Downloaded 114 times




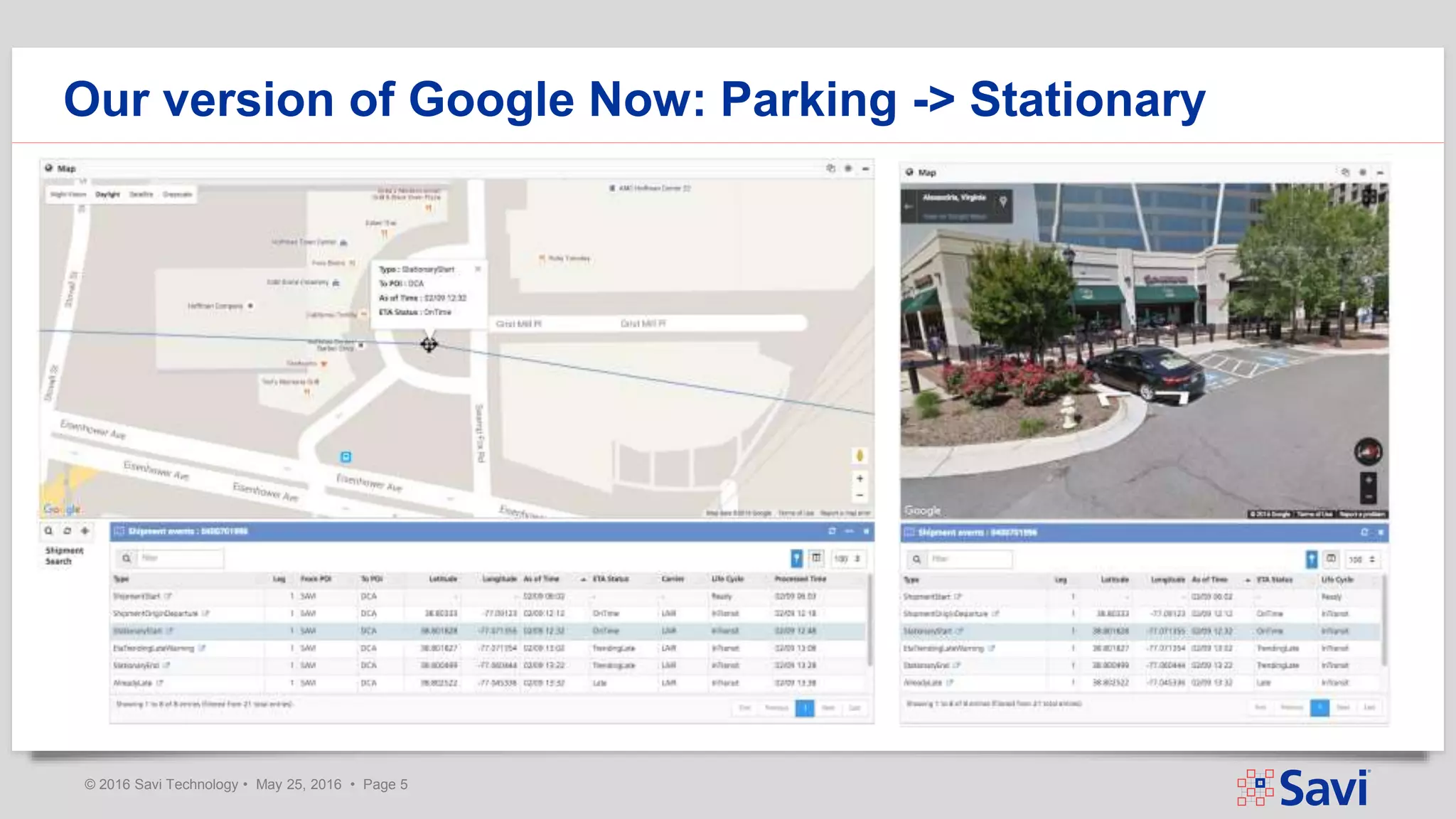
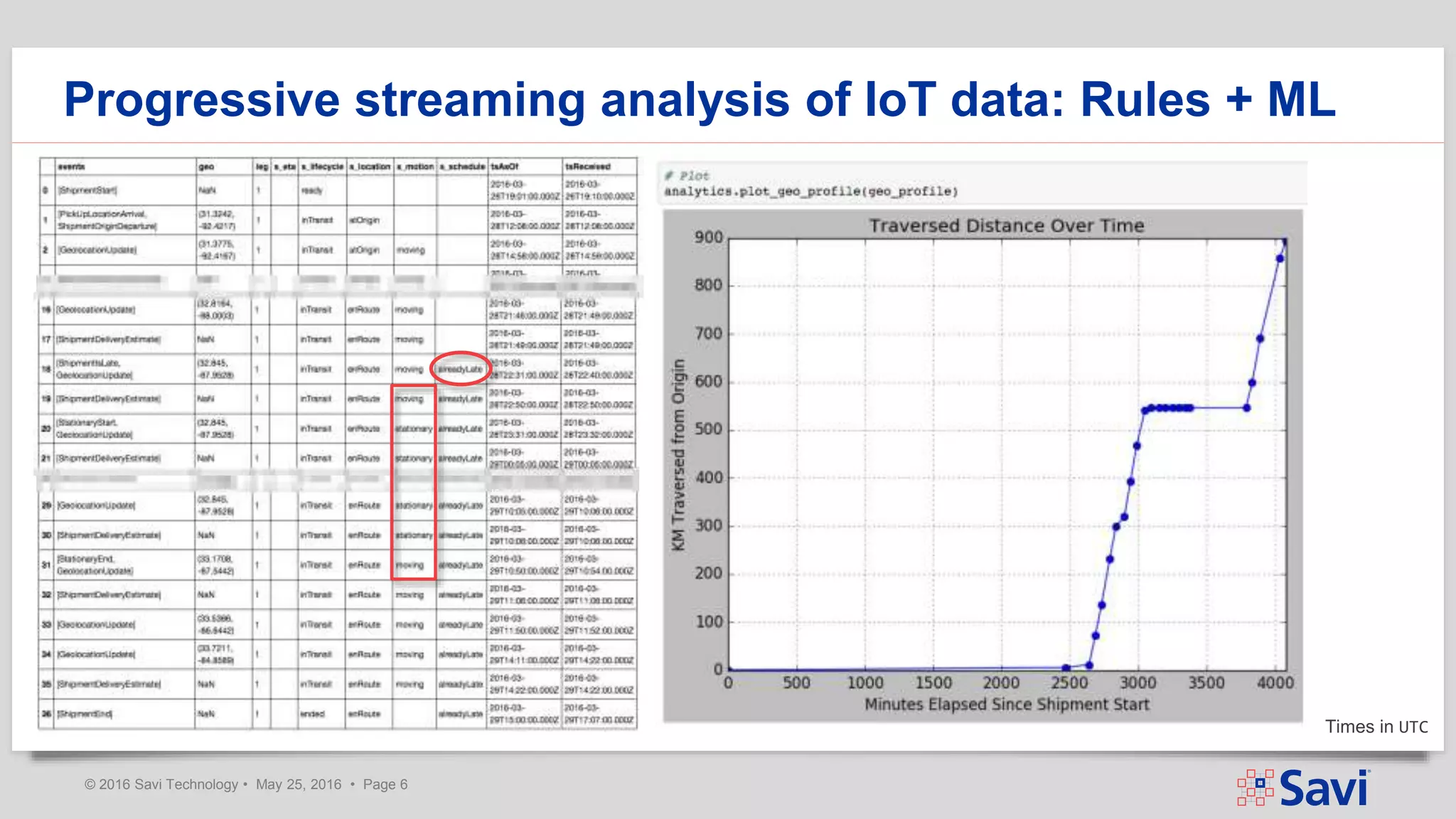
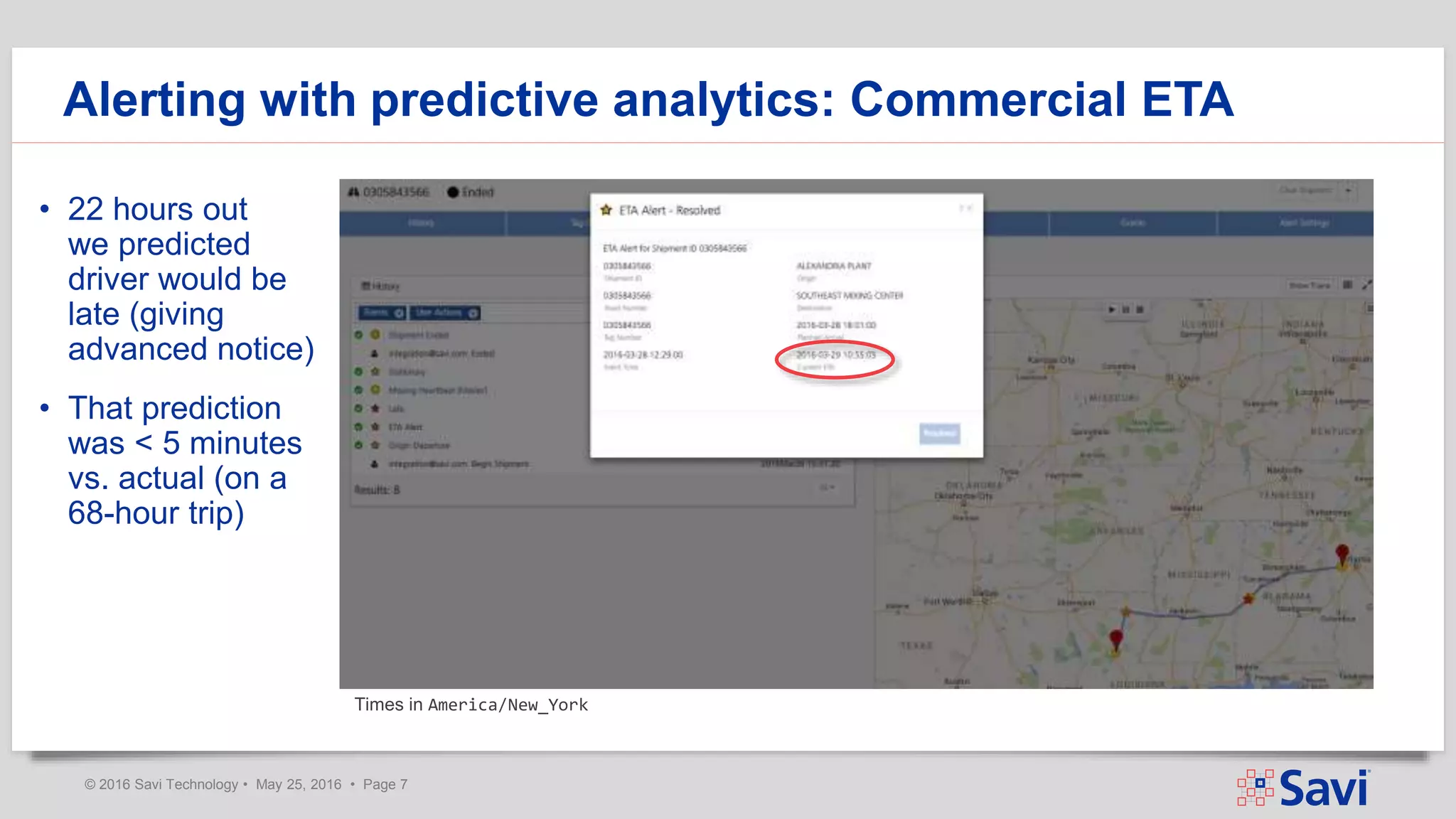
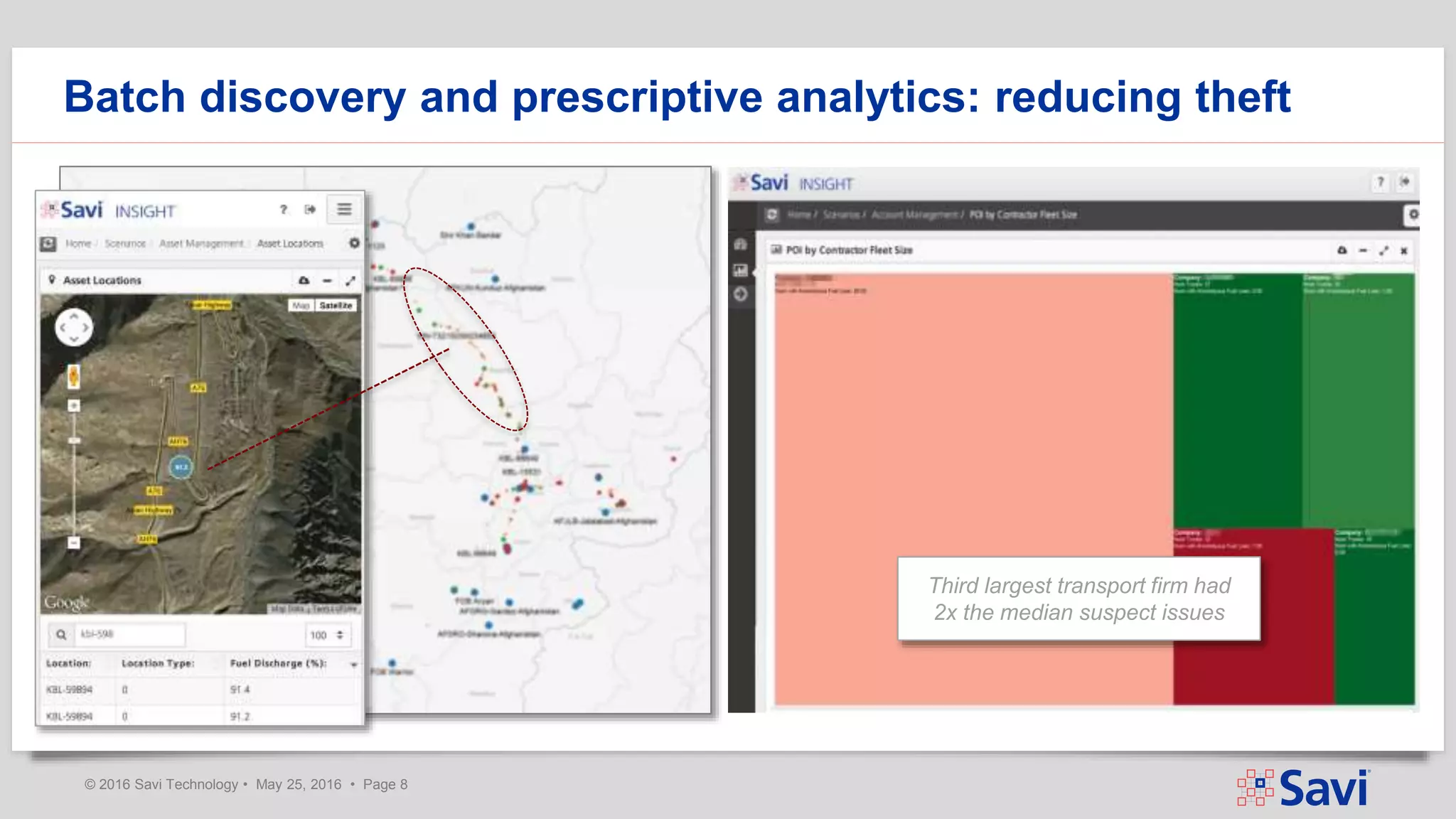


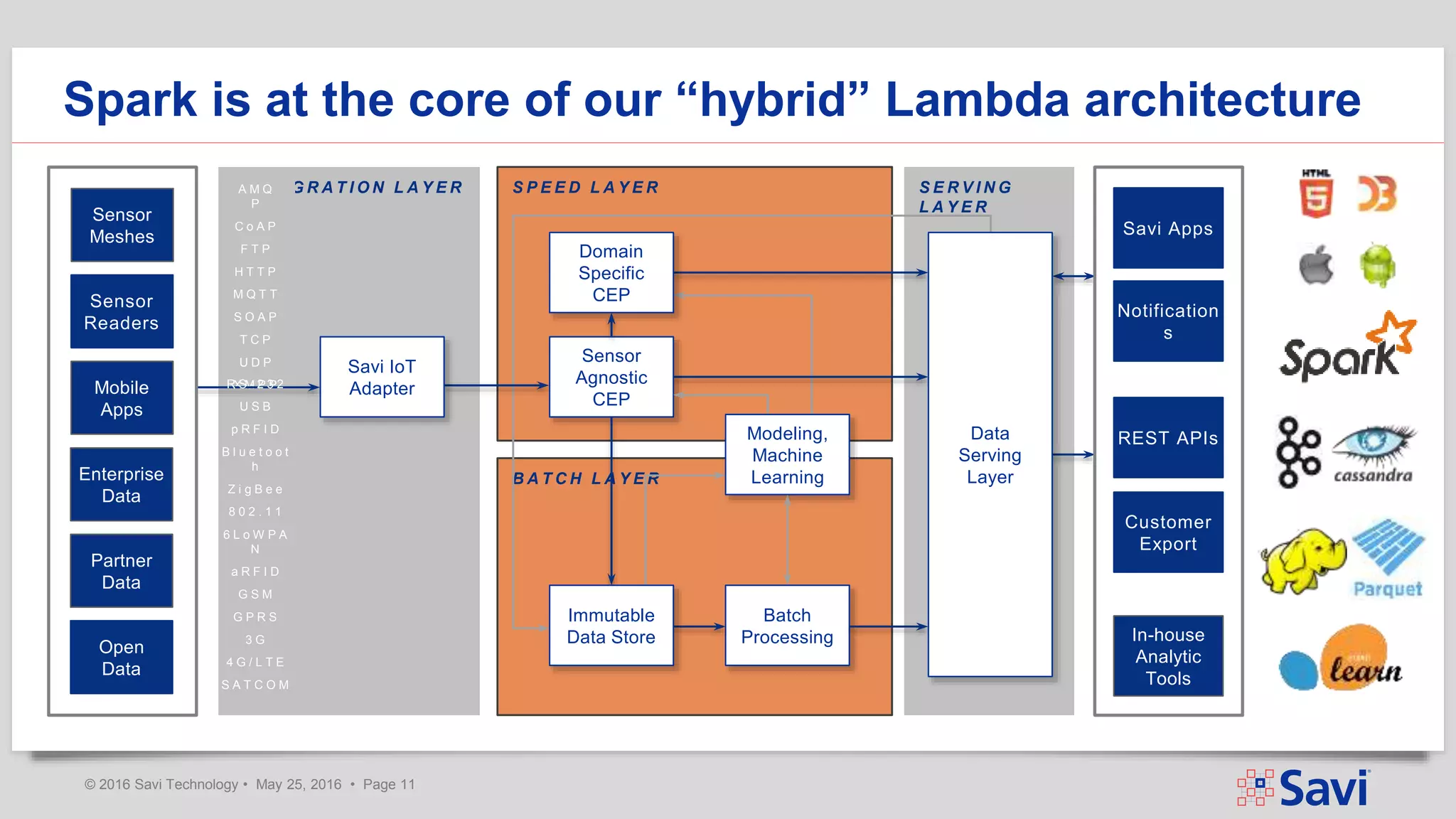
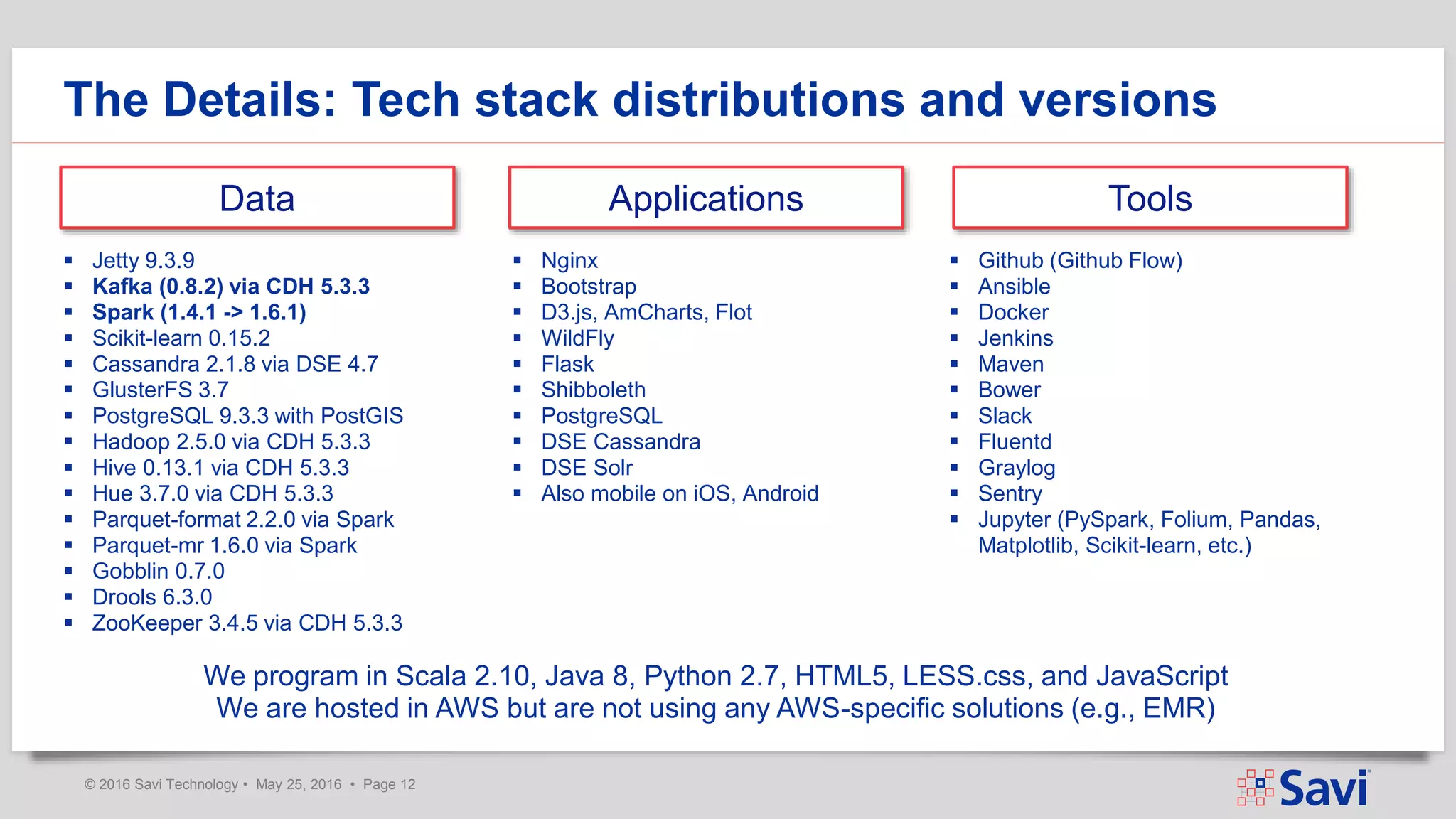


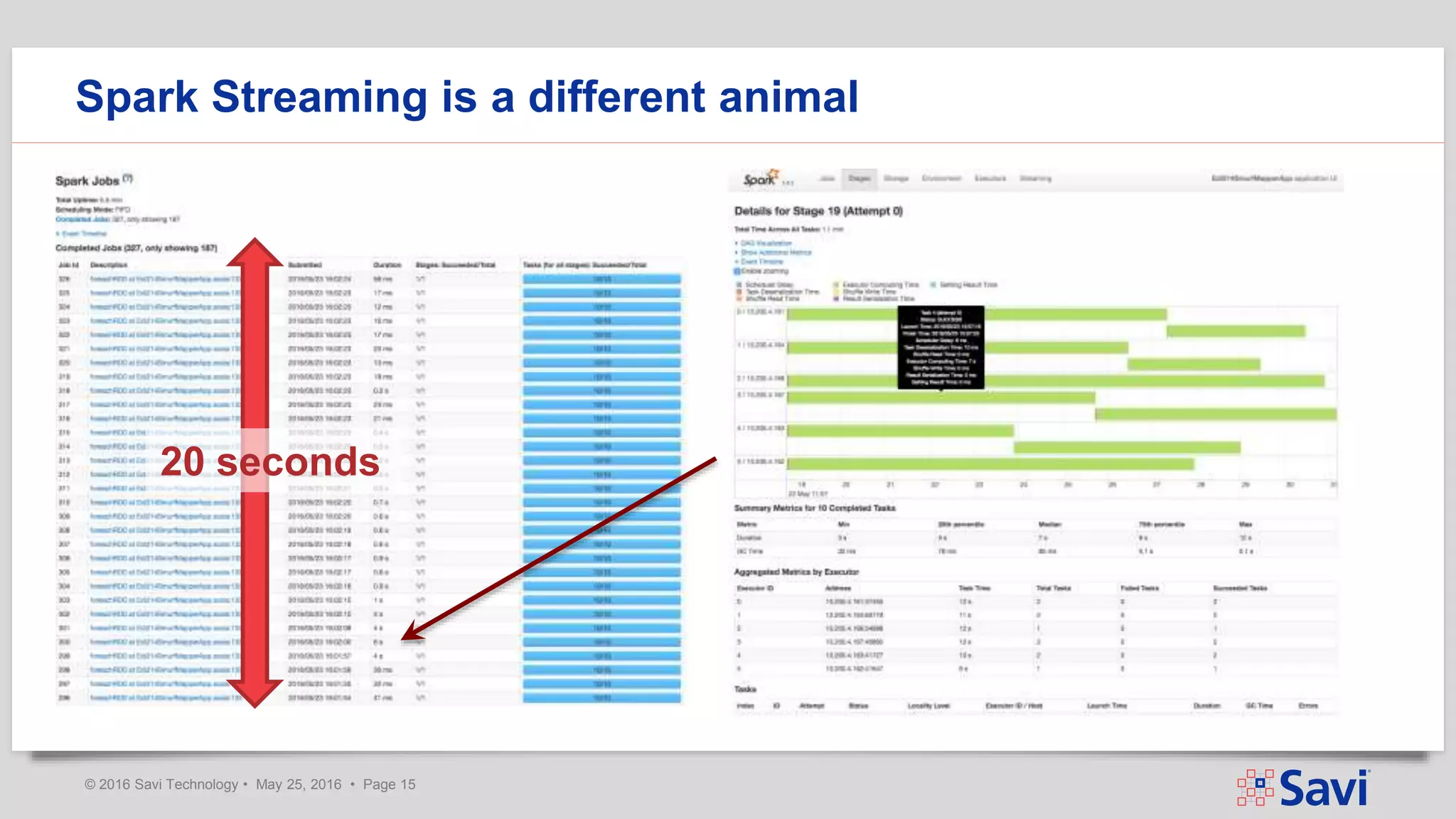



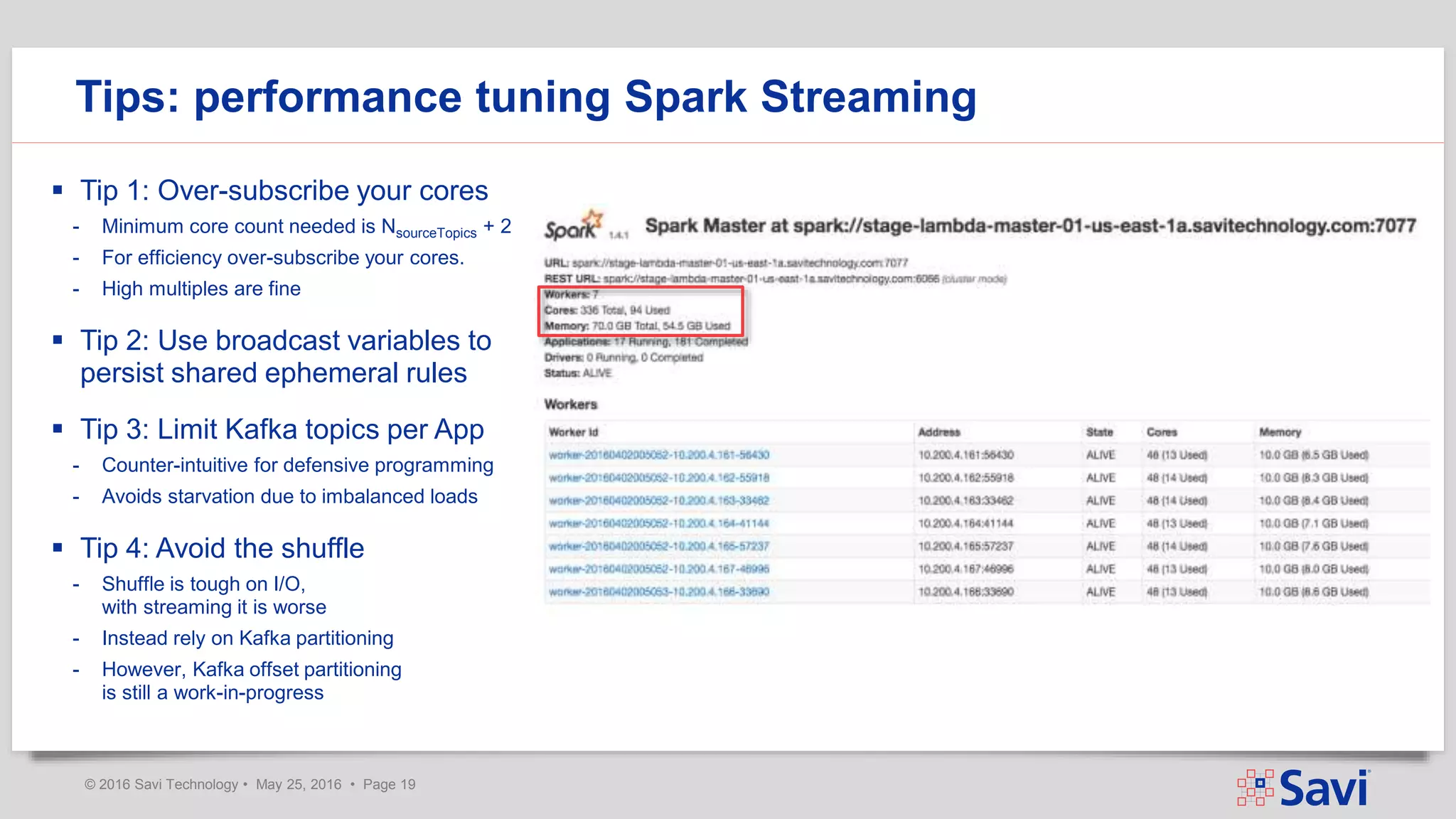

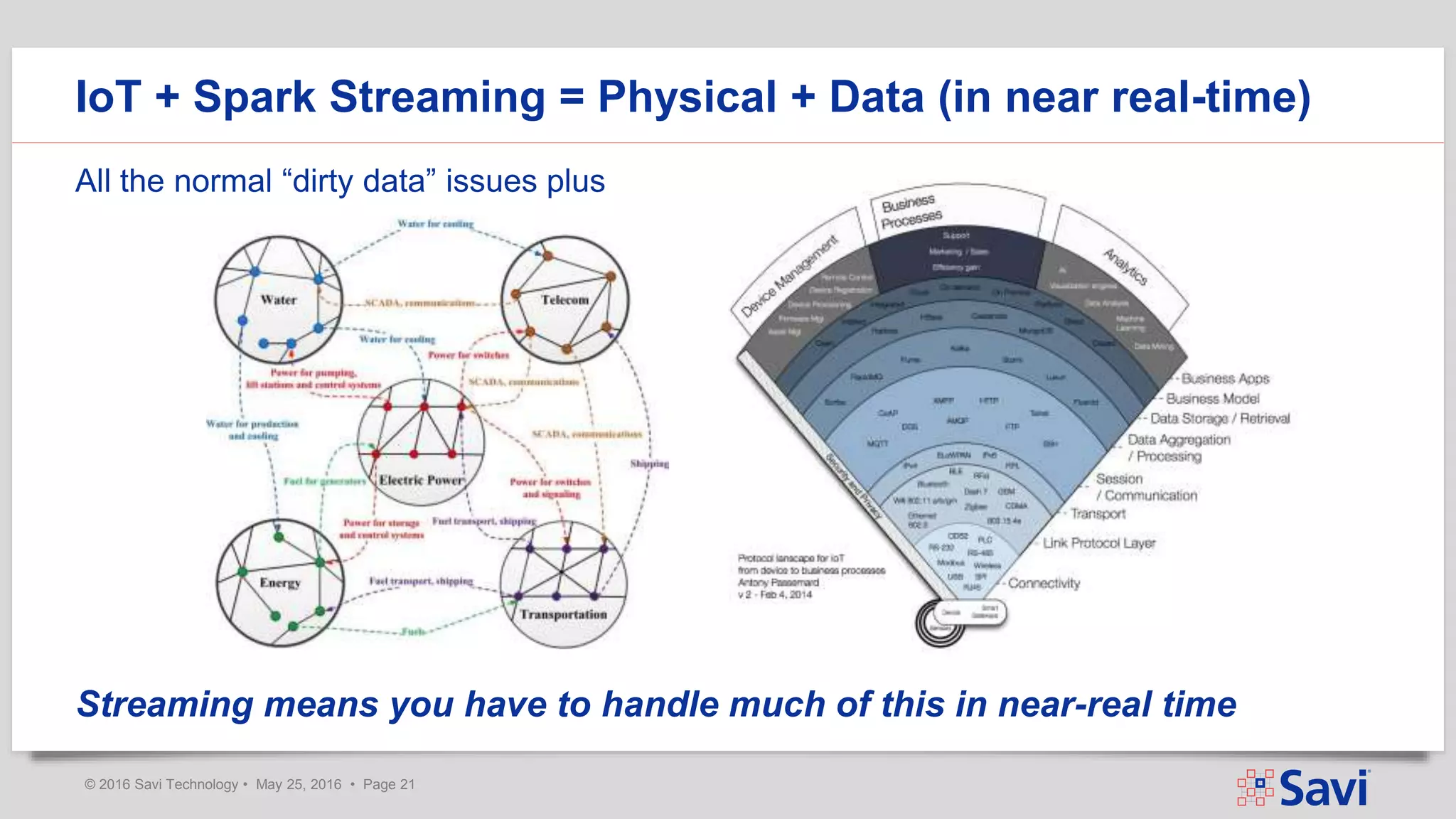
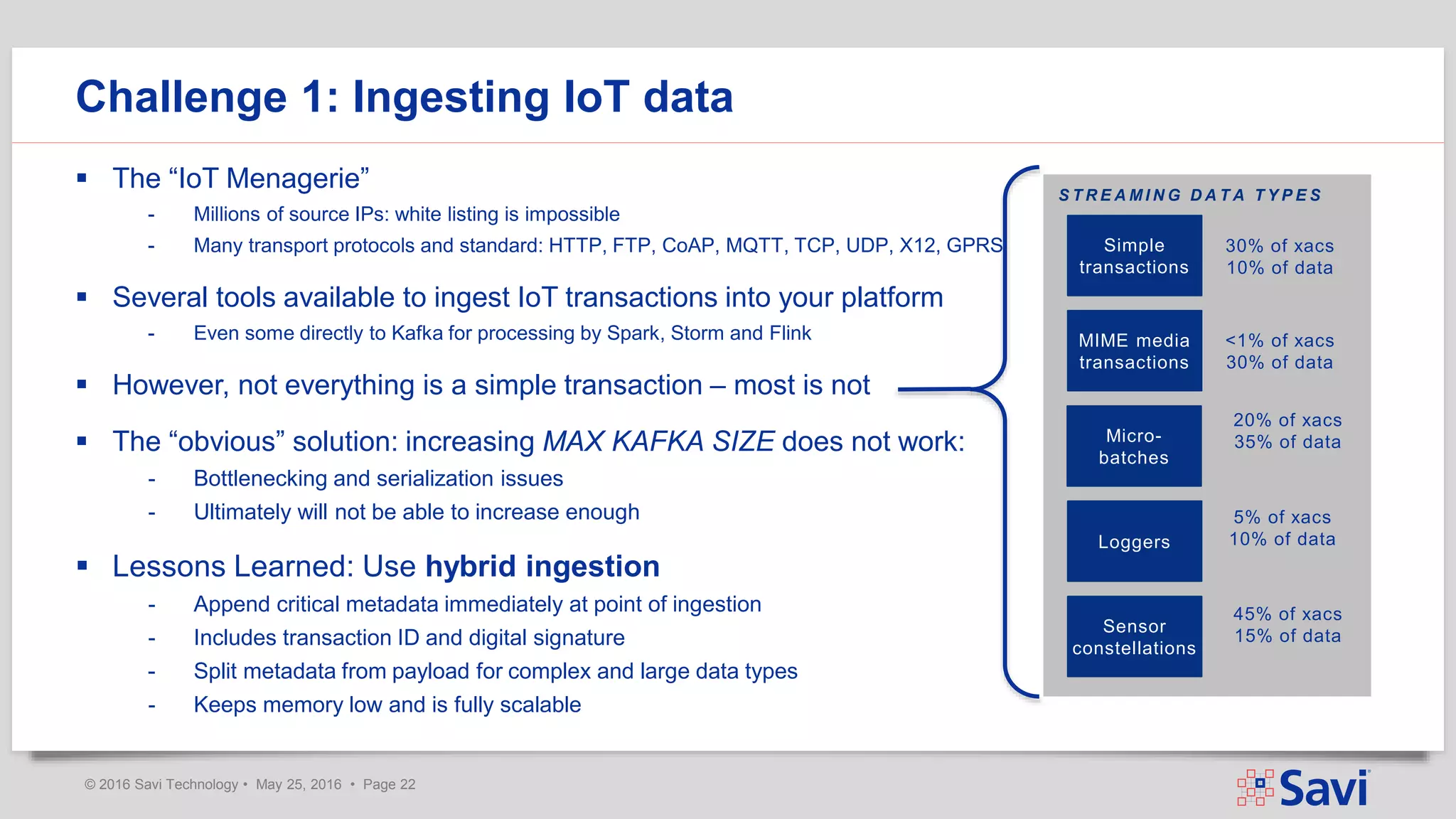
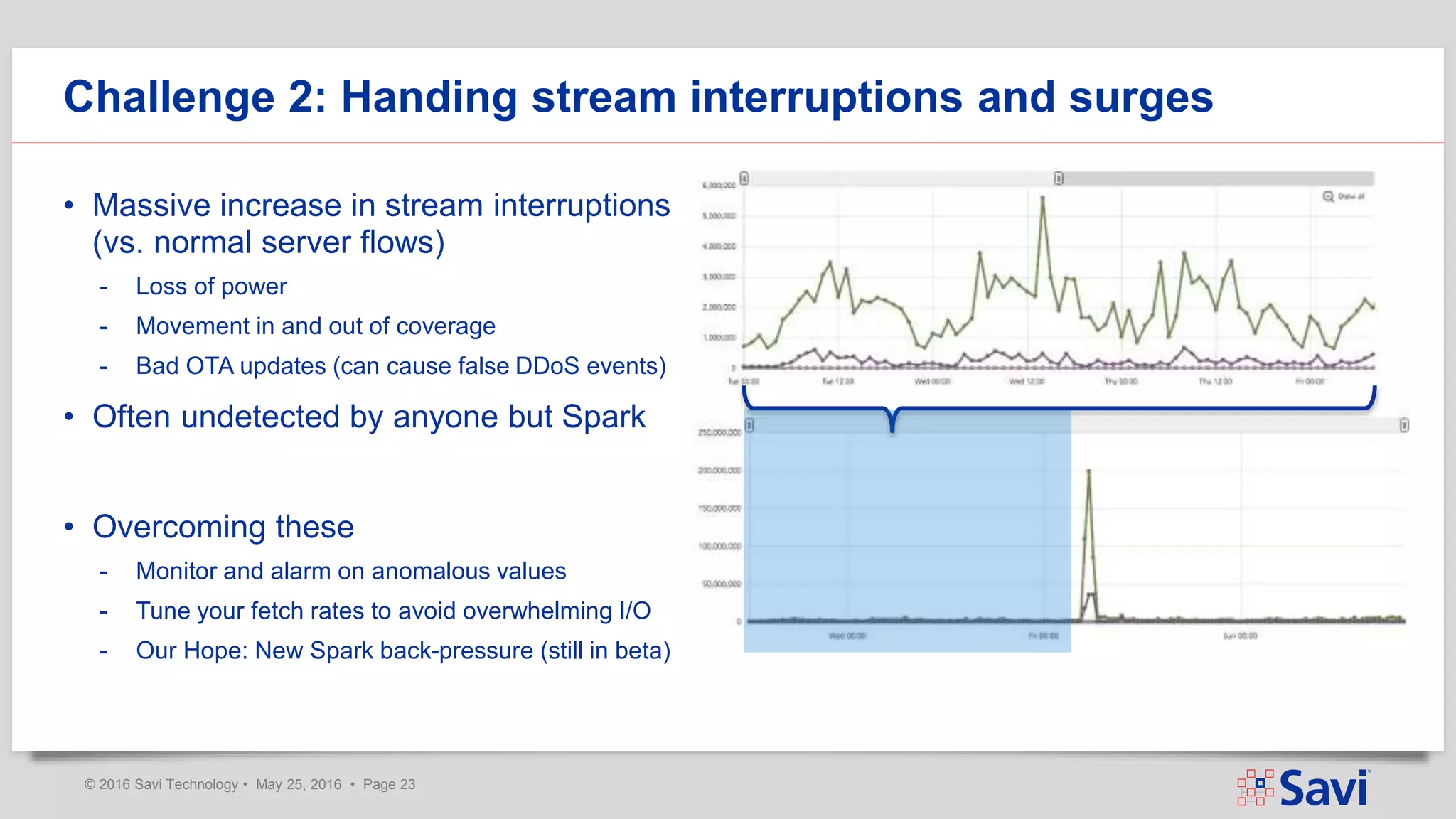


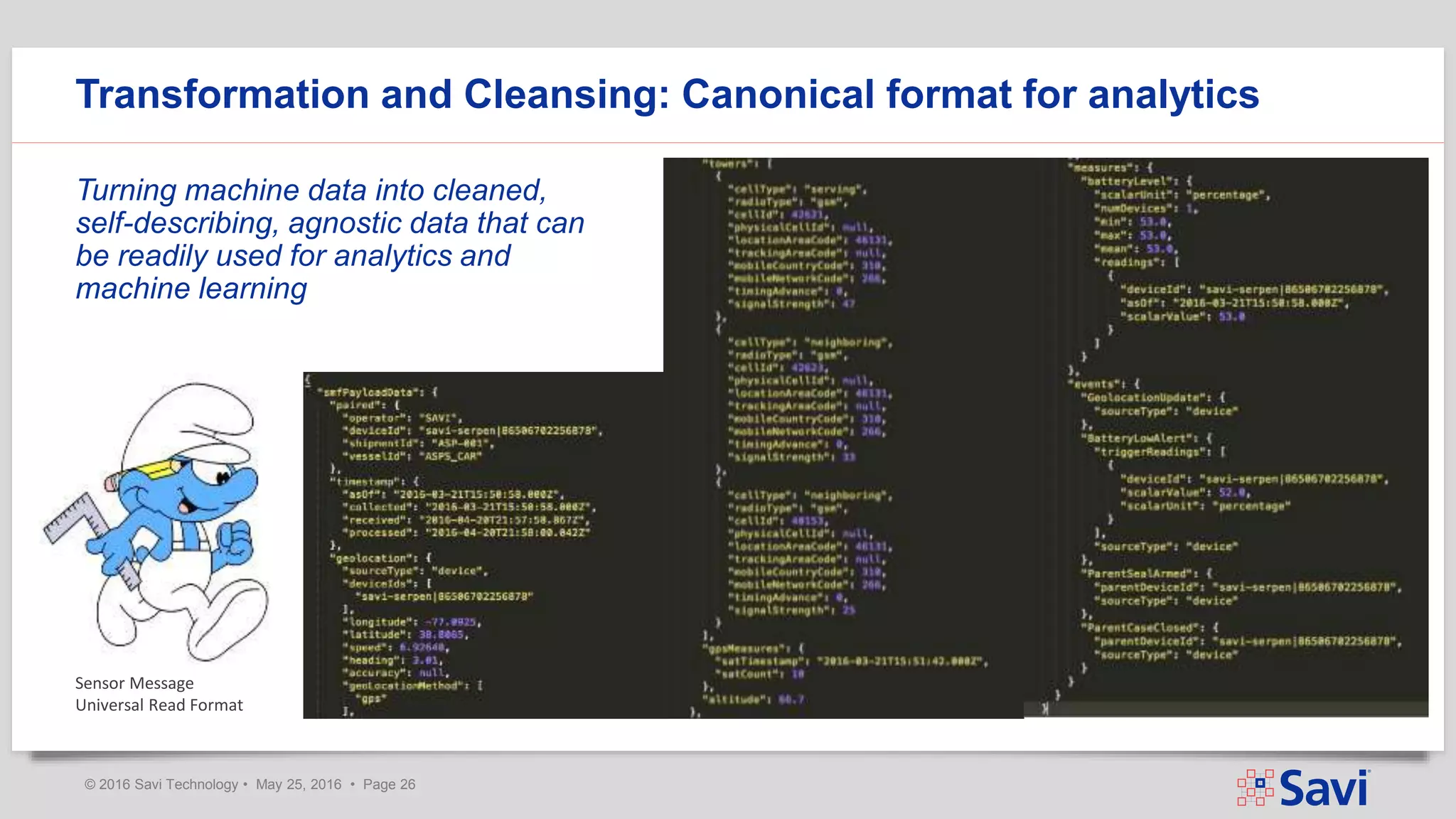



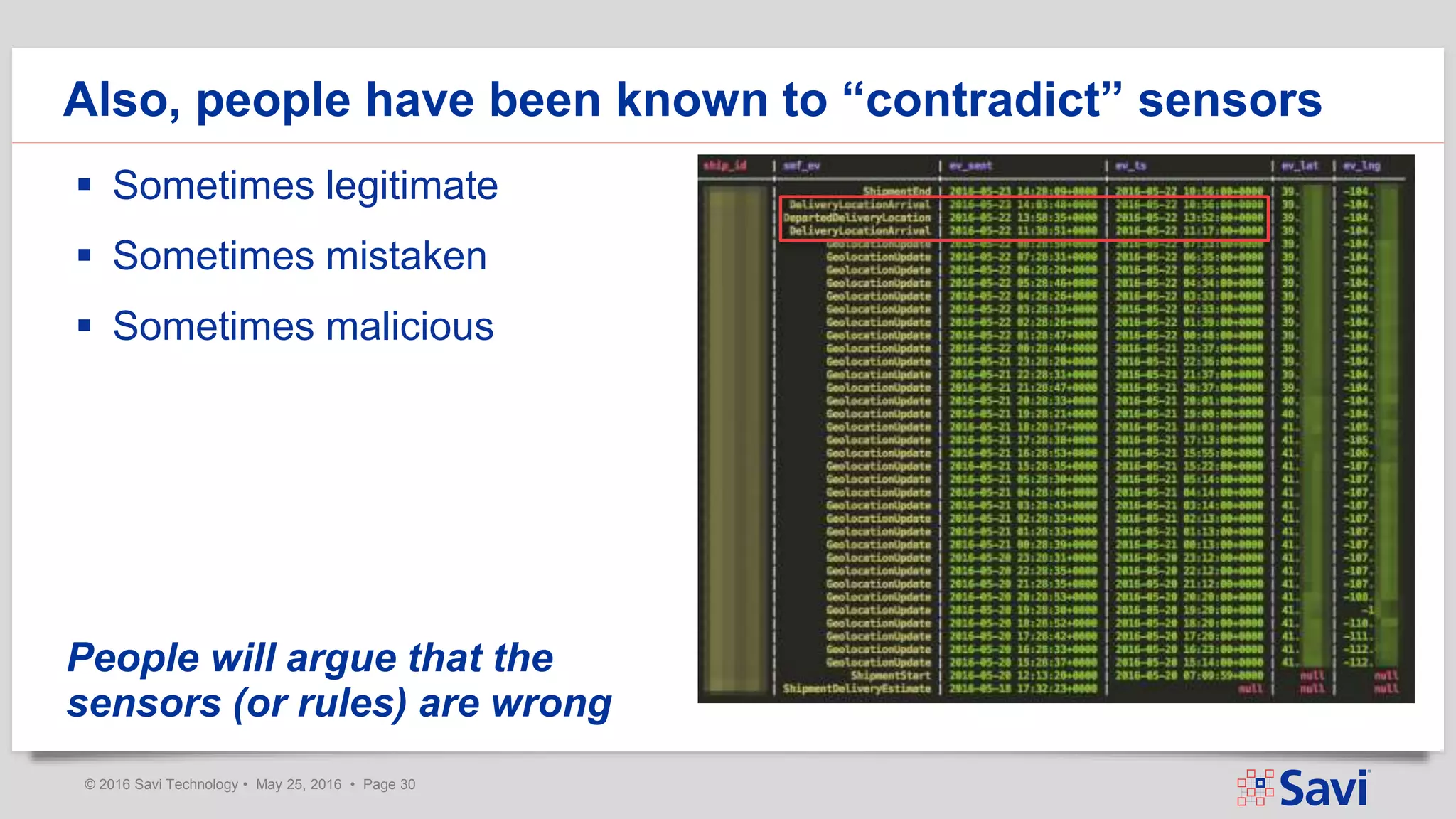





The document presents insights on using Spark Streaming for Industrial IoT, highlighting the unique challenges of integrating physical and data aspects in real-time. Key topics include best practices for handling streaming interruptions, data ingestion, and predictive analytics. The company emphasizes the importance of Spark's role in their technology stack for achieving real-time data processing and analytics in complex environments.








































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














