Downloaded 12 times












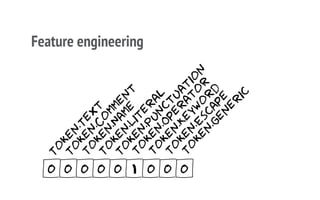


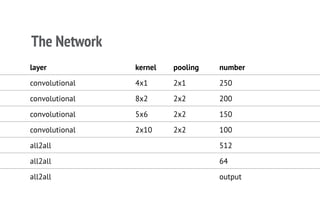



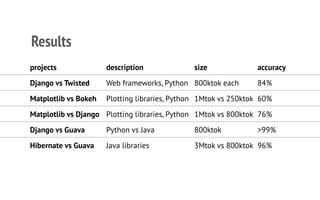








The document discusses a CNN-based approach for classifying source code abstracts, emphasizing the importance of understanding software development behavior for feature extraction. It details the feature engineering process, network architecture, and the resulting accuracy in classifying various projects across different programming languages. The conclusion suggests that the network effectively identifies internal project similarities, akin to human analysis, and outlines future work involving user clustering on GitHub.











































































































