The document proposes a real-time architecture using Apache Storm and Apache Kafka to apply natural language processing (NLP) tasks to streams of text data. It allows developers to inject NLP modules from different programming languages in a distributed, scalable, and low-latency manner. An experiment was conducted using OpenNLP, Fasttext and SpaCy modules on Bahasa Malaysia and English text, and Apache Storm achieved the lowest latency compared to other frameworks.
![Real-time Text Stream Processing: A Dynamic and Distributed
NLP Pipeline
Mohammad Arshi Saloot
MIMOS Berhad
Kuala Lumpur, Malaysia
+60187007981
arshi.saloot@yahoo.com
Duc Nghia Pham
MIMOS Berhad
Kuala Lumpur, Malaysia
address
+60389955000
nghia.pham@mimos.my
ABSTRACT
In recent years, the need for flexible and instant Natural Language
Processing (NLP) pipelines becomes more crucial. The existence
of real-time data sources, such as Twitter, necessitates using real-
time text analysis platforms. In addition, due to the existence of a
wide range of NLP toolkits and libraries in a variety of
programming languages, a streaming platform is required to
combine and integrate different modules of various NLP toolkits.
This study proposes a real-time architecture that uses Apache
Storm and Apache Kafka to apply different NLP tasks on streams
of textual data. The architecture allows developers to inject NLP
modules to it via different programming languages. To compare
the performance of the architecture, a series of experiments are
conducted to handle OpenNLP, Fasttext, and SpaCy modules for
Bahasa Malaysia and English languages. The result shows that
Apache Storm achieved the lowest latency, compared with
Trident and baseline experiments.
CCS Concepts
Computer systems organization ~ Real-time systems ~ Real-
time system architecture
Keywords
Real-time, Natural Language Processing, Streaming, Pipeline,
Kafka, Storm
1. INTRODUCTION
NLP toolkits often offer the following NLP components:
tokenization, part-of-speech (PoS) tagging, chunking, named
entity recognition (NER), and sentiment analysis. Currently, there
is a wide range of NLP tools and libraries in different
programming programs, and there is an ongoing competition
between them in terms of accuracy and performance. For example,
in 2017, an experiment is performed to compare in which we
applied four state-of-the-art NLP libraries to publicly available
software artifacts, namely Google’s SyntaxNet, Stanford
CoreNLP suite, NLTK Python library, and spaCy [1]. They
proved that NLTK achieved the highest accuracy for tokenization
among the other toolkits while its accuracy of PoS tagger is the
lowest results [1]. Therefore, because of this diversity of software
artifacts in NLP field, linking and merging NLP modules with
different techniques into an NLP pipeline is an important
phenomenon for NLP engineers and researchers [2].
A sheer volume of textual data is generated daily in many
domains, such as medicine, sports, legal, education, etc. For
example, a law institute generates with a large amount of research
notes, legal transaction documents, emails, reference books, etc.
Thus, NLP becomes an essential factor to get the best results out
of the descriptive or predictive analysis. As a result, AI and NLP
are a vital tool for legal practice to contribute to the growth of
technologies that assist lawyers or “think like a lawyer”.
Therefore, traditional data processing techniques are substituted
with the big data analytics approaches to solve real-life problems
[3].
Big-data (i.e. batch processing), focuses on batch, a
posteriori processing. Recently, the explosion of sensors and
applications needing immediate actions, interest are shifted
towards Fast-data (i.e. stream processing), focusing on real-time
processing. Batch big-data processing techniques encounters
many challenges when it comes to analyzing real-time stream of
data. Data streaming is useful for the types of data sources that
send data in small sizes (often in kilobytes) in a continuous flow
as the data is generated. This may include a wide variety of data
sources such as telemetry, log files, e-commerce transactions,
social network data, or geospatial services. Thus, many real-time
generated data sources, such as Tweets, need real-time data
analysis pipeline. The output of real-time pipelines should be
generated with low-latency and any incoming data must be
processed within seconds or milliseconds [4]. Therefore, research
efforts should be addressed towards developing scalable
frameworks and algorithms that will accommodate data stream
computing mode, effective resource allocation strategy and
parallelization issues to cope with the ever-growing size and
complexity of data [4]. The objectives of this work are examining
different frameworks in order to propose a platform to achieve
following aims:
• To encapsulate NLP modules: adding and removing
multilingual NLP modules to the pipeline without disturbing the
architecture of the system.
• To compute distributedly: scalable by adding or
removing parallel processes as well as worker nodes.
• To process real-time streams: real-time processing and
analysis of incoming streams of textual data with different lengths
and frequencies.
• To have a configurable topology: manipulate the
processing topology (i.e. workflow or network of implemented
NLP modules) at runtime without interrupting the running
services.](https://image.slidesharecdn.com/real-timetextstreamprocessing-adynamicanddistributednlppipeline-211207083120/85/Real-time-text-stream-processing-a-dynamic-and-distributed-nlp-pipeline-1-320.jpg)
![• To allow user interaction with the system: Provide
RESTful APIs to end users.
Section 2 reflects on the state-of-the-art NLP systems and libraries
as well as distributed stream processing platforms. Section 3
describes the experiment of this work. Finally, Section 4
summarizes the paper and suggests future research directions.
2. LITERATURE REVIEW
2.1 NLP Toolkits
In 2014, a short survey of NLP toolkits [5] recognized NLTK [6]
as the most well-known and comprehensive NLP toolkit. NLTK is
written in Python and provides essential NLP modules, which
includes tokenization, splitting, statistical analysis of corpora,
classification and clustering. Although NLTK does not provide
any neural network tool, it can be fused with Gensim [7] to
provide word embedding.
Apache OpenNLP [8] offers pre-trained models for the most
common NLP modules, such as tokenization, sentence
segmentation, PoS tagging, NER, chunking, parsing, and co-
reference resolution, for a variety of languages. OpenNLP is an
Apache licensed cross-platform Java library, which uses machine
learning methods.
Tokenization, sentence splitting, PoS tagging, NER, parsing,
sentiment analysis and temporal expression tagging as well as
word embedding are arranged in Stanford NLP Toolkit [9], which
is written in the Java programming language. OpenNLP and
Stanford NLP use Maximum Entropy models for their PoS tagger.
Stanford NLP uses different approaches for each task. For
instance, Conditional Random Fields (CRF) are used for NER
library.
Fasttext [10], [11] and spaCy [12] are new generations of
NLP libraries that emphasis on neural networks. SpaCy is a one of
the advanced multi-language NLP library, which is written in
Python and Cython [12]. SpaCy developers put efforts on the
speed of their library to provide a suitable NLP solution for
industry and commercial applications. There are some comparison
studies to compare different NLP libraries using different domains
and datasets [13]. For example, a study in 2017 [1], found that
spaCy achieved the most promising combined accuracy of PoS
tagging and tokenizer, compared to Google’s SyntaxNet, Stanford
NLP, NLTK Python libraries, while testing with Stack Overflow
data. In addition, spaCy supports neural network modeling while
OpenNLP lacks the advance of deep learning.
In 2016, Facebook Research offered Fasttext as an open-
source NLP library. Similar to spaCy, efficiency is vital in
Fasttext. Although Fasttext is written in C++, there are available
wrappers for it in other languages such as Python and Java.
Fasttext provides pre-trained word embedding models for 294
languages. The Fasttext in considered as a generic tool in the NLP
field because it does not provide any specific NLP module, such
as such as NER and sentiment analysis. Instead, it provides a text
classification library to be used as the engine for many NLP tasks.
Finally, UIMA is the most reliable and well-known
framework to combine different tasks from different library into a
single text annotation pipeline [14]. Although UIMA itself does
not provide any NLP module, it offers flexible pipelines that can
be configured by writing an XML description or using a GUI tool.
Instead of using a specific annotation format, the annotation
formats in UIMA are interoperable using XML Metadata
Interchange (XMI), which is an interchange standard. To pass
right types of input to the next component, UIMA validates the
output formats of components based on predefined Types.
Therefore, there are many frameworks is developed based on
UIMA such as Text Imager [15].
2.2 Real-time Stream Processing Frameworks
This study compares the main features of six most popular
stream processing frameworks, namely Spark Streams [16], Flink
[17], Akka Streams [18], Kafka Streams [19], Samza [20], and
Apache Storm [21]. Spark Streams is a library in Spark
framework to process continuously flowing streams data, which is
powered by Spark RDD. Flink provides stream processing for
large-volume data, and it also lets you handle batch analytics, with
one technology. Akka Streams are an implementation of the
Reactive Streams specification, build on top of Akka Actors to do
asynchronous, non-blocking stream processing. Apache Samza is
another open-source near-realtime, asynchronous computational
framework for stream processing developed in Scala and Java.
Apache Storm accepts tons of data coming in extremely fast,
possibly from various sources, analyze it, and publish real-time
updates to some other places, without storing any actual data.
Apache offers two different streaming frameworks with similar
names: 1) Kafka Streams is a library to write complex logic for
your stream processing jobs, 2) Apache Kafka (known as Kafka
Topics) is a distributed streaming platform [22]. Kafka Streams
API is used to develop stream applications, which may consume
from Kafka Topics and produces back into Kafka Topics. Results
from any of these tools are usually written back to new Kafka
topics for downstream consumption, as shown in Figure 1.
Figure 1. Kafka Topics
2.2.1 Kafka Topics
Apache Kafka is a distributed logging, which stores
messages sequentially. In Kafka terminology, consumers
consume/read data from some topics, and producers produce/write
data into topics. As shown in Figure 2, a Kafka cluster typically
consists of multiple brokers to maintain the load balance. The
Kafka broker election can be done by ZooKeeper [23]. Kafka
Kafka
Topics
Flink
Spark
Streams
Akka Streams
Samza
Appache
Storm
Kafka
Streams](https://image.slidesharecdn.com/real-timetextstreamprocessing-adynamicanddistributednlppipeline-211207083120/85/Real-time-text-stream-processing-a-dynamic-and-distributed-nlp-pipeline-2-320.jpg)
![provides high scalability and resiliency, so it is an excellent
integration tool between data producers and consumers. As
depicted in Figure 3, peer-to-peer spaghetti integration quickly
becomes unmanageable as the number of services grows.
Therefore, Kafka Topics provide a single backbone which is used
by all services. Although Kafka is not basically a queue, it can be
utilized as FIFO queue. Producers always write to the end of the
log, consumers can read in the log offset that they want to read
from the beginning or ending of the queue [22].
Figure 2. Kafka Architecture
Figure 3. Peer-to-peer Architecture
2.2.2 Distributed Processing Comparison
There are three categories of the reliability of message delivery:
• At-most-once delivery: for each input message, that
message is delivered zero or one time; in other words, a message
may be lost.
• At-least-once delivery: for each input message,
potentially multiple attempts are made at delivering it; in other
words, a message may be duplicated but not lost.
• Exactly-once delivery: for each input message, one
delivery is made to the recipient; in other words, the message can
neither be lost nor duplicated.
Kafka Topics, Kafka Streams, Spark Streams, Apache Storm, and
Flink support exactly-once and at-least-once delivery semantics.
However, Akka Streams and Samza are unable to guarantee
exactly-once delivery, as shown in Table 1.
Spark Streams and Flink are similar and often compared with
each other because they run as distributed services to run any
submitted jobs. They provide similar, very rich analytics, based on
Apache Beam. Apache Beam [24] is an advanced unified
programming model that implements batch and streaming data
processing jobs that run on any beam runners.
Spark Streams and Flink can manage all the issues of
scheduling processes, etc. After submitting jobs to run, they
handle scalability, failover, load balancing, etc. Another
advantage of Spark Streams and Flink is that they possess a big
community and ongoing updates and improvements because they
widely accepted by big companies at scale. A drawbacks of Spark
Streams and Flink is their restricted programming model. Jobs
should be written using their APIs that conform to their
programming model. Furthermore, integration with other services
usually requires that you run the engines separately from the
microservices and exchange data through Kafka topics or other
means. This adds some latency and more running applications at
the system level. In addition, the overhead of these systems makes
them less ideal for smaller data streams. In Spark Streams, data is
captured in fixed time intervals, then processed as a “mini batch.”
The drawback is longer latencies are required (100 milliseconds
or longer for the intervals).
Akka Streams, Kafka Streams, Samza, and Storm are similar
because they run as libraries that can be embedded in
microservices, providing greater flexibility in how to integrate
analytics with other processes. Akka Streams are very flexible in
terms of deployment and configuration options, compared to
Spark and Flink. In Akk Streams, there are many flexibility and
interoperation capabilities. When Akka Streams use Kafka Topics
to exchange data, consumer lag should be watched carefully (i.e.,
queue depth), which is a source of latency. Figure 4 shows the
spectrum of microservices. Microservices are not always record
oriented. It is a spectrum because we might take some events and
also route them through a data pipeline. Compared to Kafka
Streams, Akka Streams are more generic microservice oriented
and less data-analytics oriented. Although both Akka and Kafka
Streams can cover most of the spectrum, Akka emerged in the
world of building Reactive microservices, and Kafka Streams are
effectively a dataflow API.
Broker 1
Producers Consumers
Producers
Producers
Consumers
Consumers
Broker 2
Broker 3
Multiple Kafka Broker
ZooKeeper
Services Service 1
Services
Services
Service 2
Service 3
Producers Consumers](https://image.slidesharecdn.com/real-timetextstreamprocessing-adynamicanddistributednlppipeline-211207083120/85/Real-time-text-stream-processing-a-dynamic-and-distributed-nlp-pipeline-3-320.jpg)

![Figure 6. Apache Storm
To parallelize the processing, all spout or bolt will be executed in
many Tasks across a Storm cluster. Executors are the processing
threads in a Storm worker node to run one or more Tasks of the
same Spout/Bolt. Figure 6 displays a topology into a topology
with two working machines. It contains four threads (Executors),
where each thread consists of two Tasks.
The number of Executors is always less than or equal to the
number of Tasks. The number of executors can be changed
without downtime while the number of Tasks is fixed. When the
number of Tasks is more than the number of Executors, the Tasks
inside an Executer are serial. For example, only four Tasks can be
active concurrently in Figure 7.
Stream grouping decides how a stream should be divided
among the bolt's tasks. Apache Storm supports eight types of
stream grouping that four of them are more important and
practical. Shuffle grouping is the most popular grouping. To
distribute data in a uniform and arbitrary way across the bolts,
shuffle grouping should be used. Field grouping controls how
each message is sent to bolts based on the content of each. All
grouping is a special grouping that send a message to all the bolts
that often is used to send signals to bolts. Global grouping
approach is used only to combine results from previous bolts in
the topology in a single bolt. The global grouping sends all the
messages to a single Task with lowest ID.
Divide-and-conquer is one of the most important phenomenon in
big-data. All batched big-data processing platforms, such as
Hadoop and Spark, use map-reduce technique which is based on
divide-and-conquer logic [26]. Trident is an extension to Apache
Storm, which provides divide-and-conquer logic for the real-time
stream processing applications [27]. Using Trident, a message can
be divided into many pieces and, and distributed between many
Storm Tasks, and merged back into one message. Therefore,
Trident offers joins, aggregations, and grouping Bolts.
Figure 7. Storm Topology
3. PROPOSED ARCHITECTURE
The importance of Kafka Topics in real-time platforms is
explained in the Section 2. As Kafka Topics provide persistent
data storage with the lowest latency, it is an essential part of our
architecture. The default behavior of Kafka consumer is to send
an acknowledgement message to the Kafka Brokers after
receiving successfully a message. However, sending an
acknowledgement can be delayed until any specific time. Figure 8
displays three different high level designs for a real-time platform.
Figure 8-a refers to the most common way of using Kafka Topics
while dealing with stream processing that is used in this work as a
baseline experiment to be compared with the proposed
architecture. Figure 8-a shows that the output of each process is
stored in Kafka Topics. It guarantees that the output of each
processor will not be lost in case of processor failure. Figure 8-b
shows that only the output of last processor will be stored in a
Topic. As the first processor sends the acknowledgement to the
input Topic, if other processors are down the message will be lost.
Figure 8-c is the best option for our platform because in case of a
failure in processors, no message will be lost. Although only the
output of last processor will be stored in a Topic, the
acknowledgement will be sent by the last processor instead of the
first one.
Thrift file Thrift Compiler
JAVA Nimbus
Python Nimbus
Ruby Nimbus
…
Supervisor (worker)
Executor Task
Task
Ta
Task
Supervisor (worker)
Executor
Executor
Executor Task Task
Task
Task
Task
Task](https://image.slidesharecdn.com/real-timetextstreamprocessing-adynamicanddistributednlppipeline-211207083120/85/Real-time-text-stream-processing-a-dynamic-and-distributed-nlp-pipeline-5-320.jpg)

![Figure 14. Apache Kafka vs Apache Storm vs Trident (Cluster)
5. CONCLUSION
The existence of many NLP modules from different sources, as
well as the increasing trend of real-time data necessitate NLP
pipelines that are flexible and rapid. There are several real-time
generated data sources that require data analysis pipeline. Another
challenge of NLP tasks is to handle multiple languages in real-
time processing. Therefore, in recent years, there was a shift of
focus from batch data processing towards stream processing.
Data streaming is one of the useful methods in sending small
size of data in a continuous flow. Although Apache Kafka is one
of the important platforms in real-time processing, it does not
provide distributed computation similar to other Stream
processing platforms such as Akka, Flink, and Apache Storm.
Apache Kafka is a vital part of stream processing because it
provides a rapid approach to store, read and write data from
persistence data sources (i.e. Kafka Topics). Between Spark
Streams, Flink, Akka Streams, Kafka Streams, Samza, and
Apache Storm, Apache Storm is selected for this study because it
is not restrained by any programming model or data structure or
programming language. Moreover, Apache Storm supports at-
least-once and exactly-once message delivery semantics and also
it is easily integrable with other data sources especially Apache
Kafka. This study examines the latency of Apache Storm while
handling NLP tasks.
A distributed architecture is proposed to handle OpenNLP,
Fasttext, and SpaCy modules for Bahasa Malaysia and English
languages. The architecture is implemented using a mixture of
Java and Python programming languages. The input and output of
the architecture are connected to Kafka Topics. A total of 100,000
messages which had at least 450 characters length with minimum
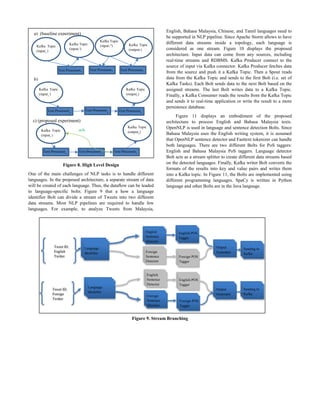
two sentences used to test our proposed architecture. The result
shows that, Apache Storm outperforms Trident and the baseline
experiment by processing 100,000 messages in 8 minutes in the
cluster mode.
ACKNOWLEDGMENTS
This research was done under Artificial Intelligence Lab, MIMOS
BERHAD.
REFERENCES
[1] F. N. A. Al Omran and C. Treude, “Choosing an NLP
Library for Analyzing Software Documentation: A
Systematic Literature Review and a Series of Experiments,”
in 2017 IEEE/ACM 14th International Conference on Mining
Software Repositories (MSR), 2017, pp. 187–197.
[2] R. de Castilho and I. Gurevych, “A broad-coverage
collection of portable NLP components for building
shareable analysis pipelines,” in Proceedings of the
Workshop on Open Infrastructures and Analysis Frameworks
for {HLT}, 2014, pp. 1–11, doi: 10.3115/v1/W14-5201.
[3] Z. Xiang, Z. Schwartz, J. H. Gerdes, and M. Uysal, “What
can big data and text analytics tell us about hotel guest
experience and satisfaction?,” Int. J. Hosp. Manag., vol. 44,
pp. 120–130, 2015, doi:
https://doi.org/10.1016/j.ijhm.2014.10.013.
[4] T. Kolajo, O. Daramola, and A. Adebiyi, “Big data stream
analysis: a systematic literature review,” J. Big Data, vol. 6,
no. 1, p. 47, 2019, doi: 10.1186/s40537-019-0210-7.
[5] L. B. Krithika and K. V. Akondi, “Survey on Various
Natural Language Processing Toolkits,” 2014.
[6] E. Loper and S. Bird, “NLTK: The Natural Language
Toolkit,” in Proceedings of the ACL-02 Workshop on
Effective Tools and Methodologies for Teaching Natural
Language Processing and Computational Linguistics -
Volume 1, 2002, pp. 63–70, doi: 10.3115/1118108.1118117.
[7] R. Rehurek and P. Sojka, “Software Framework for Topic
Modelling with Large Corpora,” in Proceedings of the LREC](https://image.slidesharecdn.com/real-timetextstreamprocessing-adynamicanddistributednlppipeline-211207083120/85/Real-time-text-stream-processing-a-dynamic-and-distributed-nlp-pipeline-9-320.jpg)
![2010 Workshop on New Challenges for NLP Frameworks,
2010, pp. 45–50.
[8] Apache Software Foundation, “openNLP Natural Language
Processing Library.” 2014.
[9] C. D. Manning, M. Surdeanu, J. Bauer, J. Finkel, S. J.
Bethard, and D. McClosky, “The Stanford CoreNLP Natural
Language Processing Toolkit,” in Association for
Computational Linguistics (ACL) System Demonstrations,
2014, pp. 55–60.
[10] P. Bojanowski, E. Grave, A. Joulin, and T. Mikolov,
“Enriching Word Vectors with Subword Information,” arXiv
Prepr. arXiv1607.04606, 2016.
[11] A. Joulin, E. Grave, P. Bojanowski, and T. Mikolov, “Bag of
Tricks for Efficient Text Classification,” arXiv Prepr.
arXiv1607.01759, 2016.
[12] M. Honnibal and I. Montani, “spaCy 2: Natural language
understanding with Bloom embeddings, convolutional neural
networks and incremental parsing,” 2017.
[13] J. D. Choi, J. Tetreault, and A. Stent, “It Depends:
Dependency Parser Comparison Using A Web-based
Evaluation Tool,” in Proceedings of the 53rd Annual
Meeting of the Association for Computational Linguistics
and the 7th International Joint Conference on Natural
Language Processing (Volume 1: Long Papers), 2015, pp.
387–396, doi: 10.3115/v1/P15-1038.
[14] G. Wilcock, “Text Annotation with OpenNLP and UIMA,”
in Proceedings of 17th Nordic Conference on Computational
Linguistics, NODALIDA, 2009, pp. 7–8.
[15] W. Hemati, T. Uslu, and A. Mehler, “Text Imager: a
Distributed UIMA-based System for NLP,” in Proceedings
of {COLING} 2016, the 26th International Conference on
Computational Linguistics: System Demonstrations, 2016,
pp. 59–63.
[16] M. Zaharia et al., “Apache Spark: A Unified Engine for Big
Data Processing,” Commun. ACM, vol. 59, no. 11, pp. 56–65,
Oct. 2016, doi: 10.1145/2934664.
[17] E. Friedman and K. Tzoumas, Introduction to Apache Flink:
Stream Processing for Real Time and Beyond, 1st ed.
O’Reilly Media, Inc., 2016.
[18] A. L. Davis, Reactive Streams in Java: Concurrency with
RxJava, Reactor, and Akka Streams, 1st ed. USA: Apress,
2018.
[19] S. Ehrenstein, “Scalability Benchmarking of Kafka Streams
Applications,” Institut für Informatik, 2020.
[20] S. A. Noghabi et al., “Samza: Stateful Scalable Stream
Processing at LinkedIn,” Proc. VLDB Endow., vol. 10, no.
12, pp. 1634–1645, Aug. 2017, doi:
10.14778/3137765.3137770.
[21] J. S. van der Veen, B. van der Waaij, E. Lazovik, W.
Wijbrandi, and R. J. Meijer, “Dynamically Scaling Apache
Storm for the Analysis of Streaming Data,” in Proceedings of
the 2015 IEEE First International Conference on Big Data
Computing Service and Applications, 2015, pp. 154–161,
doi: 10.1109/BigDataService.2015.56.
[22] N. Garg, Apache Kafka. Packt Publishing, 2013.
[23] P. Hunt, M. Konar, F. P. Junqueira, and B. Reed,
“ZooKeeper: Wait-Free Coordination for Internet-Scale
Systems,” in Proceedings of the 2010 USENIX Conference
on USENIX Annual Technical Conference, 2010, p. 11.
[24] H. Karau, “Unifying the open big data world: The
possibilities∗ of apache BEAM,” in 2017 IEEE International
Conference on Big Data (Big Data), 2017, p. 3981, doi:
10.1109/BigData.2017.8258410.
[25] A. Agarwal, M. Slee, and M. Kwiatkowski, “Thrift: Scalable
Cross-Language Services Implementation,” 2007.
[26] A. B. Patel, M. Birla, and U. Nair, “Addressing big data
problem using Hadoop and Map Reduce,” in 2012 Nirma
University International Conference on Engineering
(NUiCONE), 2012, pp. 1–5, doi:
10.1109/NUICONE.2012.6493198.
[27] A. Jain, Mastering Apache Storm: Real-Time Big Data
Streaming Using Kafka, Hbase and Redis. Packt Publishing,
2017.](https://image.slidesharecdn.com/real-timetextstreamprocessing-adynamicanddistributednlppipeline-211207083120/85/Real-time-text-stream-processing-a-dynamic-and-distributed-nlp-pipeline-10-320.jpg)












































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








