


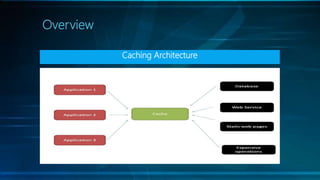

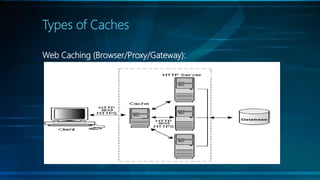

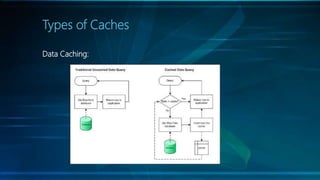


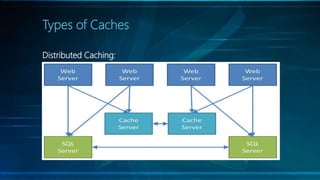














The document discusses selecting the right cache framework for applications. It begins by defining caching and its benefits, such as improving data access speed by storing portions of data in faster memory. It then covers types of caches including web, data, application, and distributed caching. Next, it examines caching algorithms like FIFO, LRU, LFU and their characteristics. The document also reviews cache expiration models and then provides details on several popular cache frameworks like EhCache, JBoss Cache, OSCache and their features. It concludes by mentioning some potential drawbacks of caching like stale data and overhead.



















































![[Hanoi-August 13] Tech Talk on Caching Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/nitecocachingsolution-130826204343-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















































