Download as PDF, PPTX







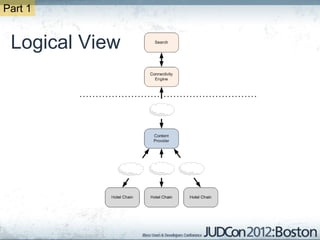


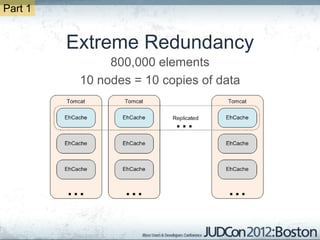

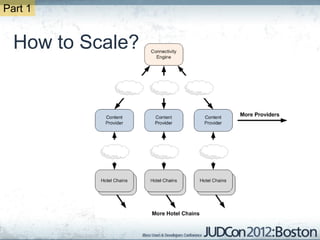





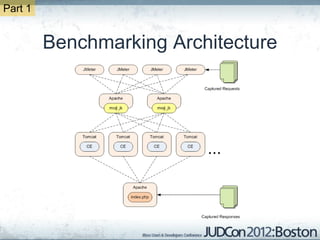



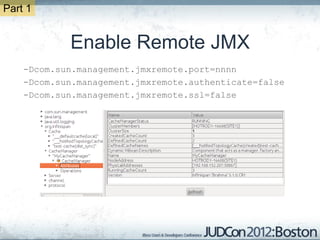
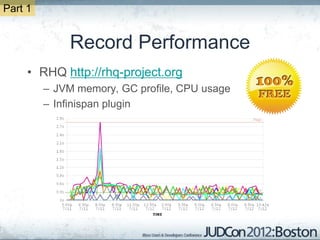

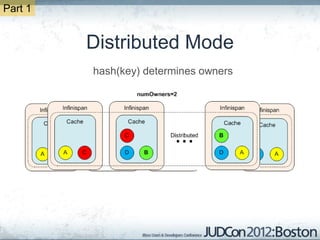


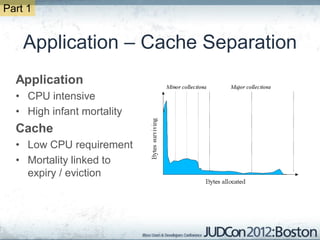
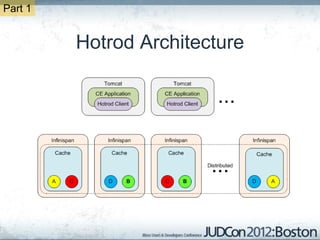

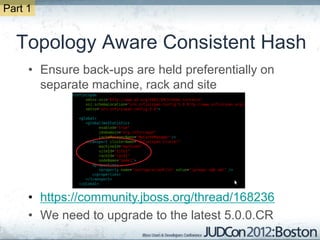
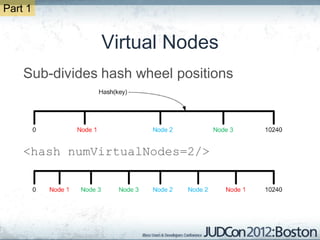
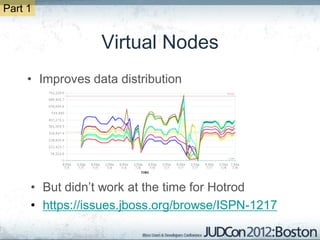

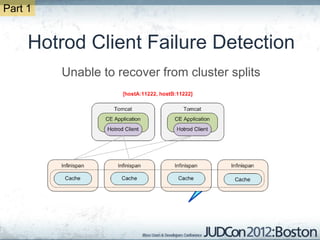

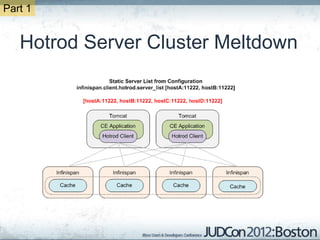

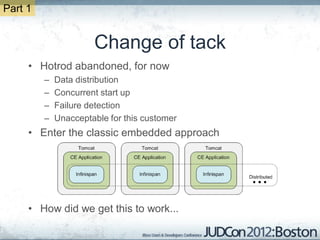





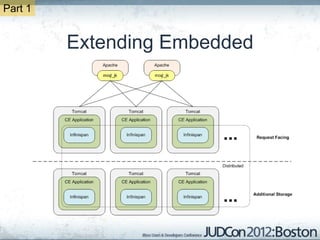














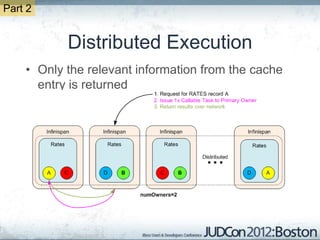





The document outlines the challenges faced by an online travel and accommodation provider with their existing and new systems using Infinispan for caching, highlighting issues such as cache size, response times, and scalability. It discusses the benchmarking of different architectures, the evaluation of Infinispan against alternatives like Ehcache, and the transition away from a Hotrod client due to operational limitations. The implementation of a distributed execution service is presented as a solution to improve latency and manage data access more efficiently.


























![DataEngConf SF16 - BYOMQ: Why We [re]Built IronMQ](https://cdn.slidesharecdn.com/ss_thumbnails/byomq-160414230807-thumbnail.jpg?width=640&height=640&fit=bounds)
















































































