CONFIDENCE) VALUES (“George
Washington”, 0.9)
One entity sent to the database.
Attribute - eng
[]
{}
Nothing sent to database.](https://image.slidesharecdn.com/thurs200pmsalon9improvingorganizationalknowledgewithnaturallanguageprocessingenricheddatapipelinesje-190604213906/85/Improving-Organizational-Knowledge-with-Natural-Language-Processing-Enriched-Data-Pipelines-27-320.jpg)






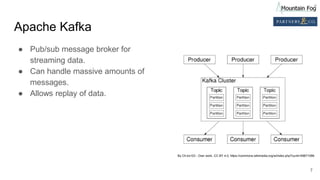
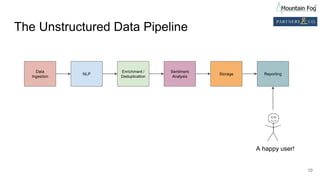
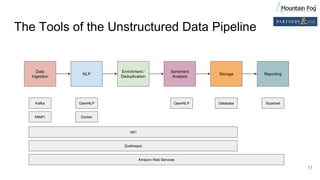
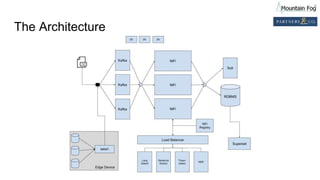
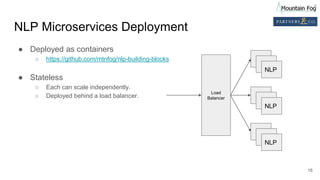
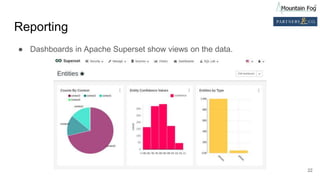
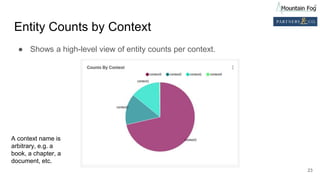
This document summarizes a presentation on improving organizational knowledge with natural language processing and enriched data pipelines. The system discussed ingests unstructured text data from various sources using Apache Kafka and Apache NiFi/MiNiFi. The data is then processed by Apache OpenNLP microservices to extract entities, sentences, tokens and perform sentiment analysis. The extracted structured data is stored in a database and Elasticsearch for visualization in Apache Superset dashboards. The system is designed to be scalable, extensible and repeatable using infrastructure as code deployed on Amazon Web Services.






















































































