Download as PDF, PPTX







































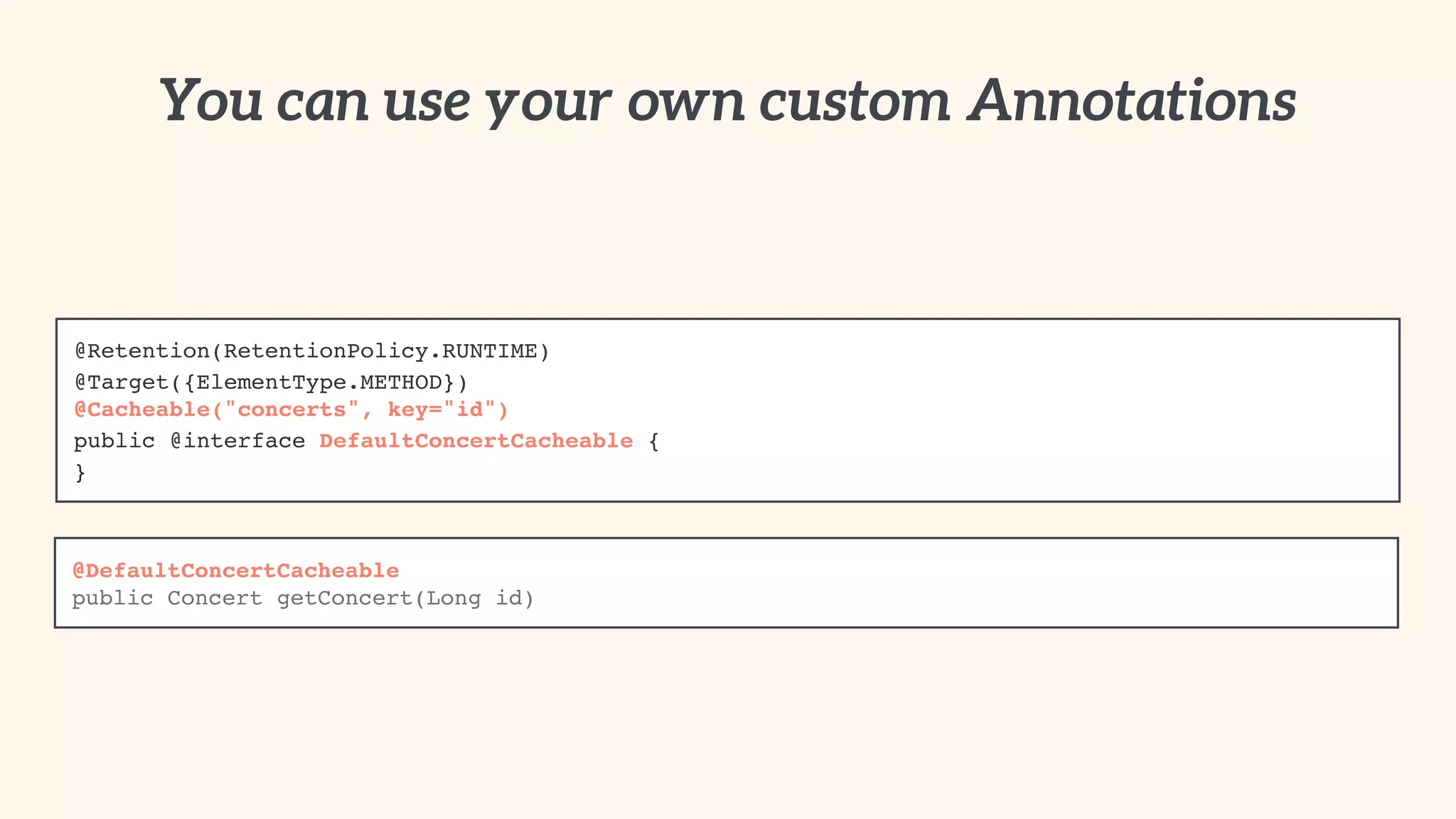
![public class MyOwnKeyGenerator implements KeyGenerator {!
@Override!
public Object generate(Object target, Method method, Object... params) {!
if (params.length == 0) {!
return new SimpleKey("EMPTY");!
}!
if (params.length == 1) {!
Object param = params[0];!
if (param != null && !param.getClass().isArray()) {!
return param;!
}!
}!
return new SimpleKey(params);!
}!
}
You need a custom default KeyGenerator?
<cache:annotation-driven cache-manager="hazelcastCacheManager"
keyGenerator="myOwnKeyGenerator" />](https://image.slidesharecdn.com/springone2gxcachingwithspring-140910132219-phpapp02/75/Spring-One-2-GX-2014-CACHING-WITH-SPRING-ADVANCED-TOPICS-AND-BEST-PRACTICES-78-2048.jpg)
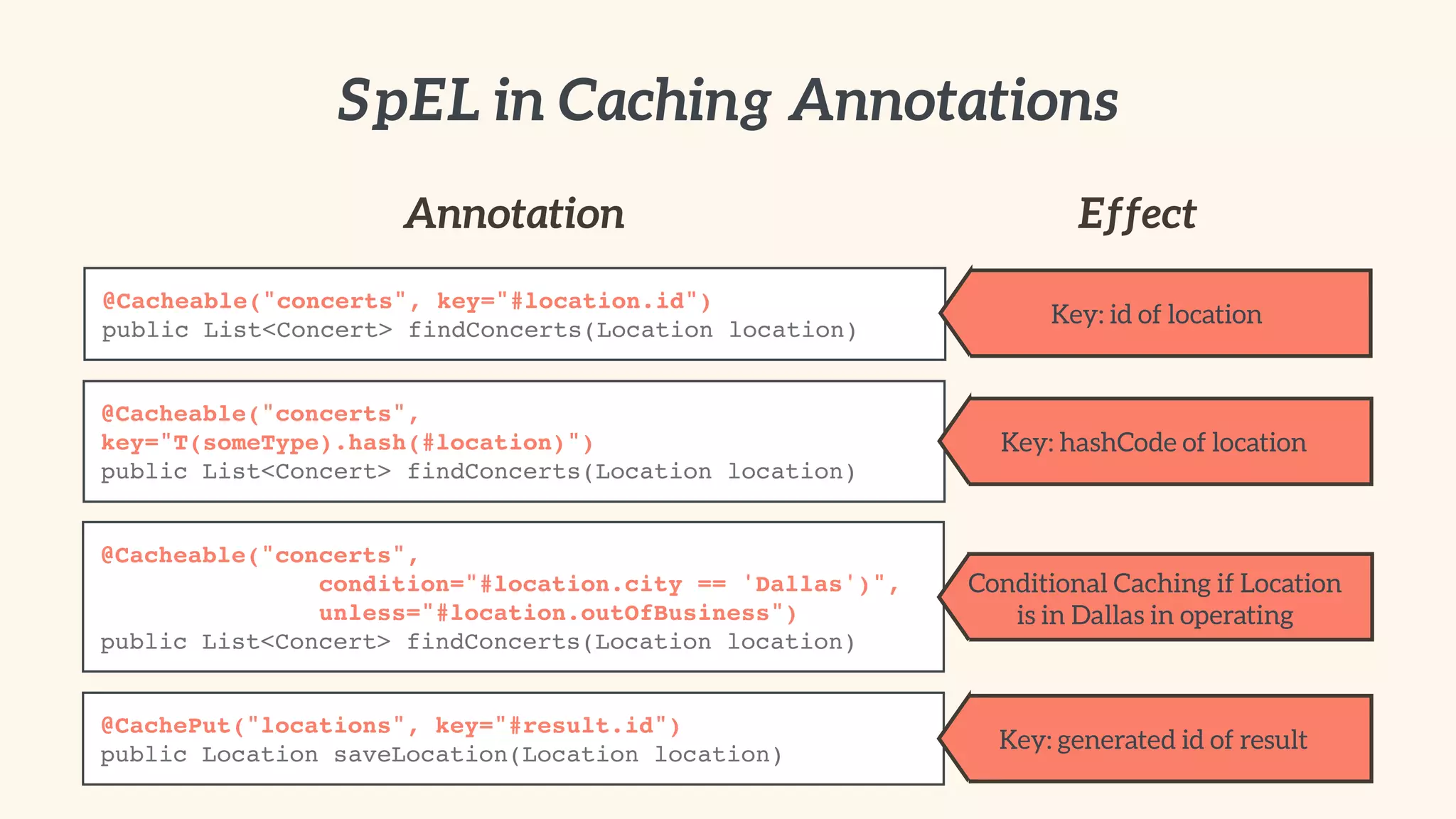









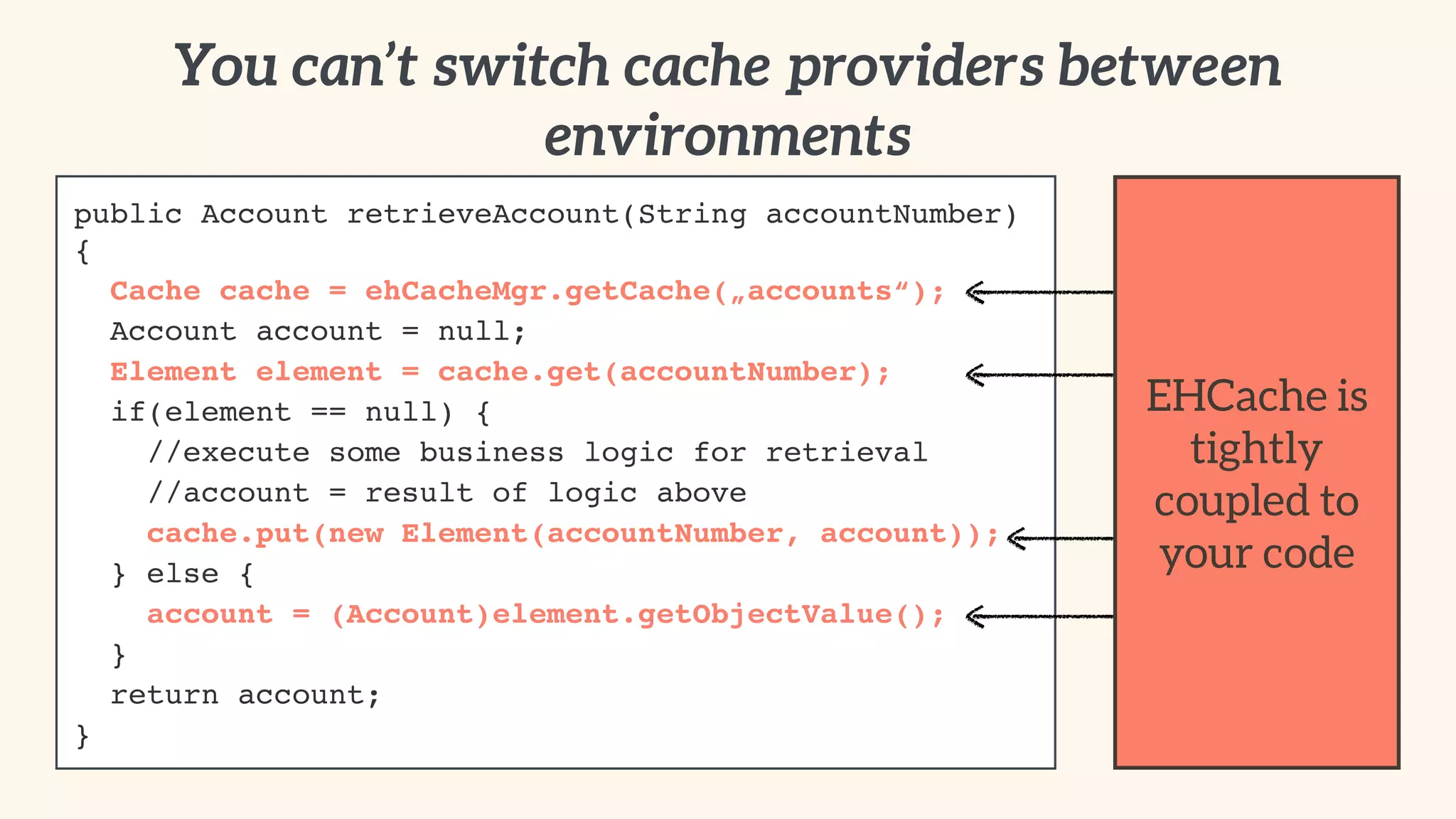
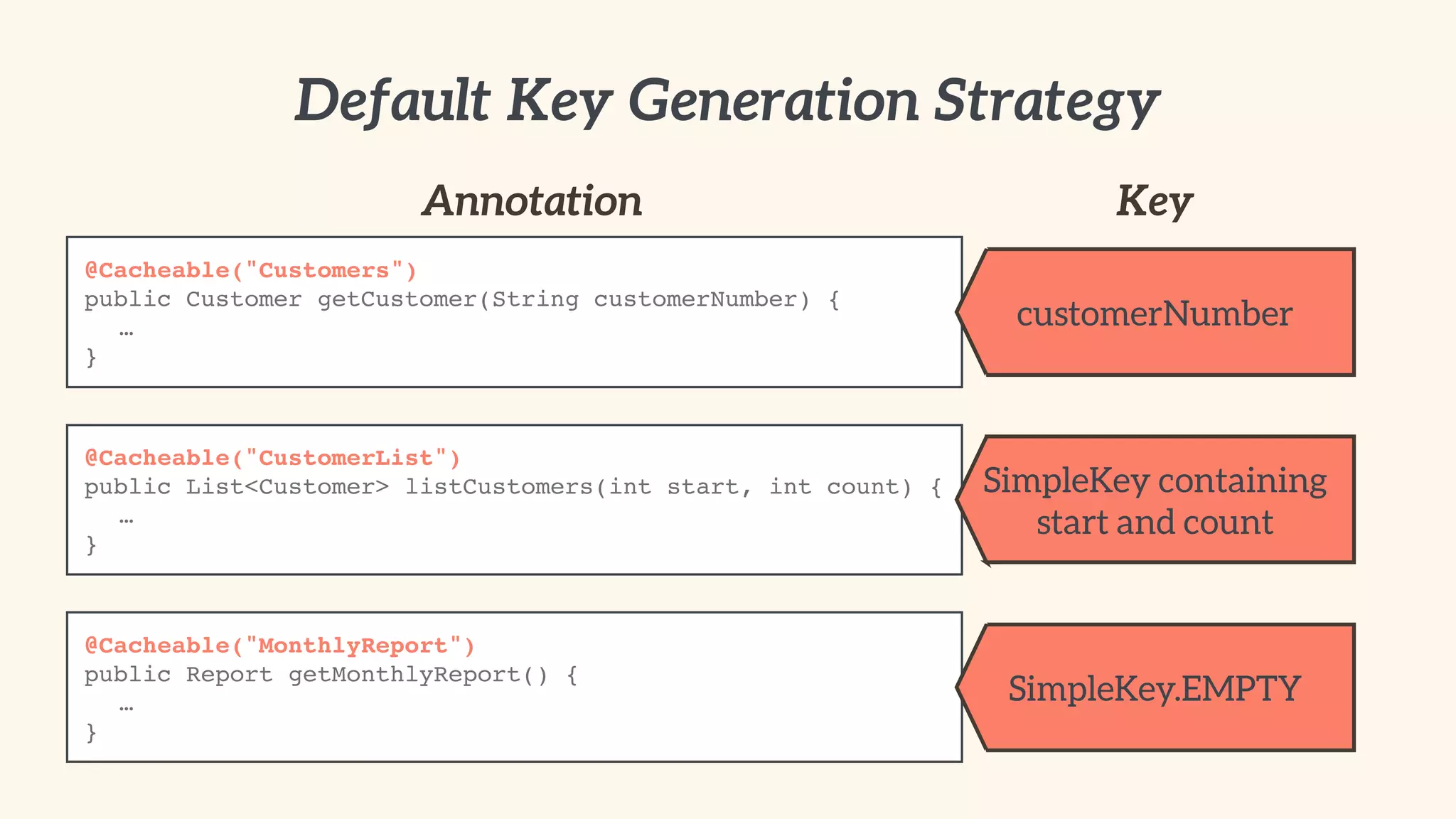
The document discusses advanced caching strategies and best practices using the Spring framework, focusing on various caching types, topologies, and implementation techniques. It emphasizes the importance of identifying suitable data for caching, avoiding unnecessary replication, and optimizing application performance through effective cache management. Additionally, it includes practical guidance on using Spring's caching annotations and integrating caching seamlessly into enterprise applications.
Presentation on caching best practices and types. Focus on Spring Framework and enterprise applications.
Definition of cache, importance of cache hits and misses, and comparison between enterprise applications and social platforms.
Issues faced with caching in enterprise applications and types of caches available for improved performance.
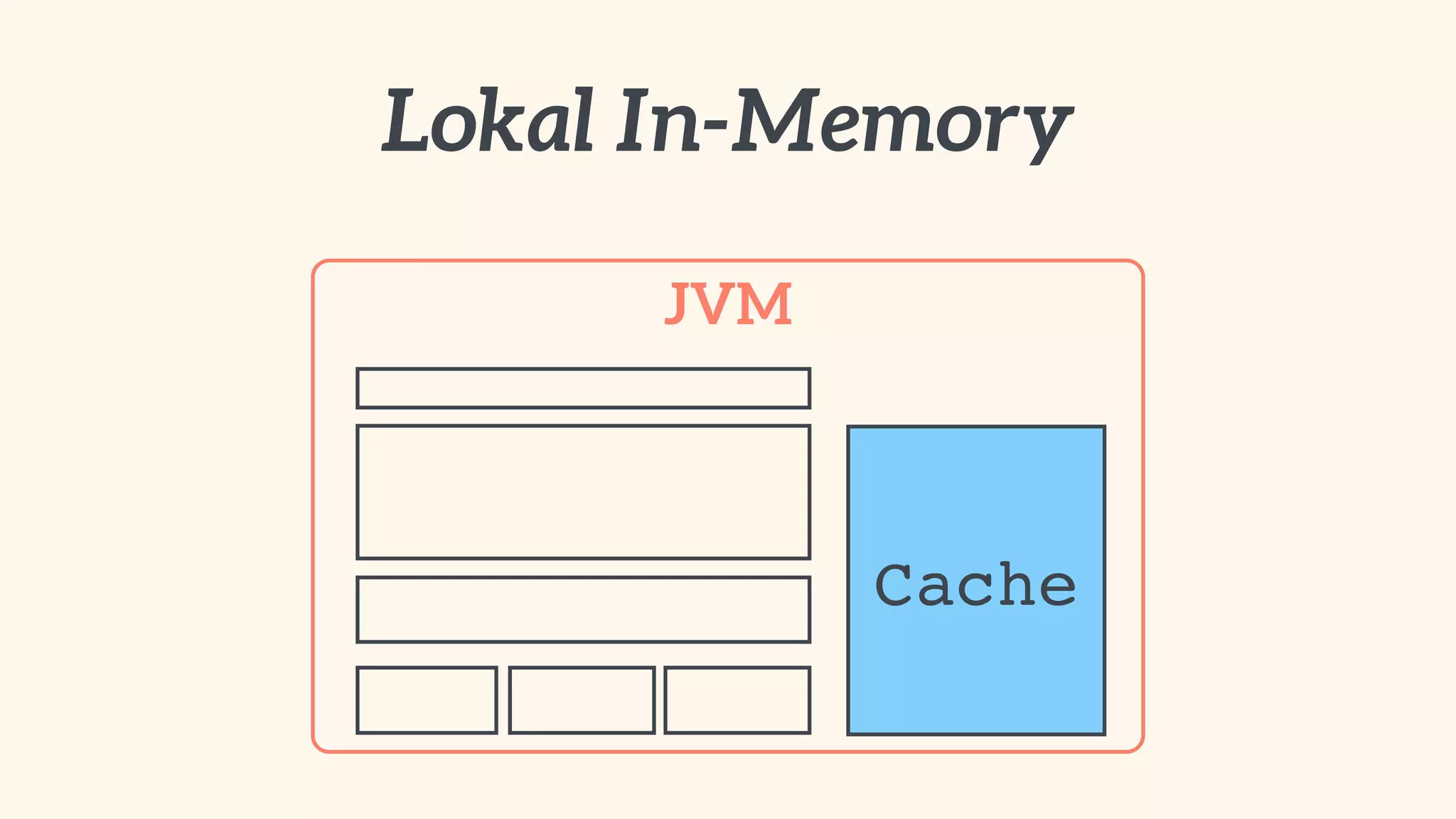
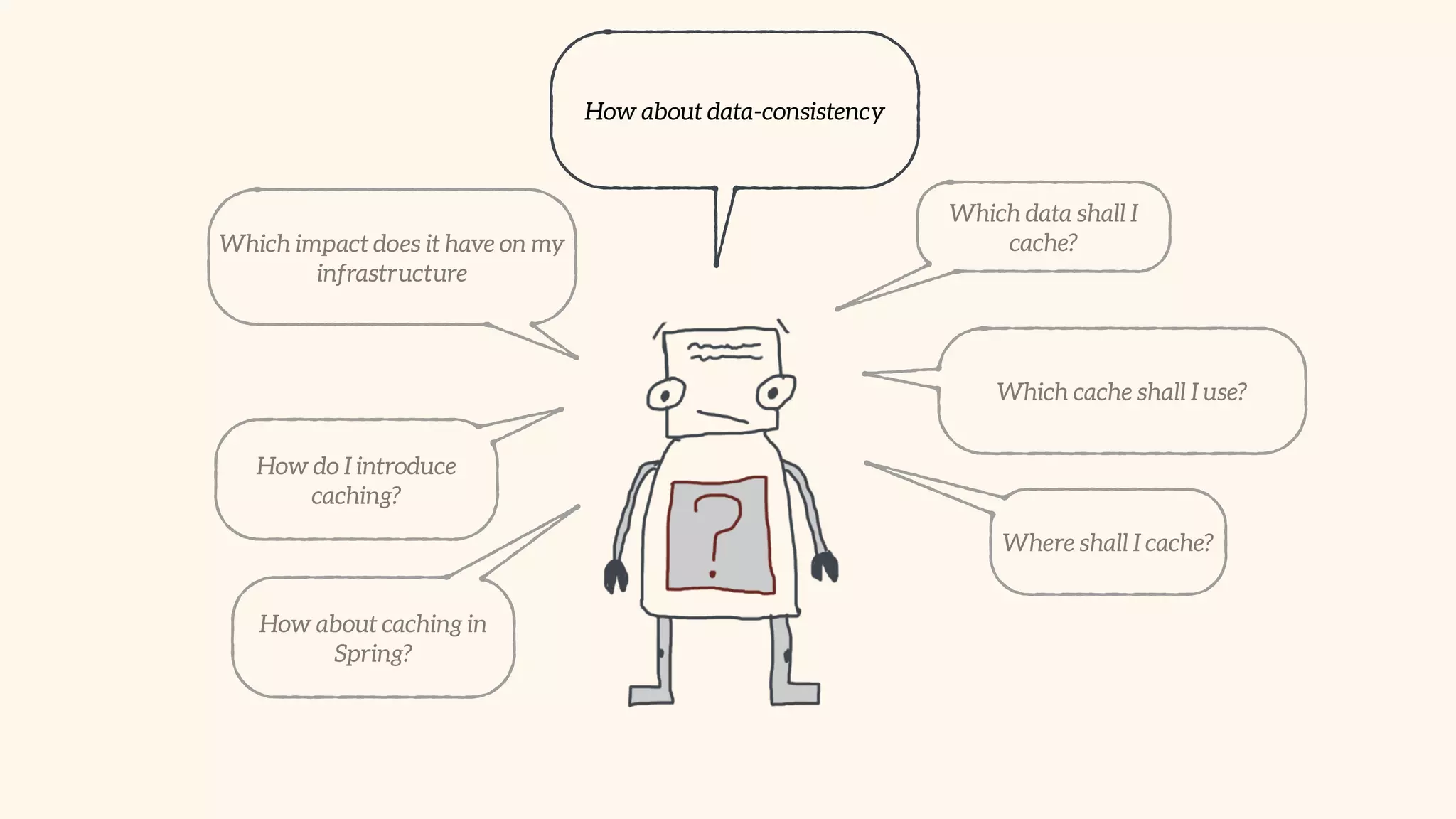
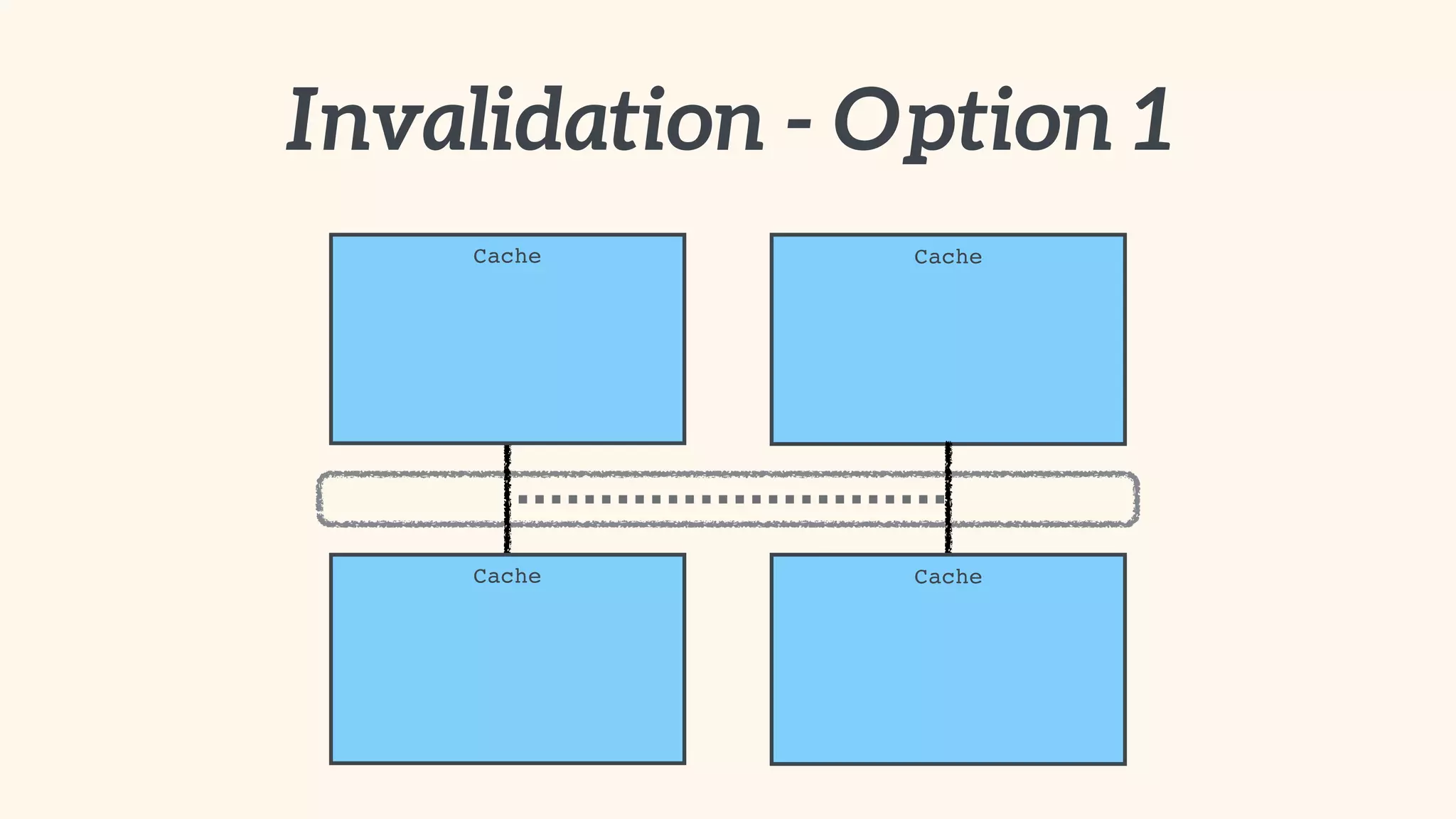
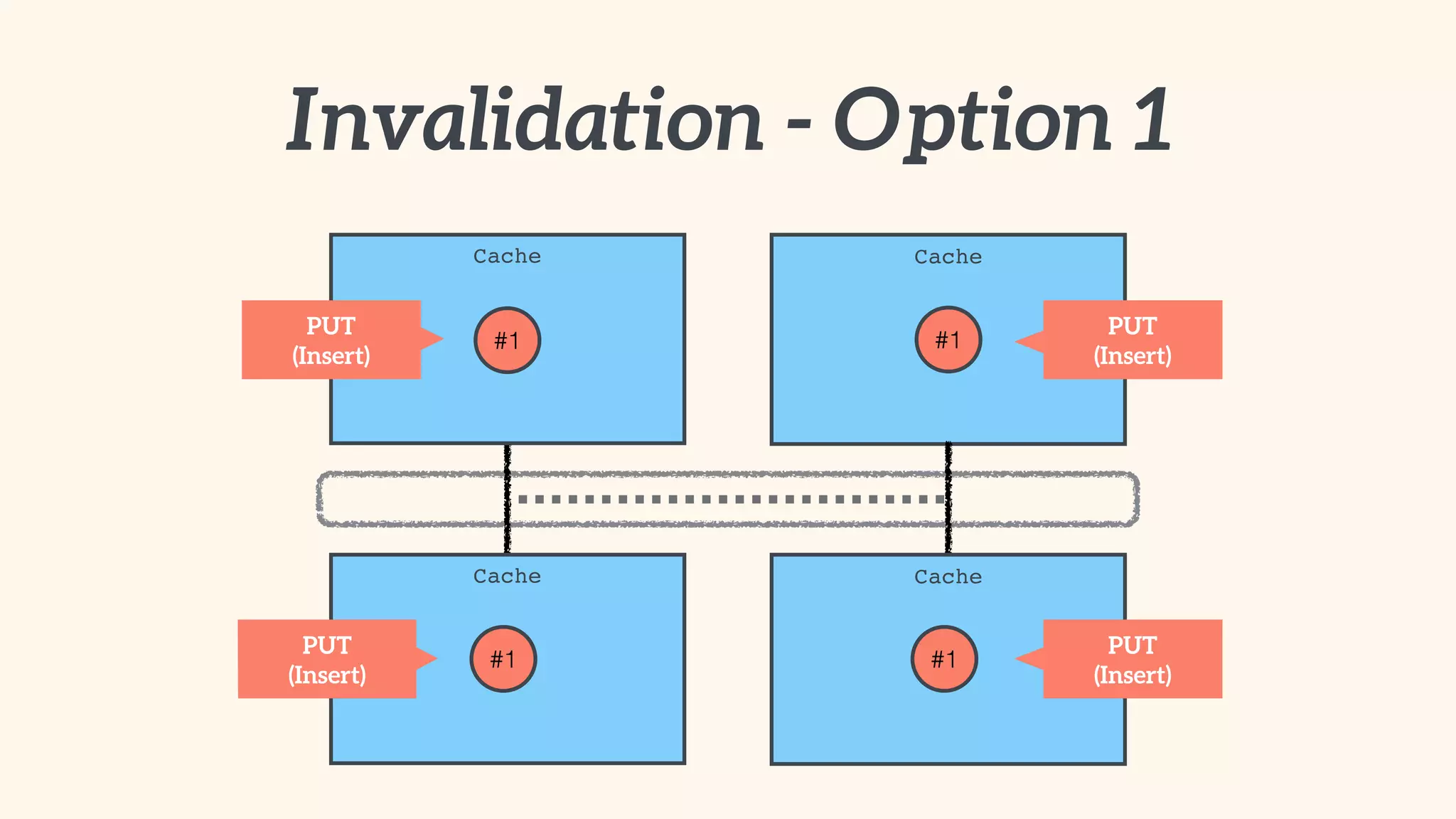
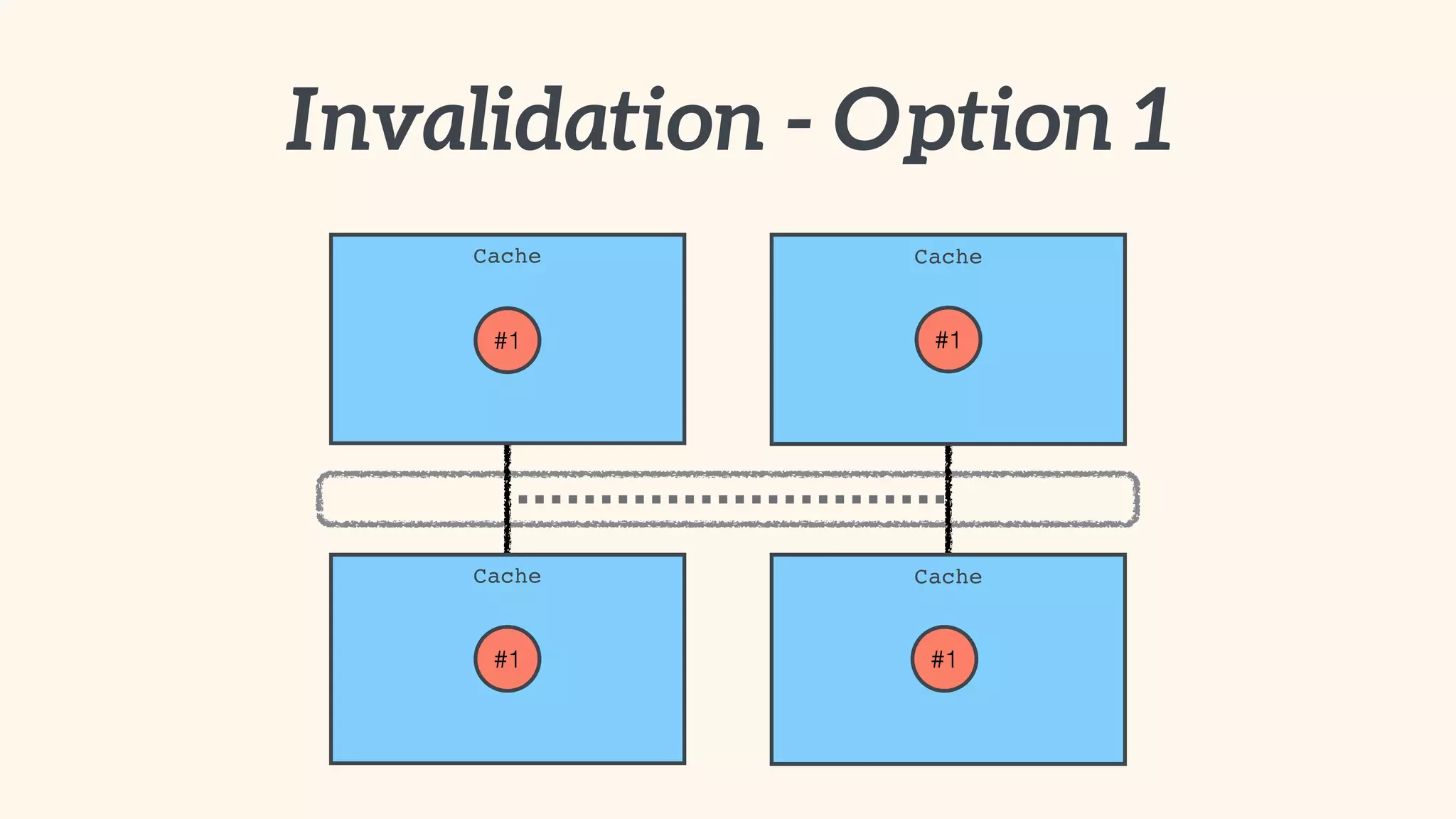
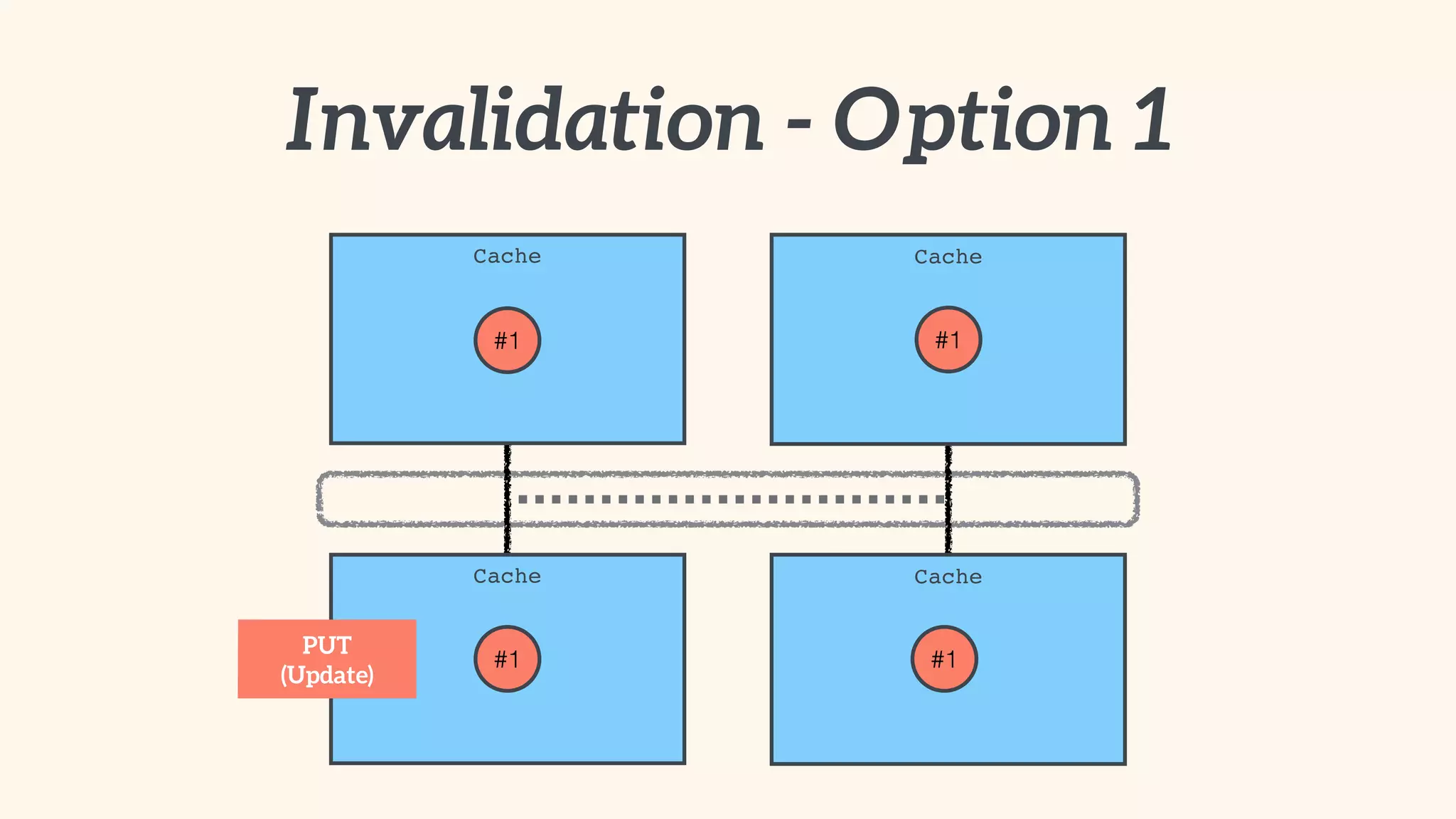
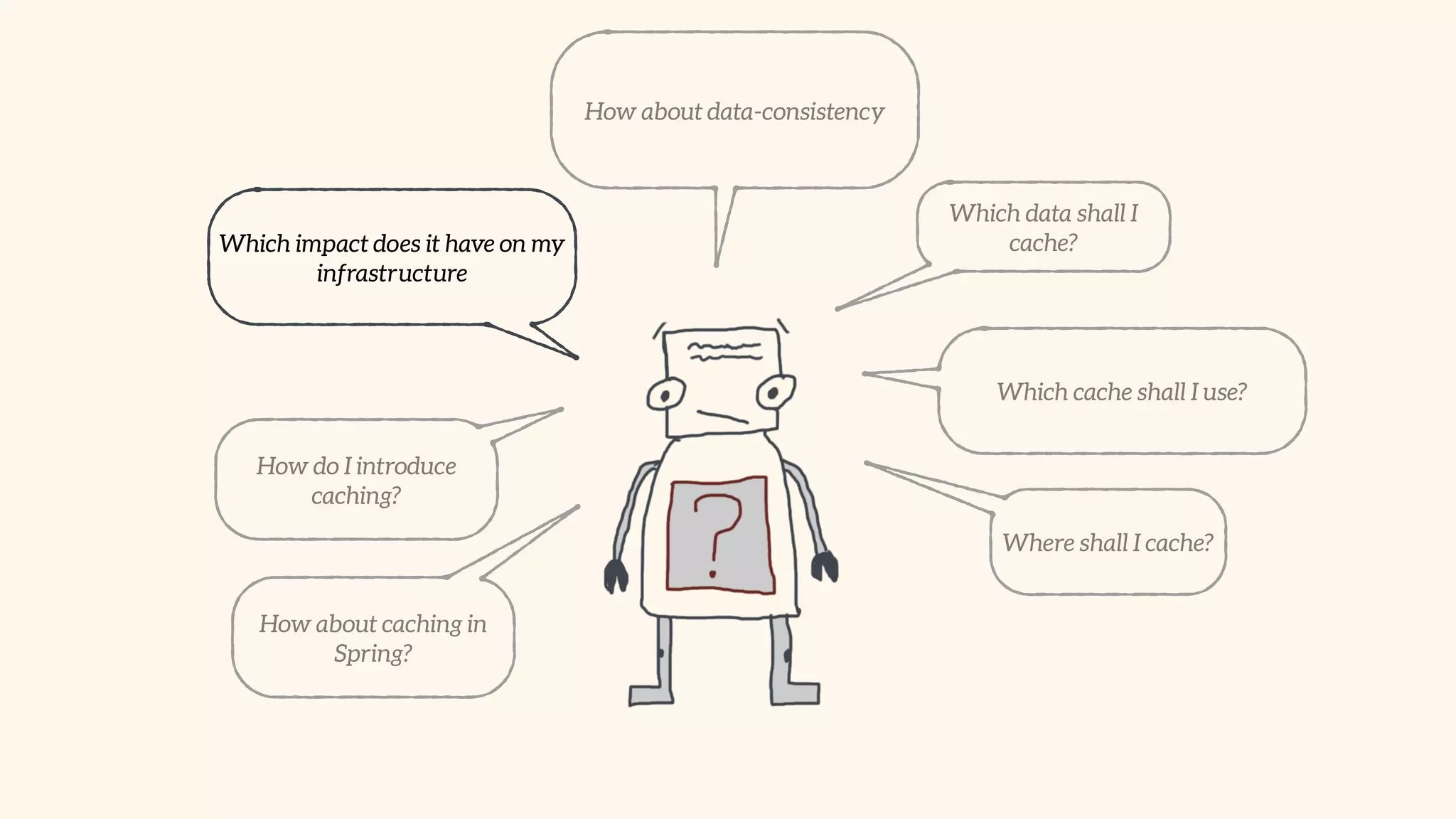
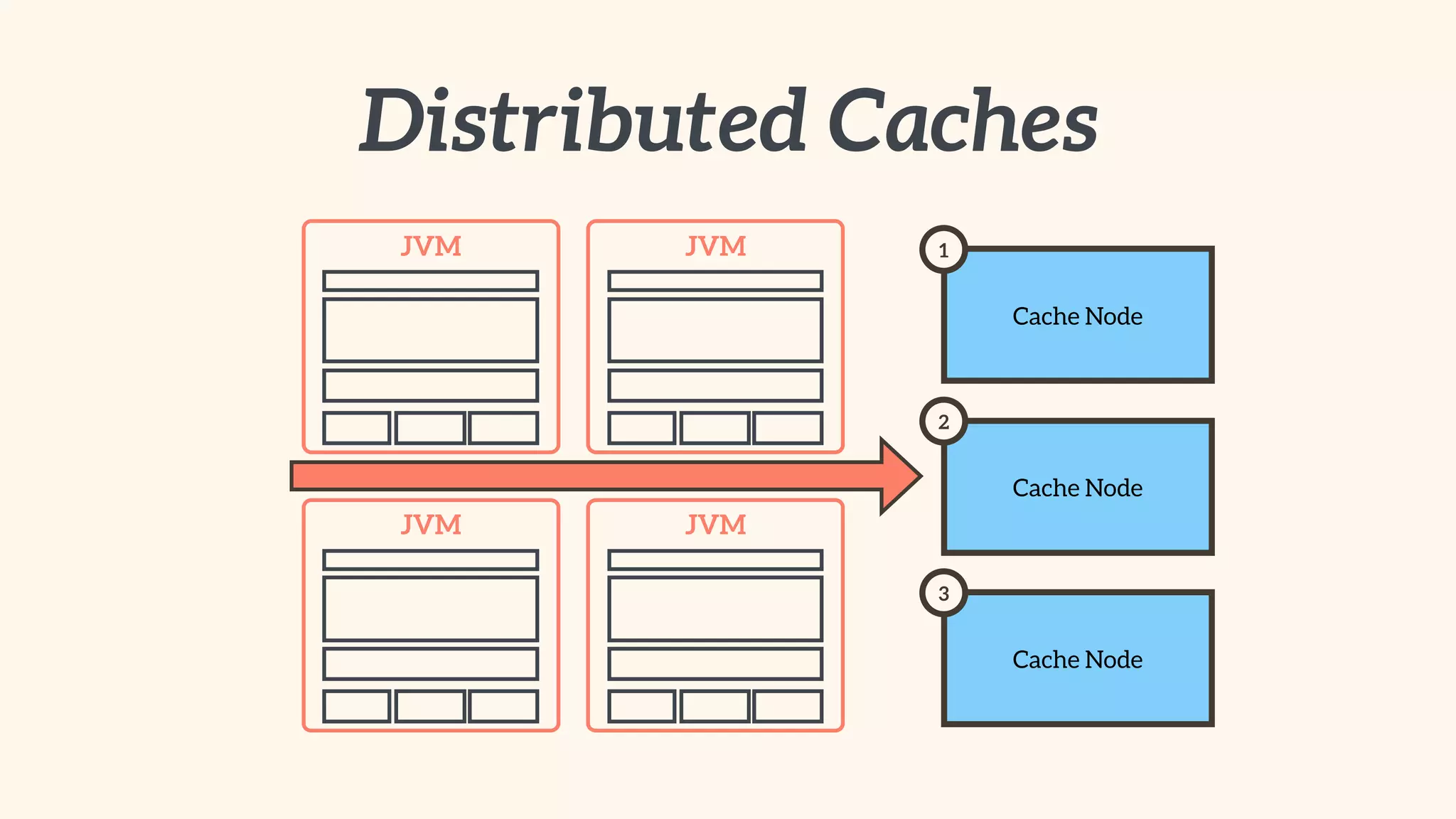
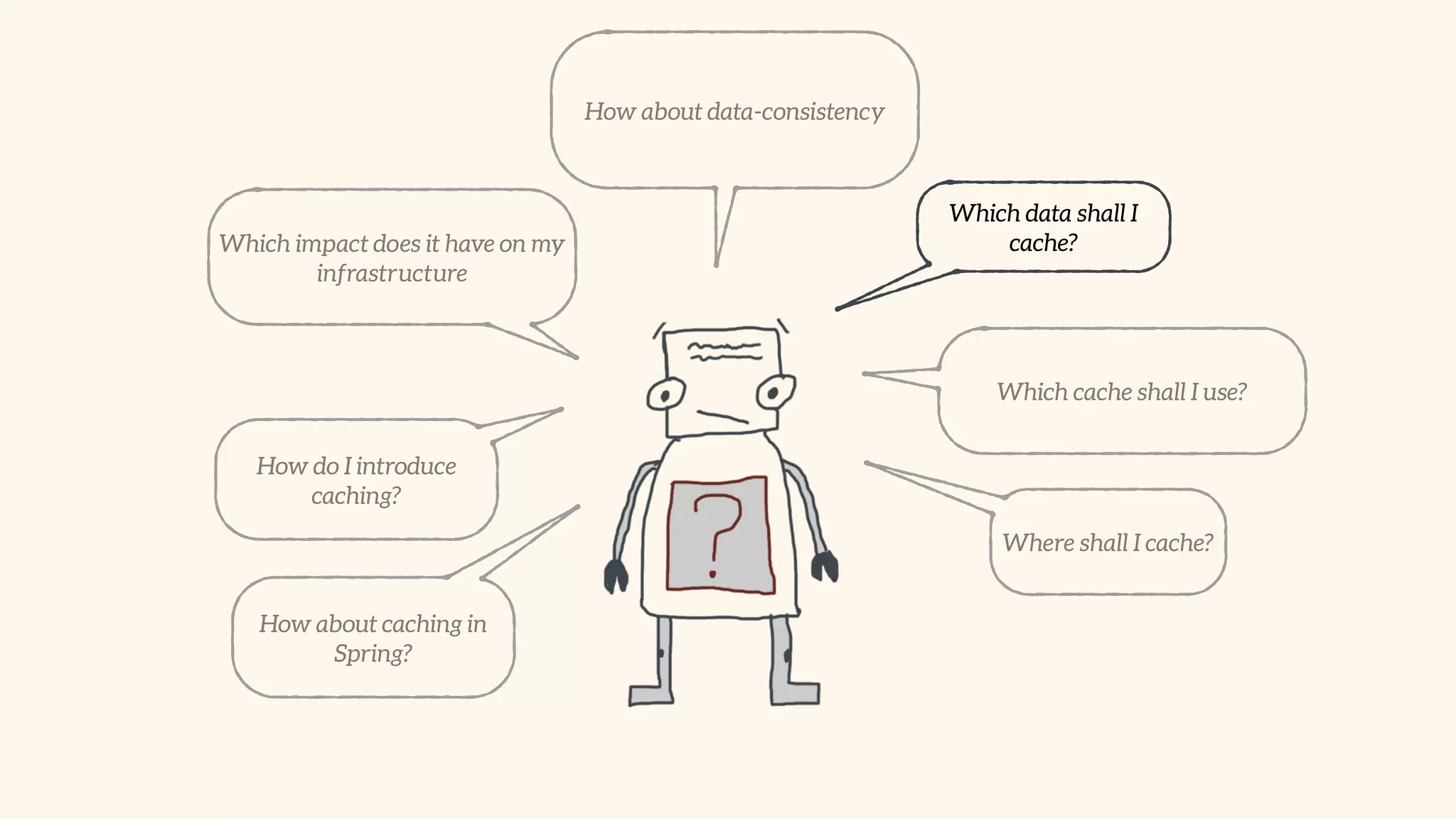
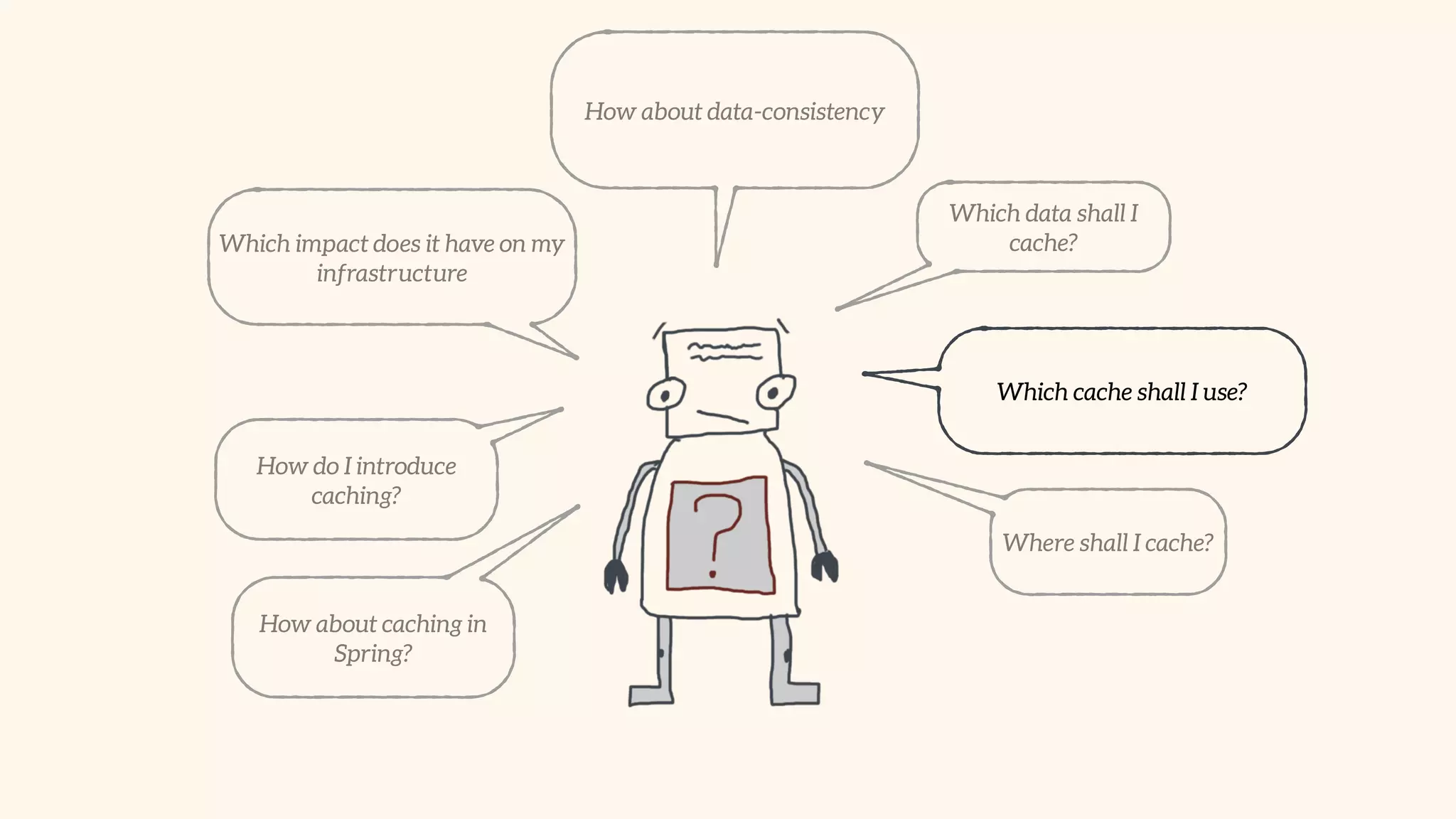
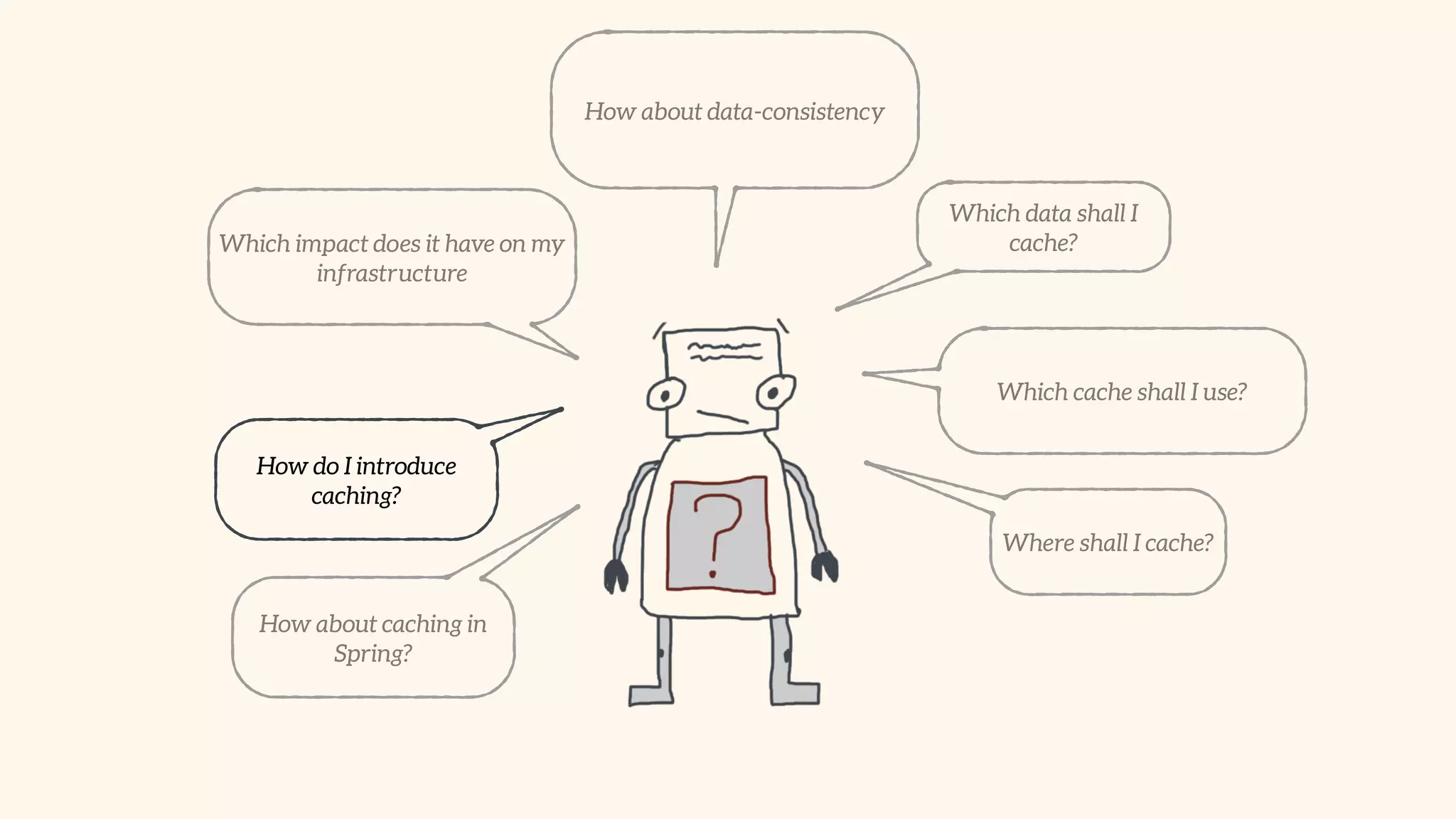
Focus on local and distributed caching within Spring, and critical questions for implementing caching.
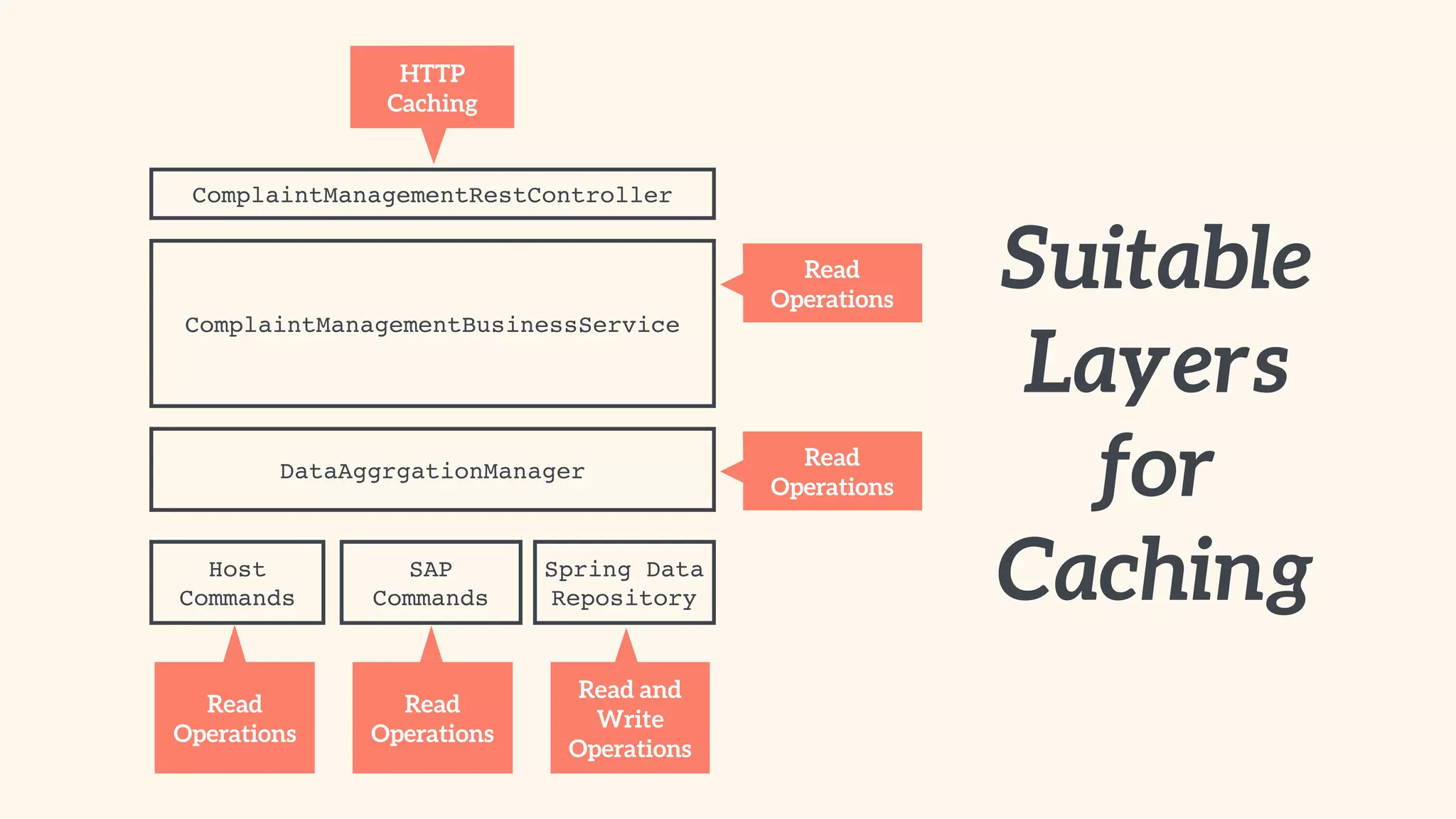
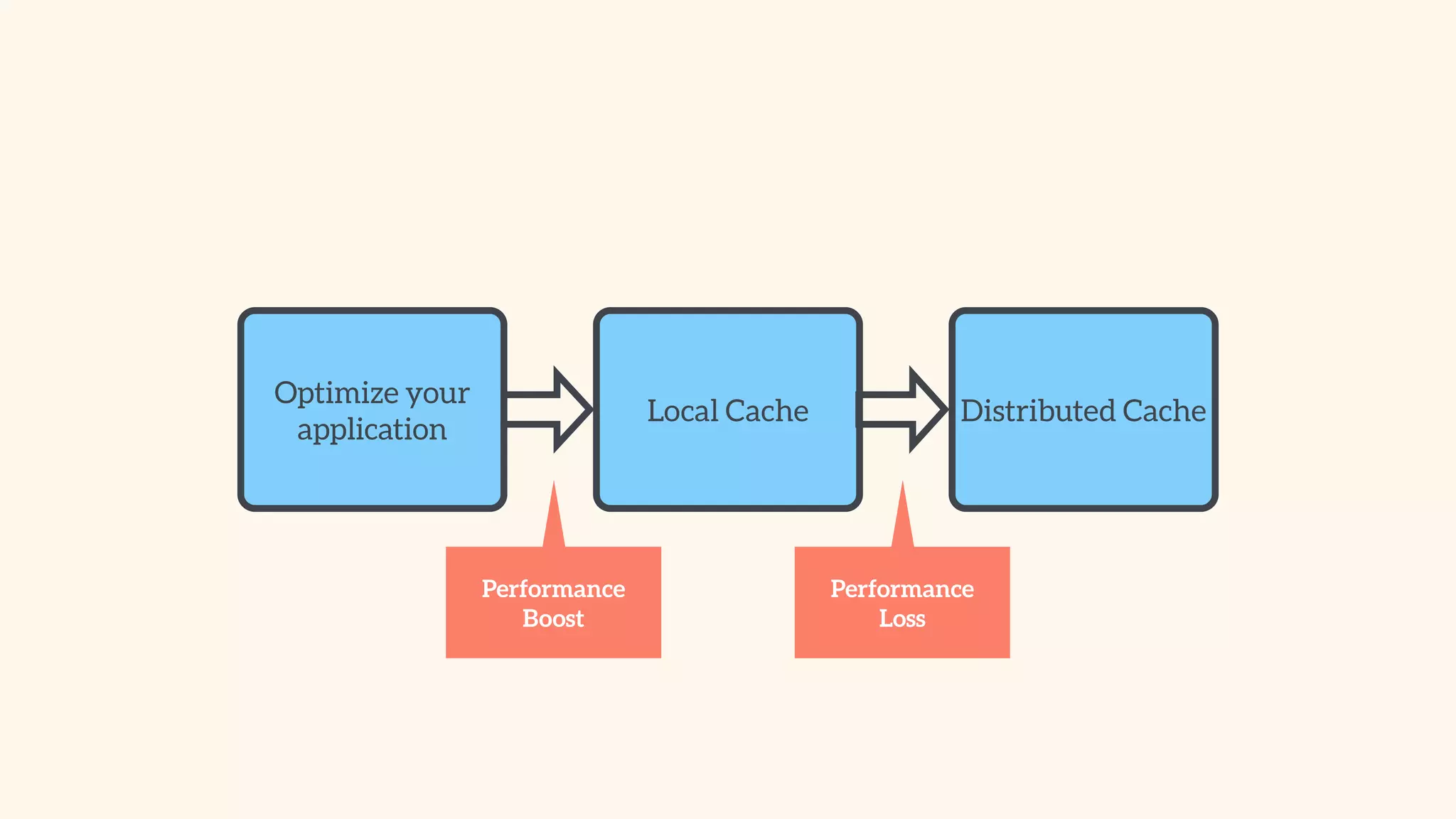
Steps to identify suitable layers for caching in application architecture and components involved.
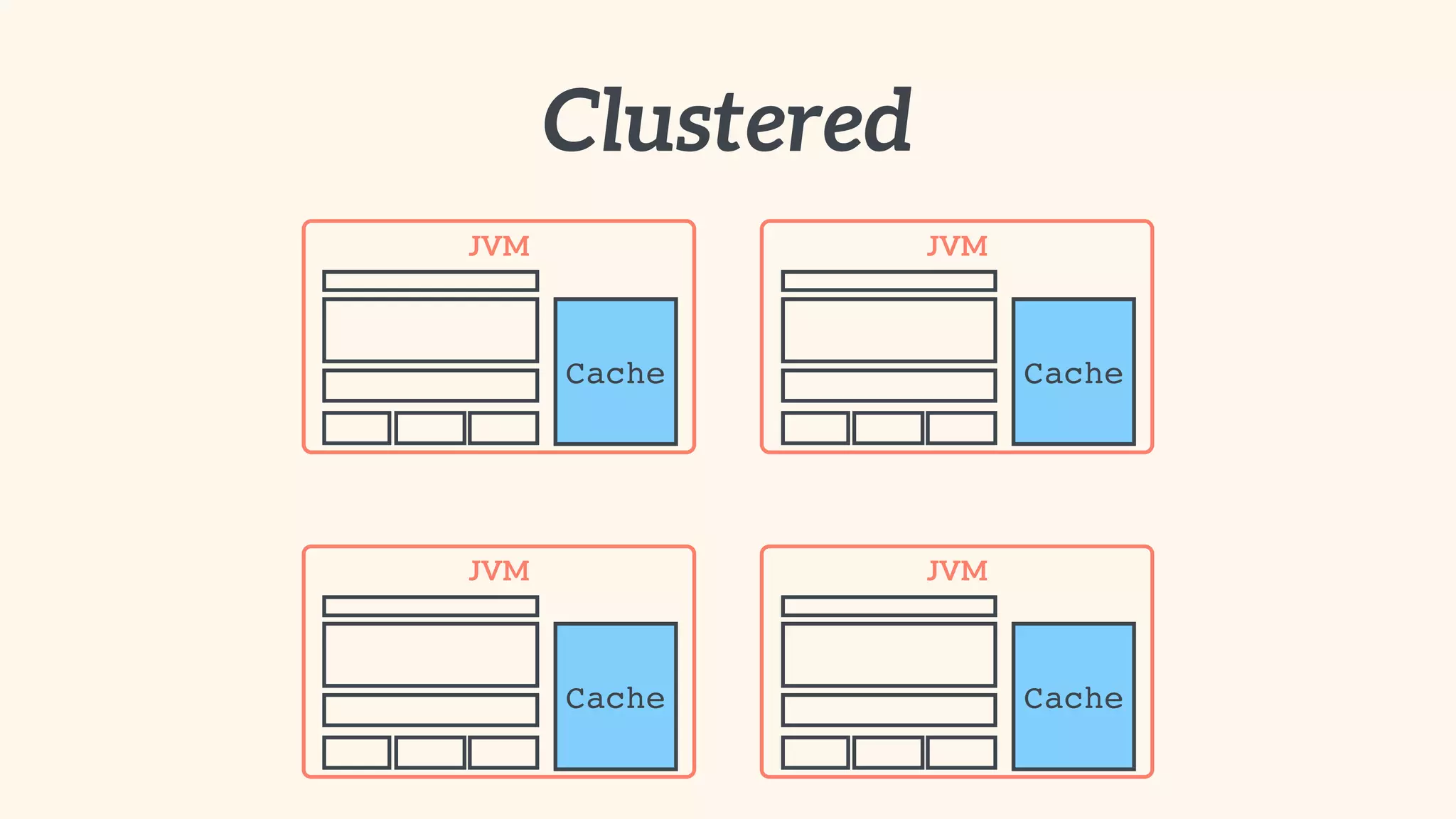
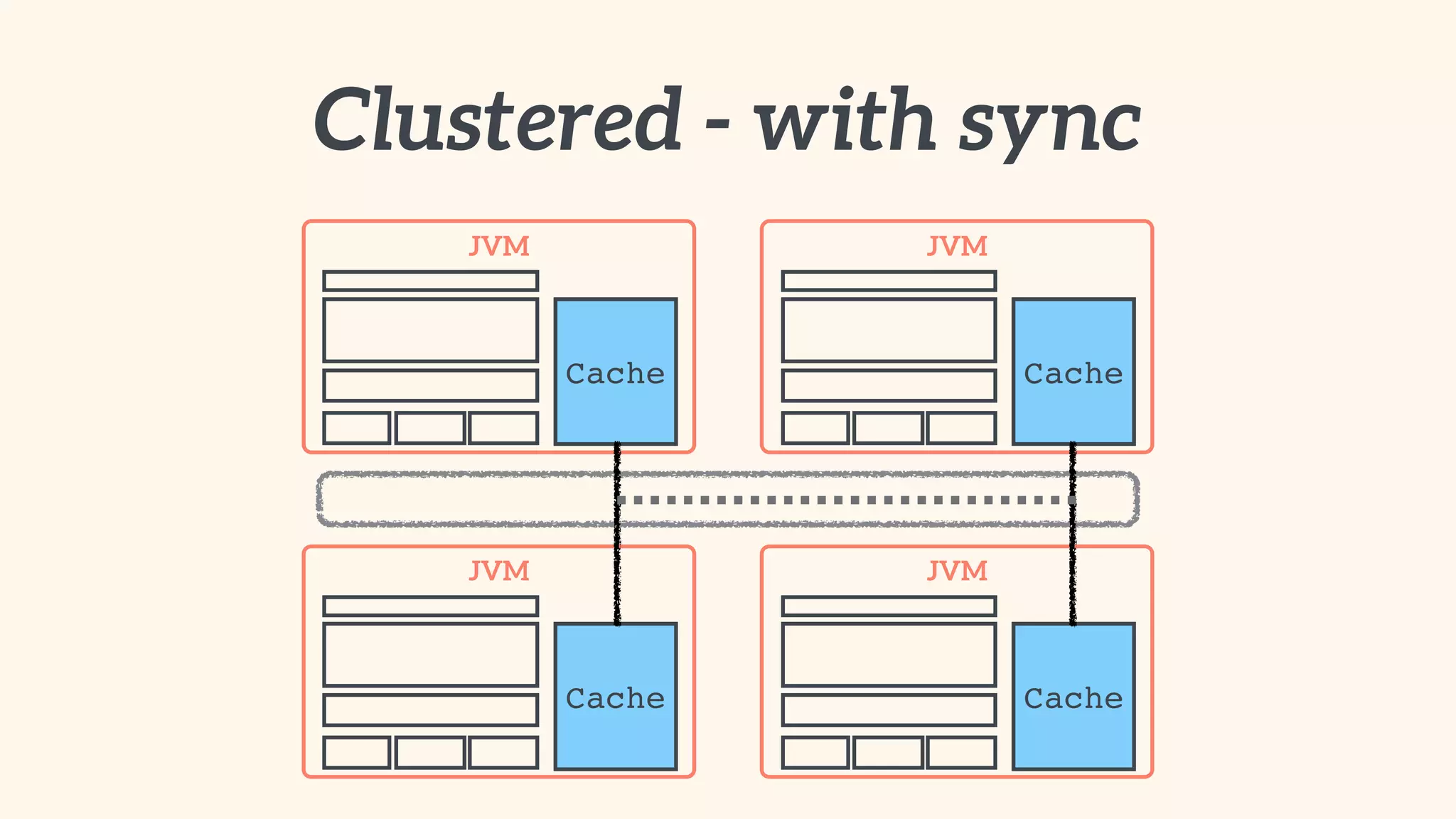
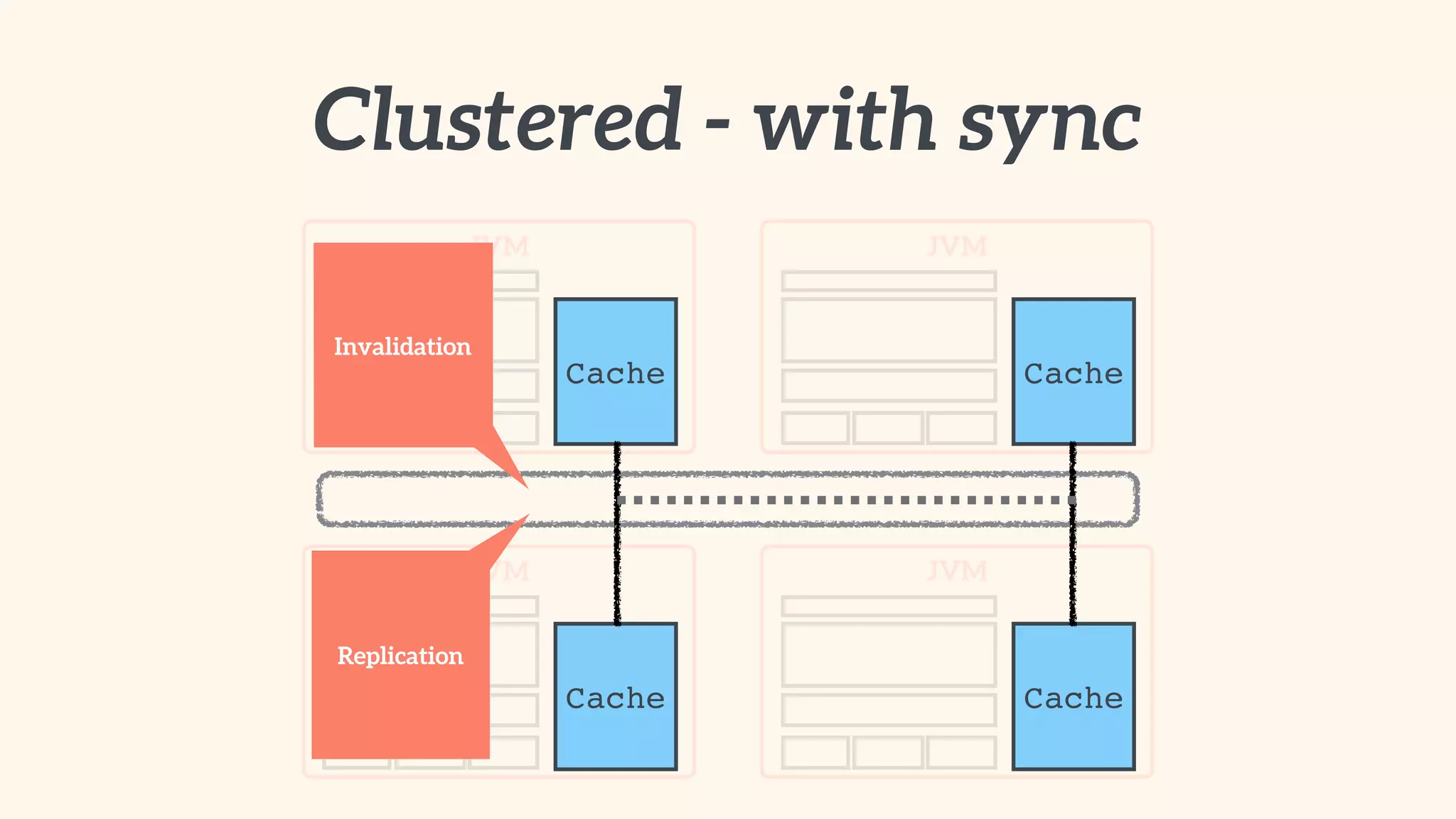
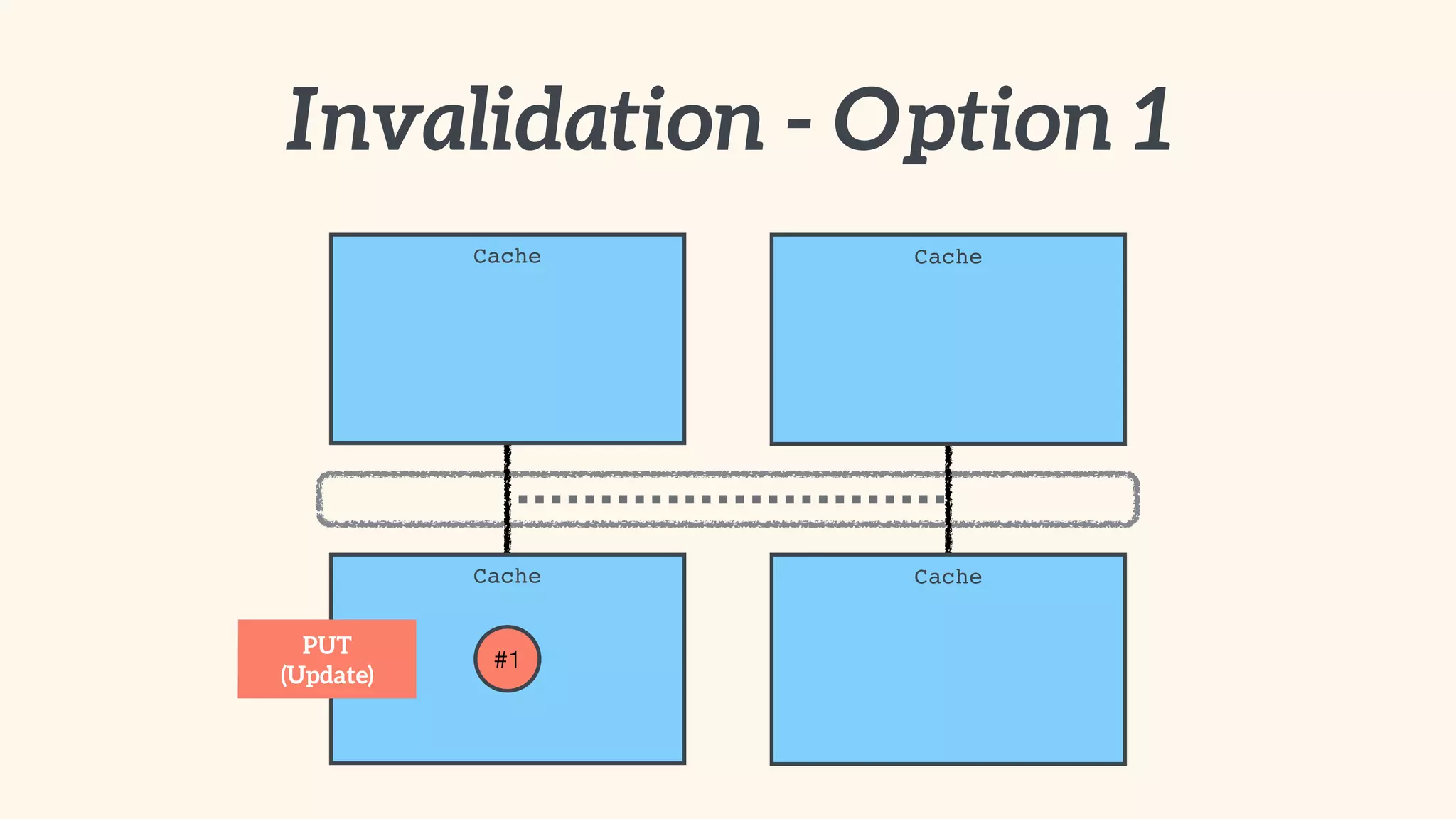
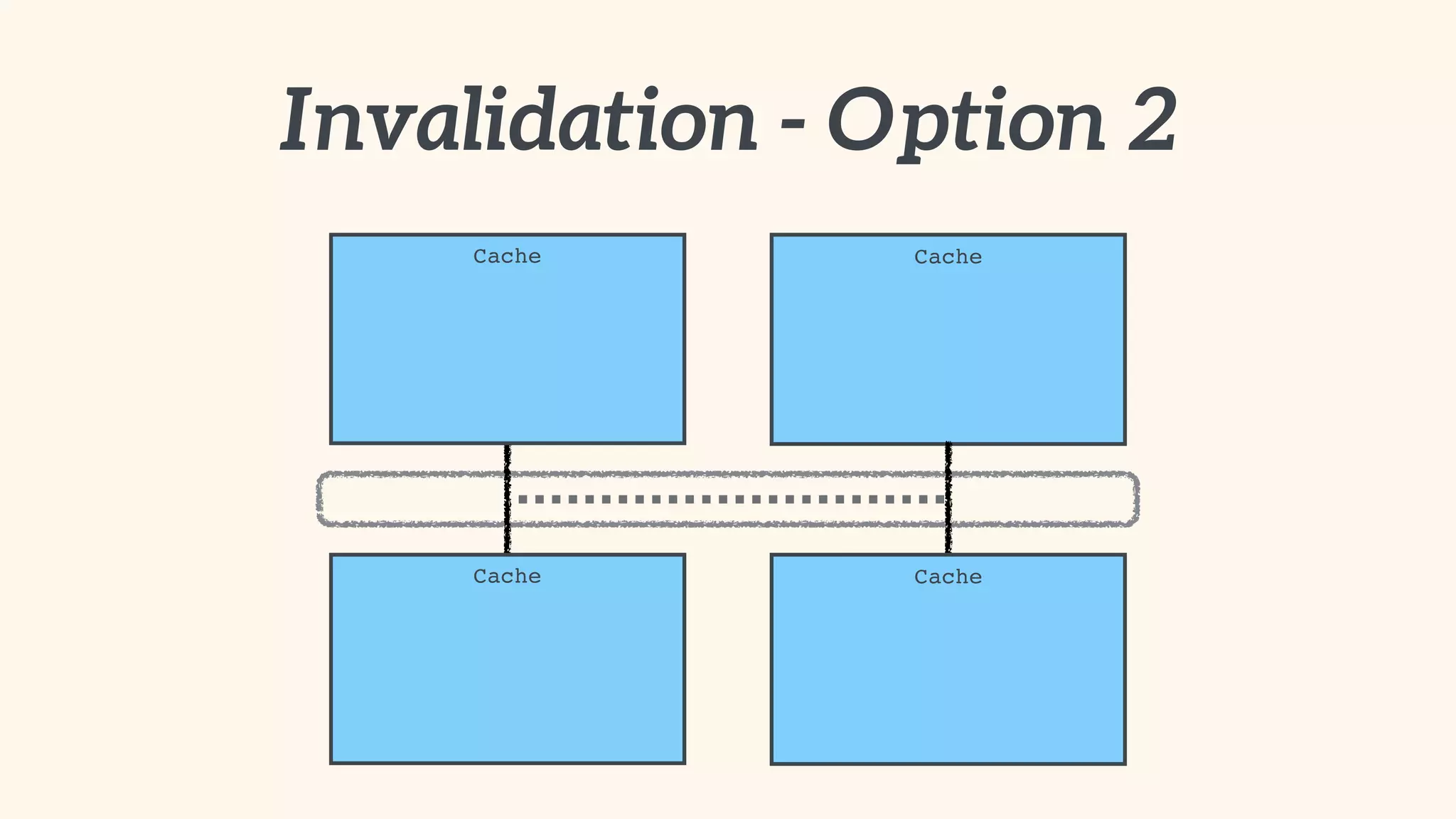
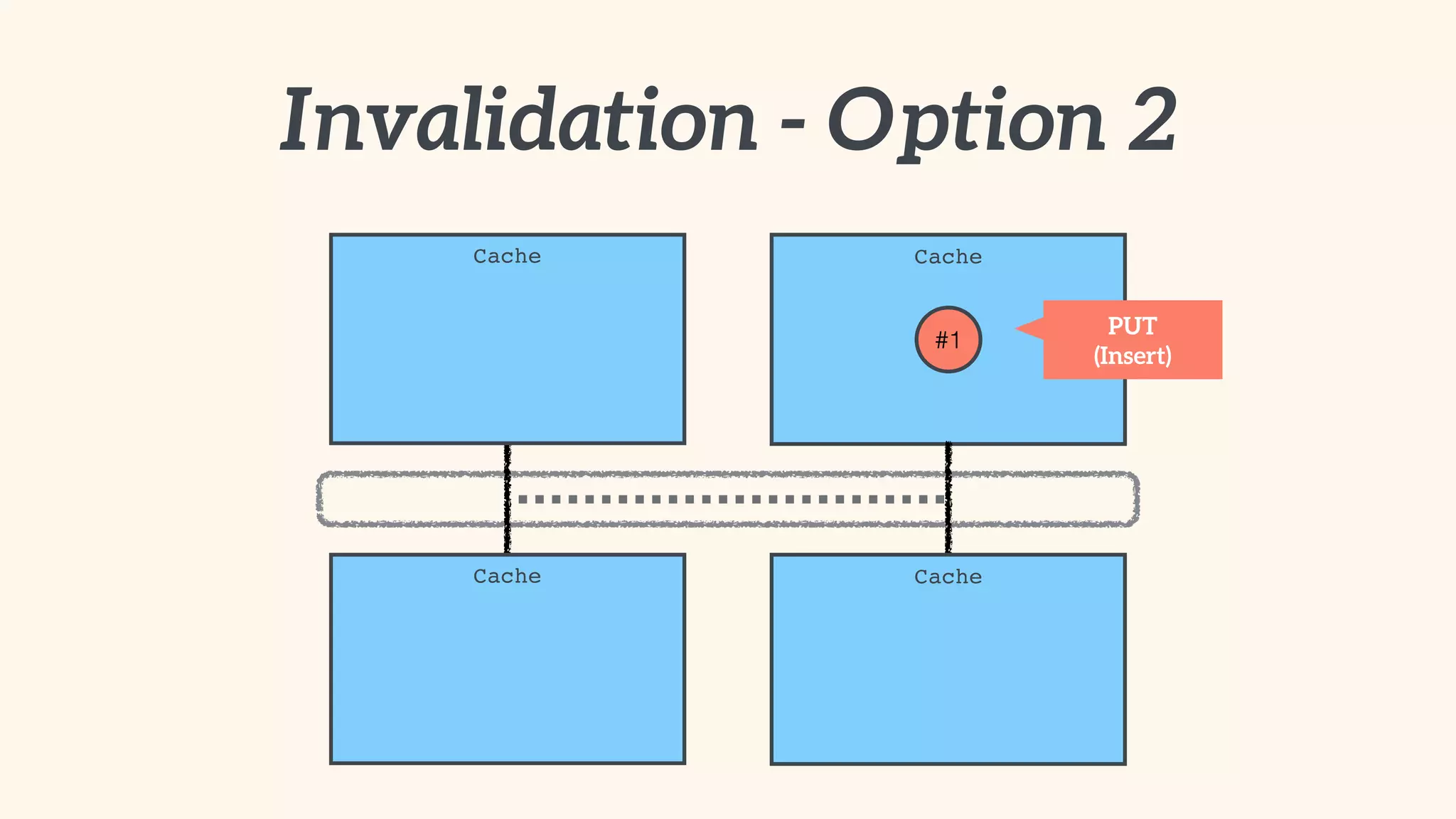
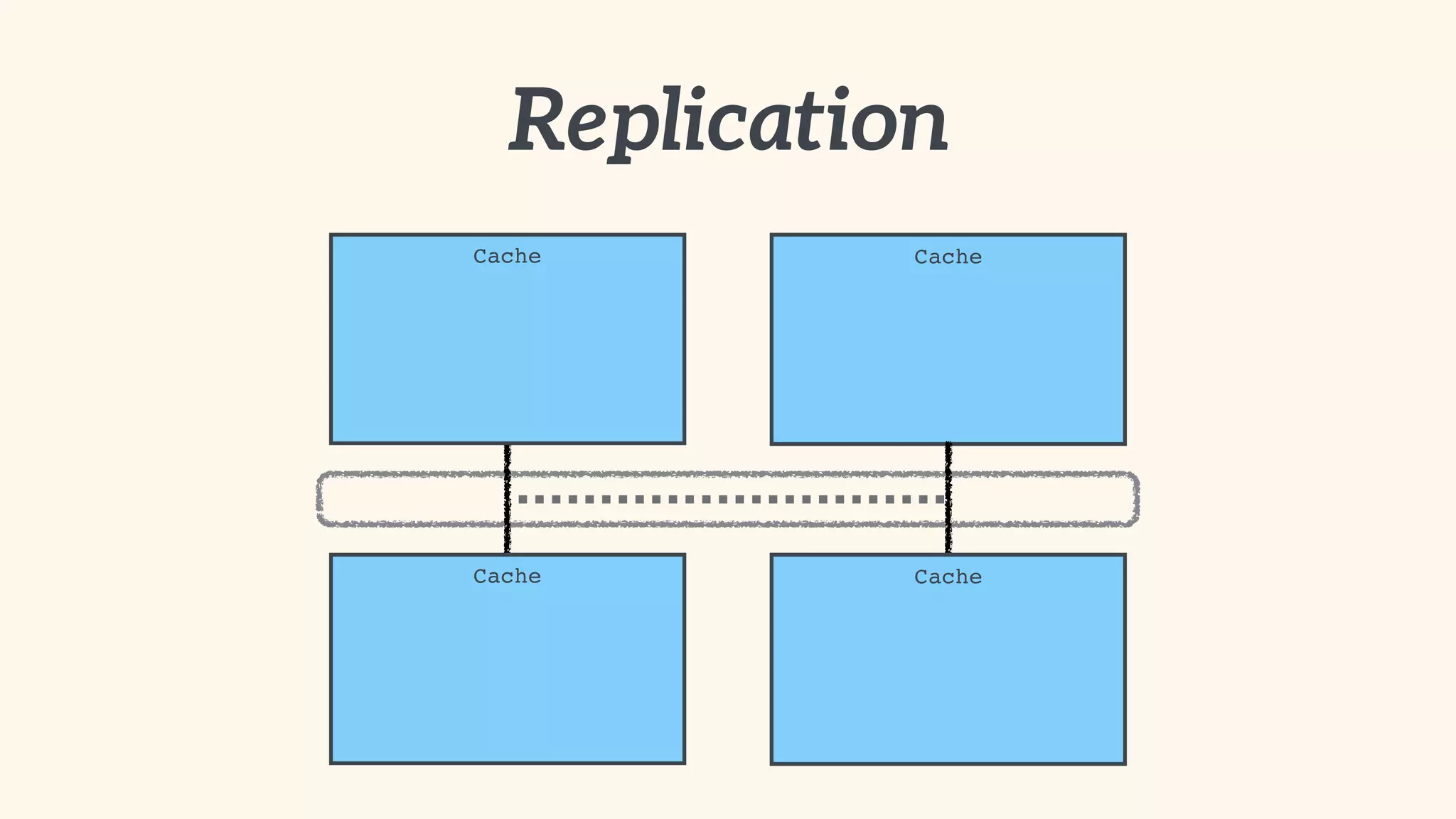
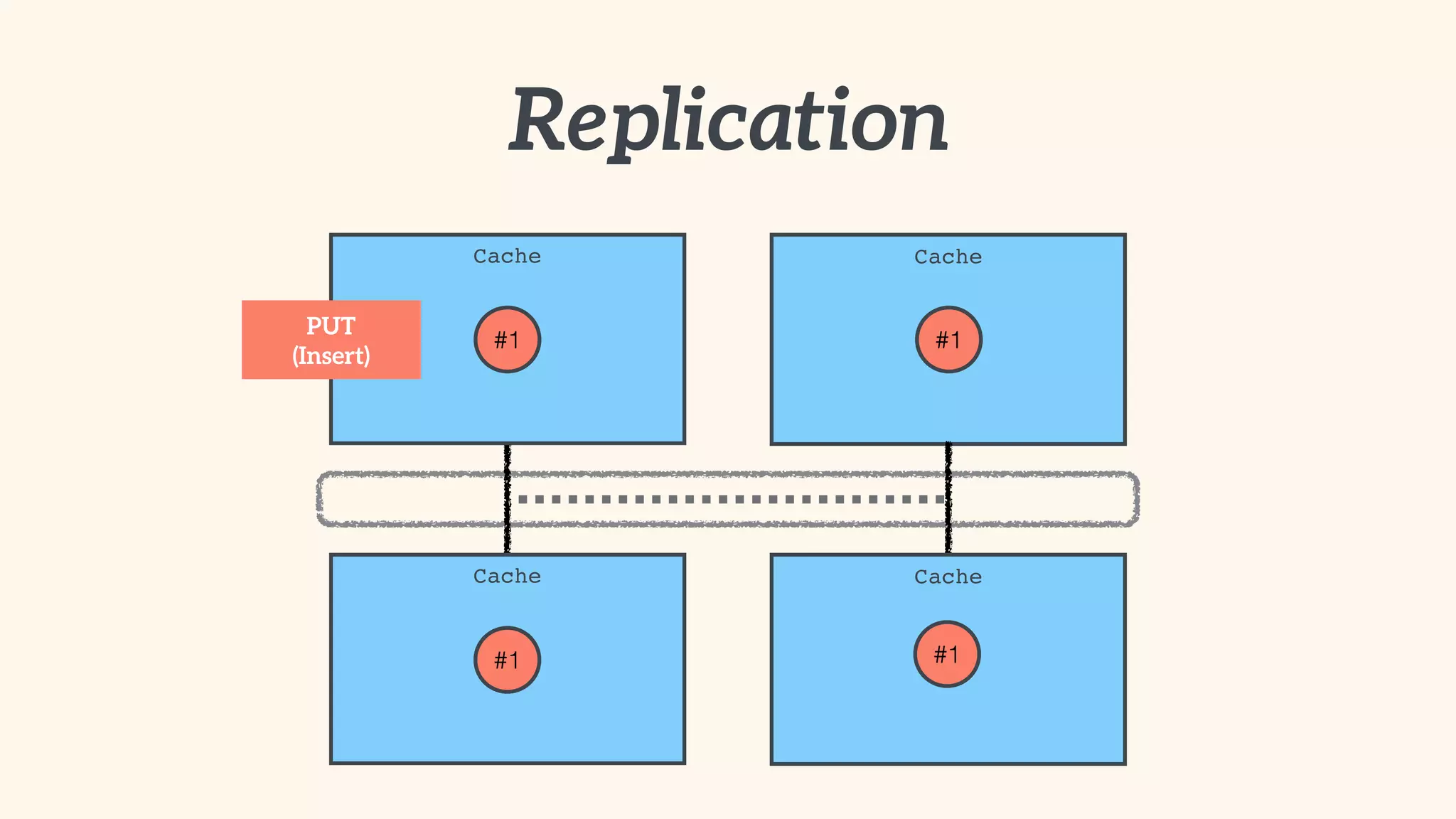
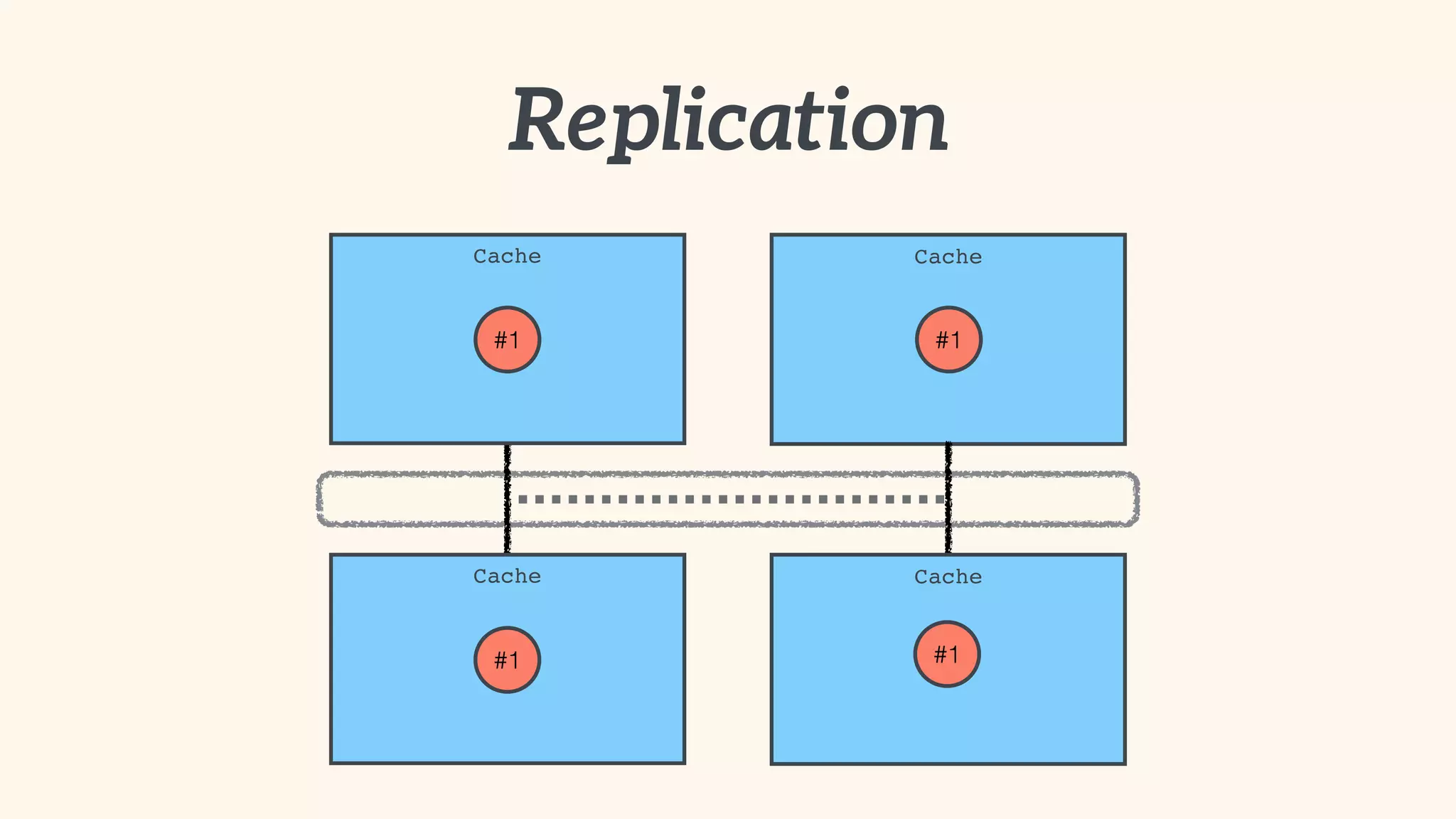
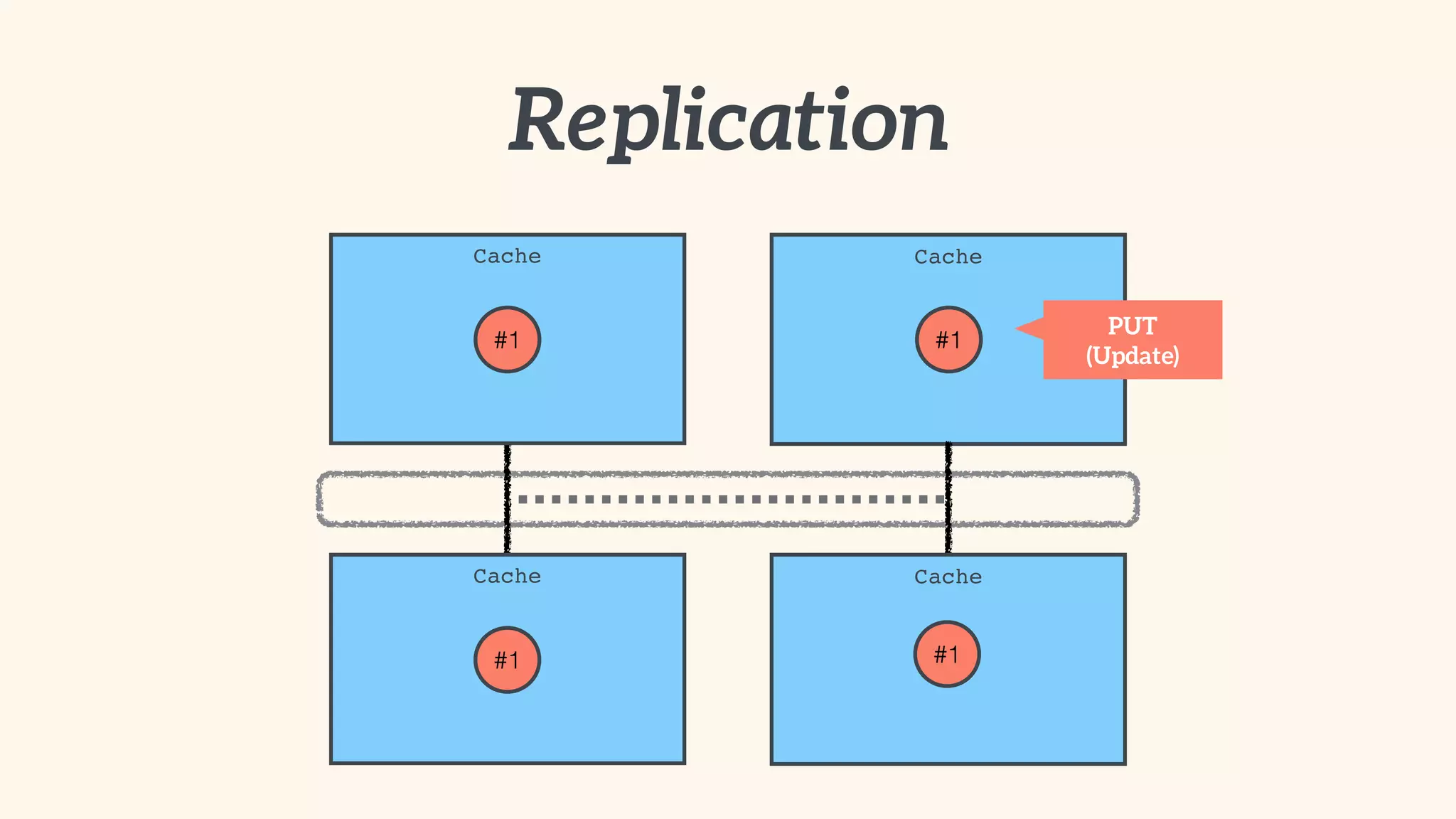
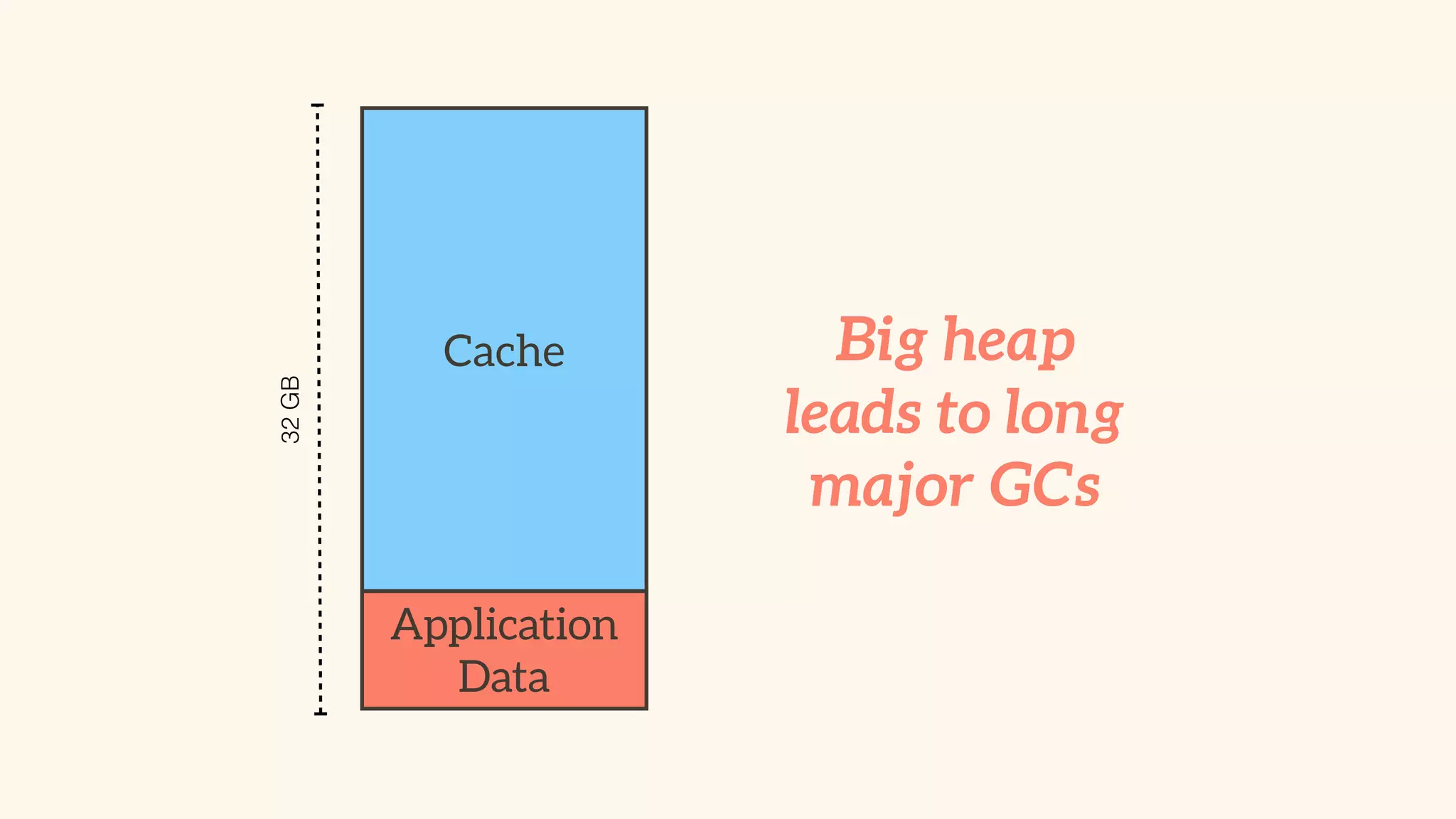
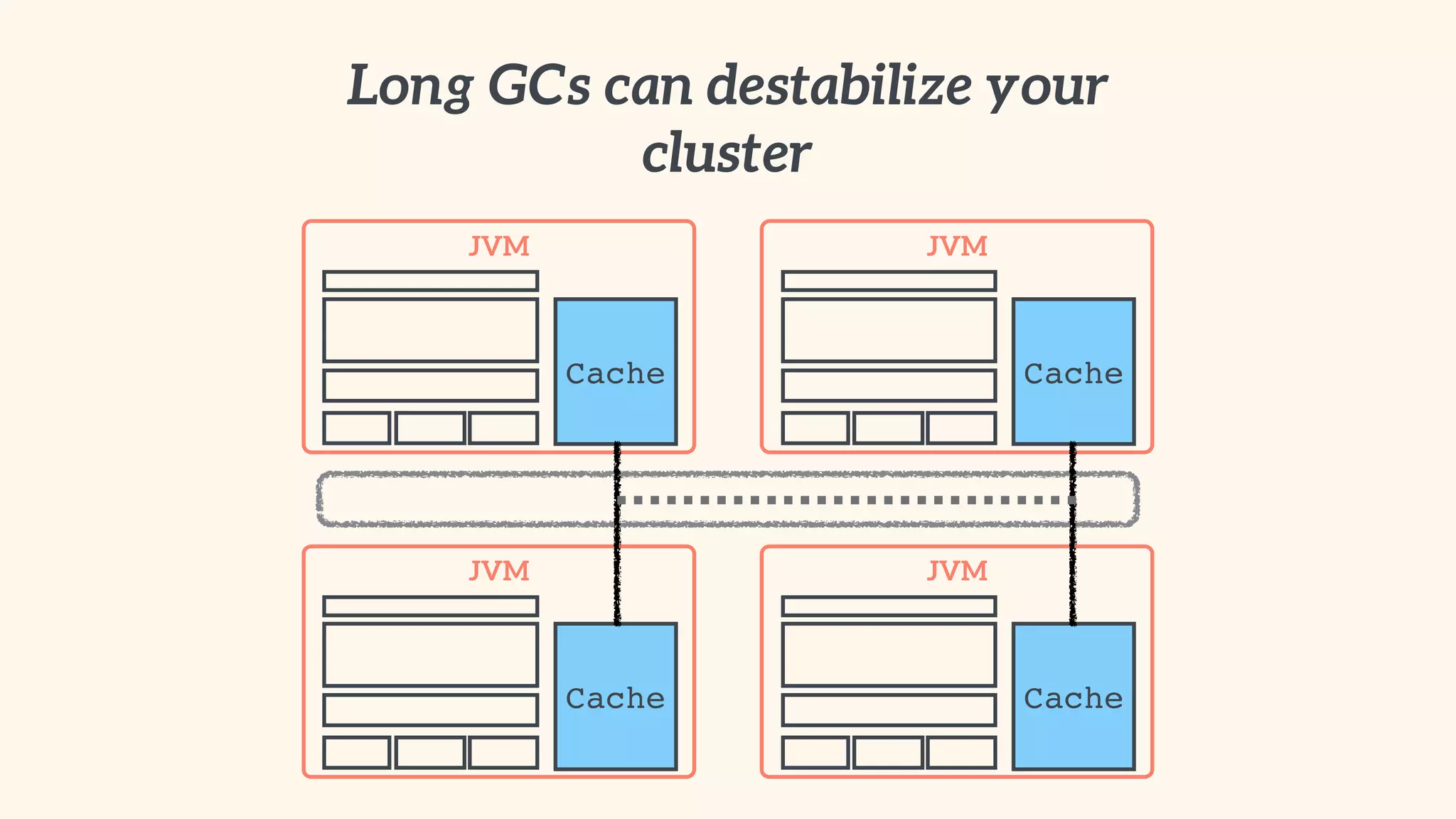
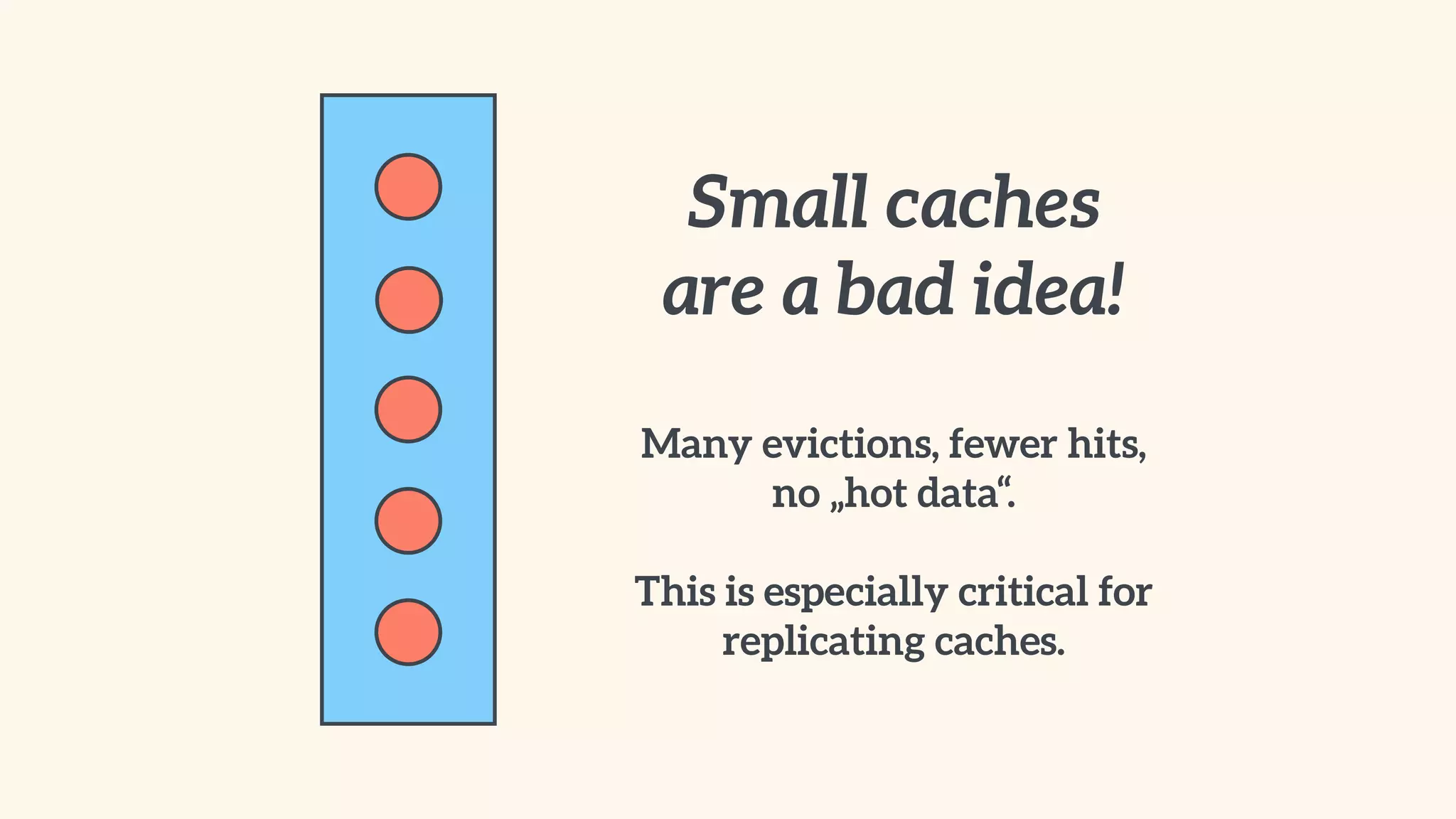
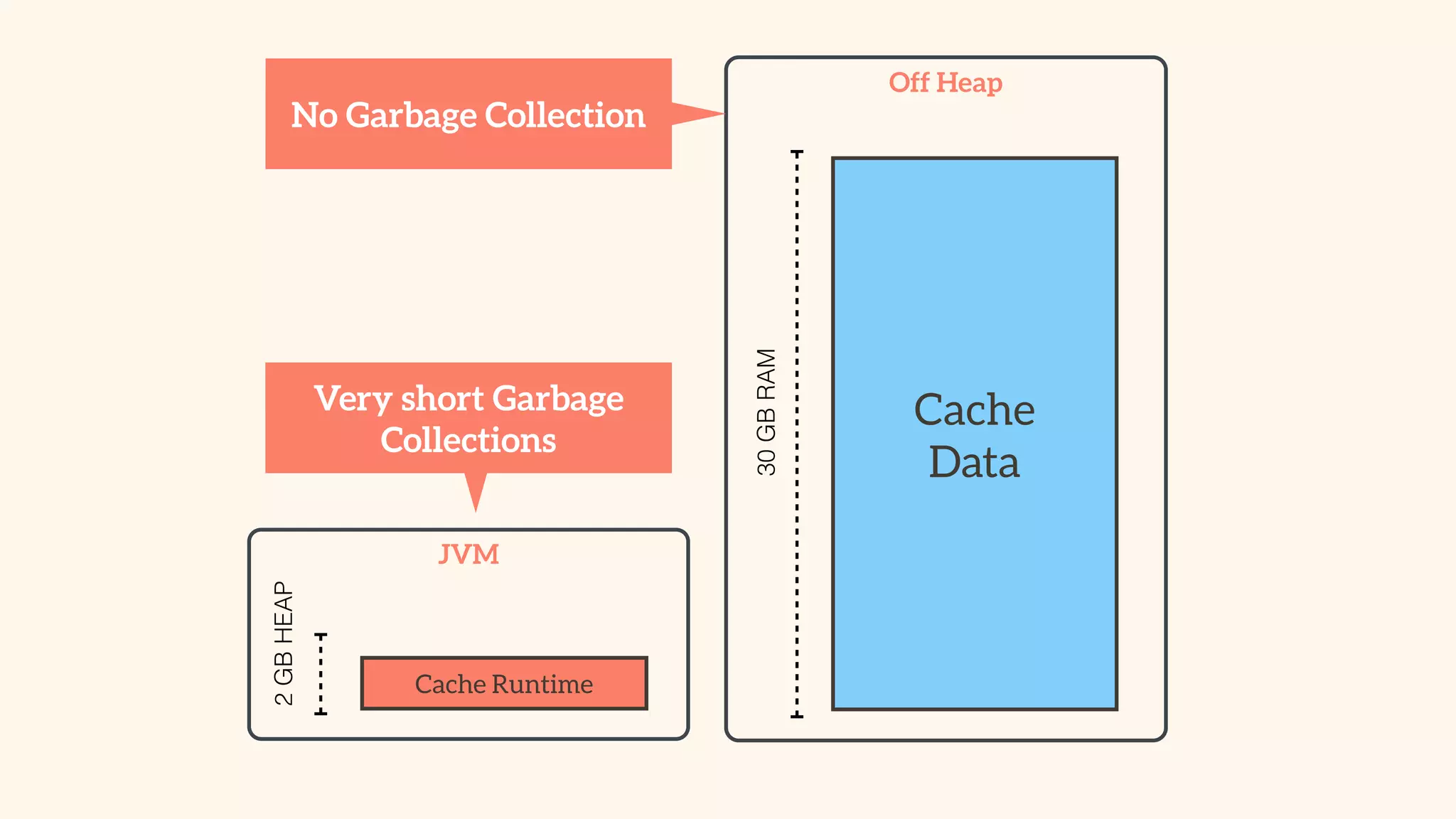
Recommendations on local vs. clustered caching, avoiding replication, managing heap size, and cache efficiency.
Guidelines for data caching, types of data suitable for caching, and utilizing distributed caches for scalability.
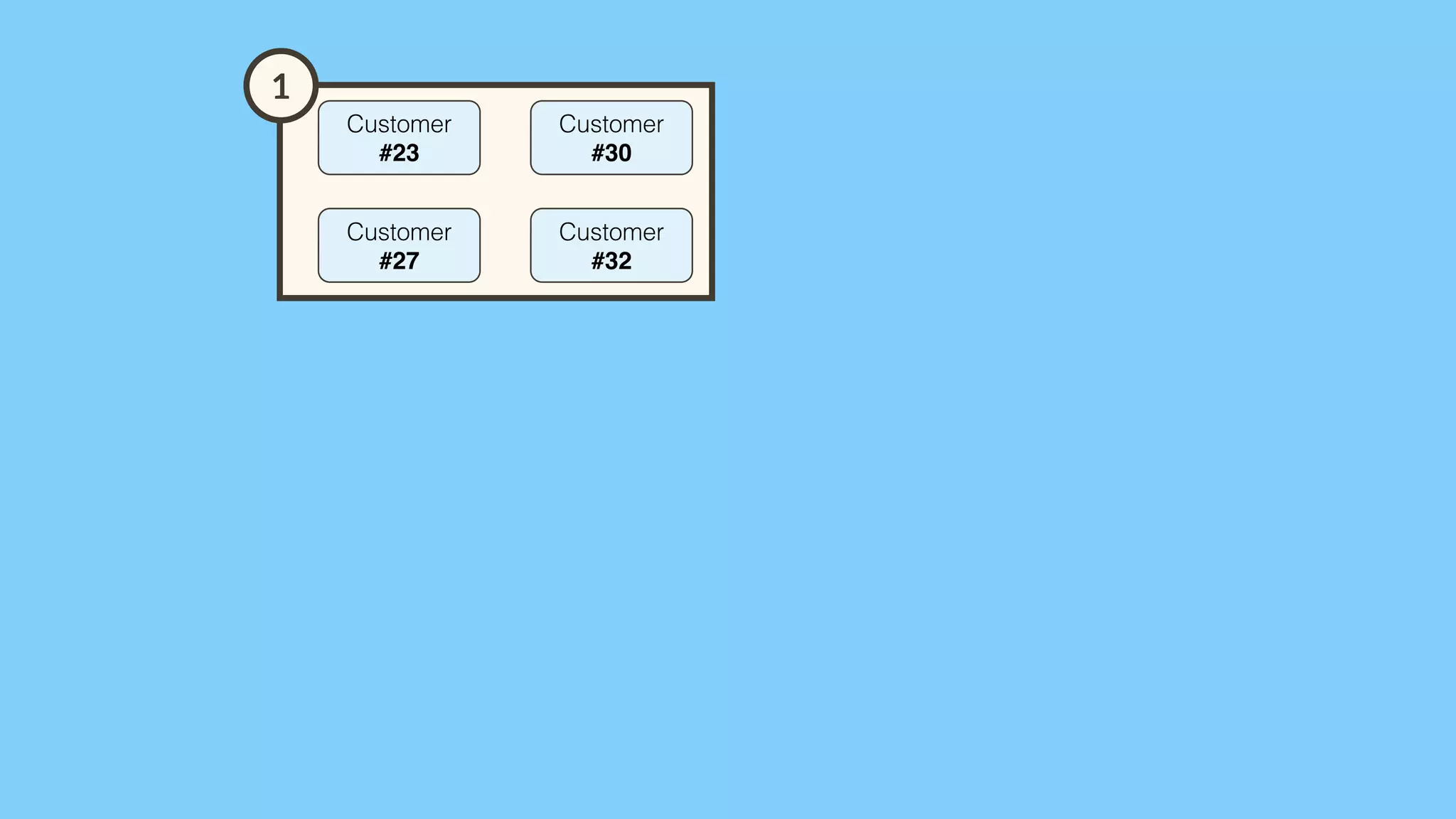
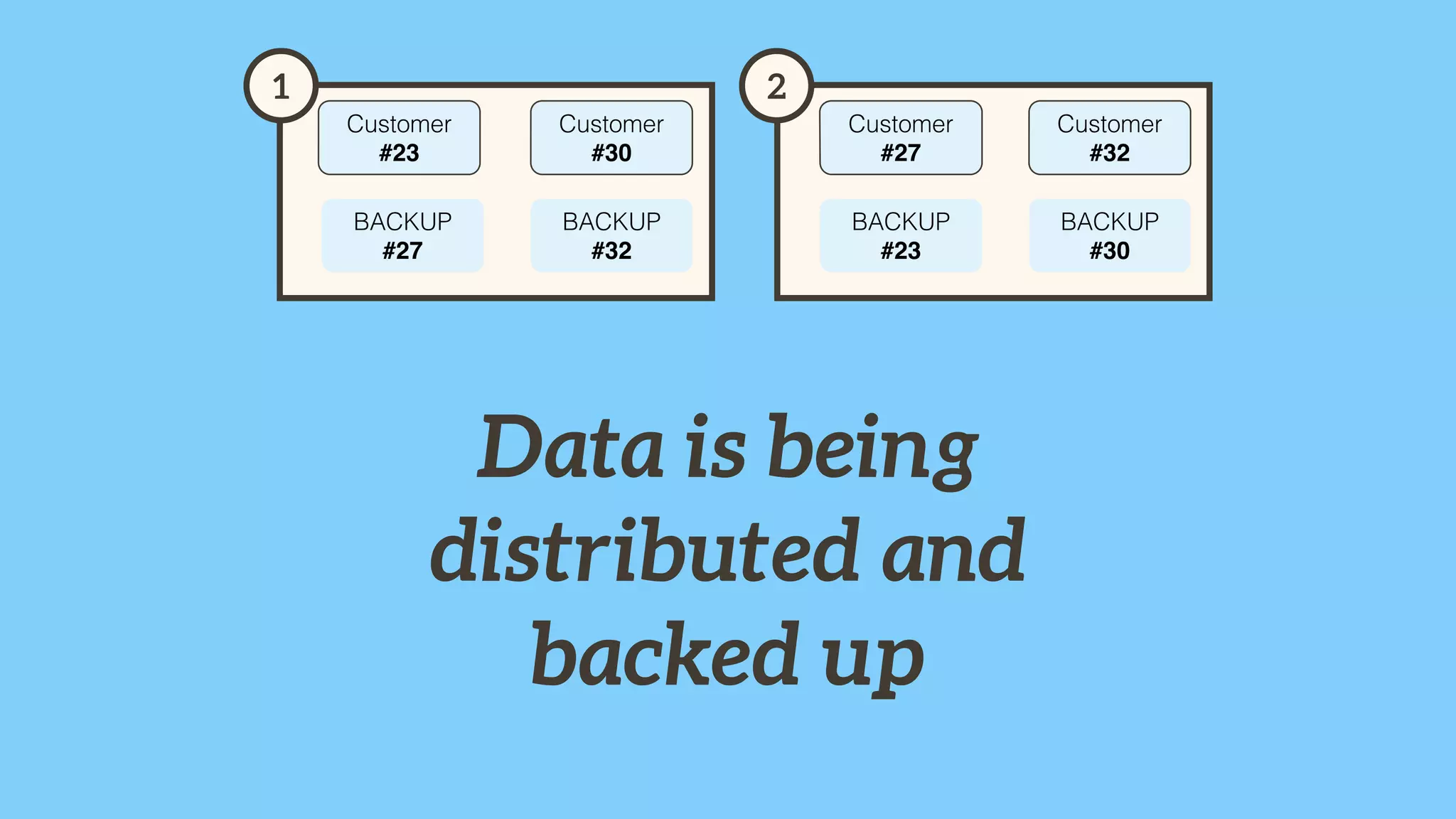
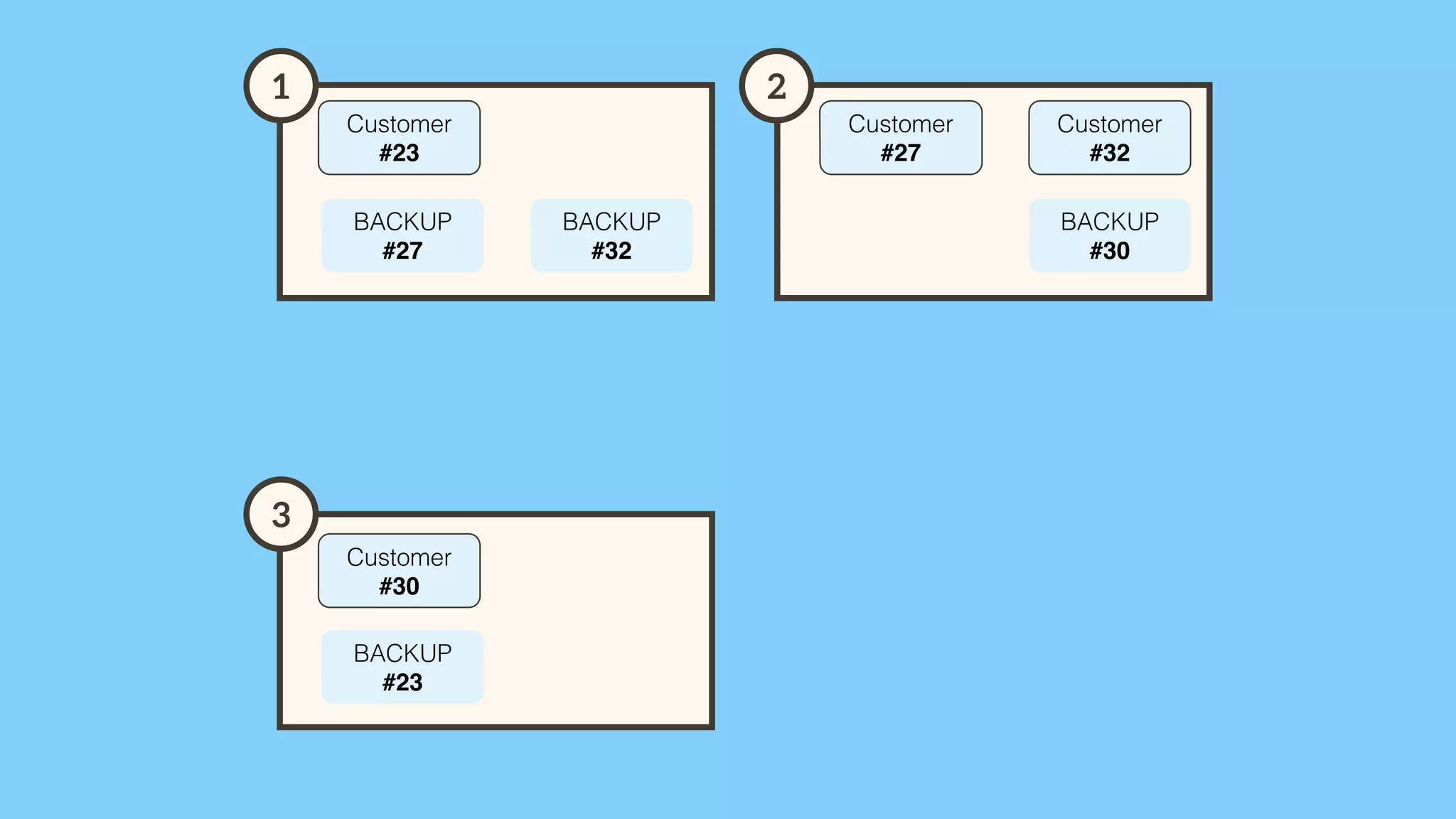
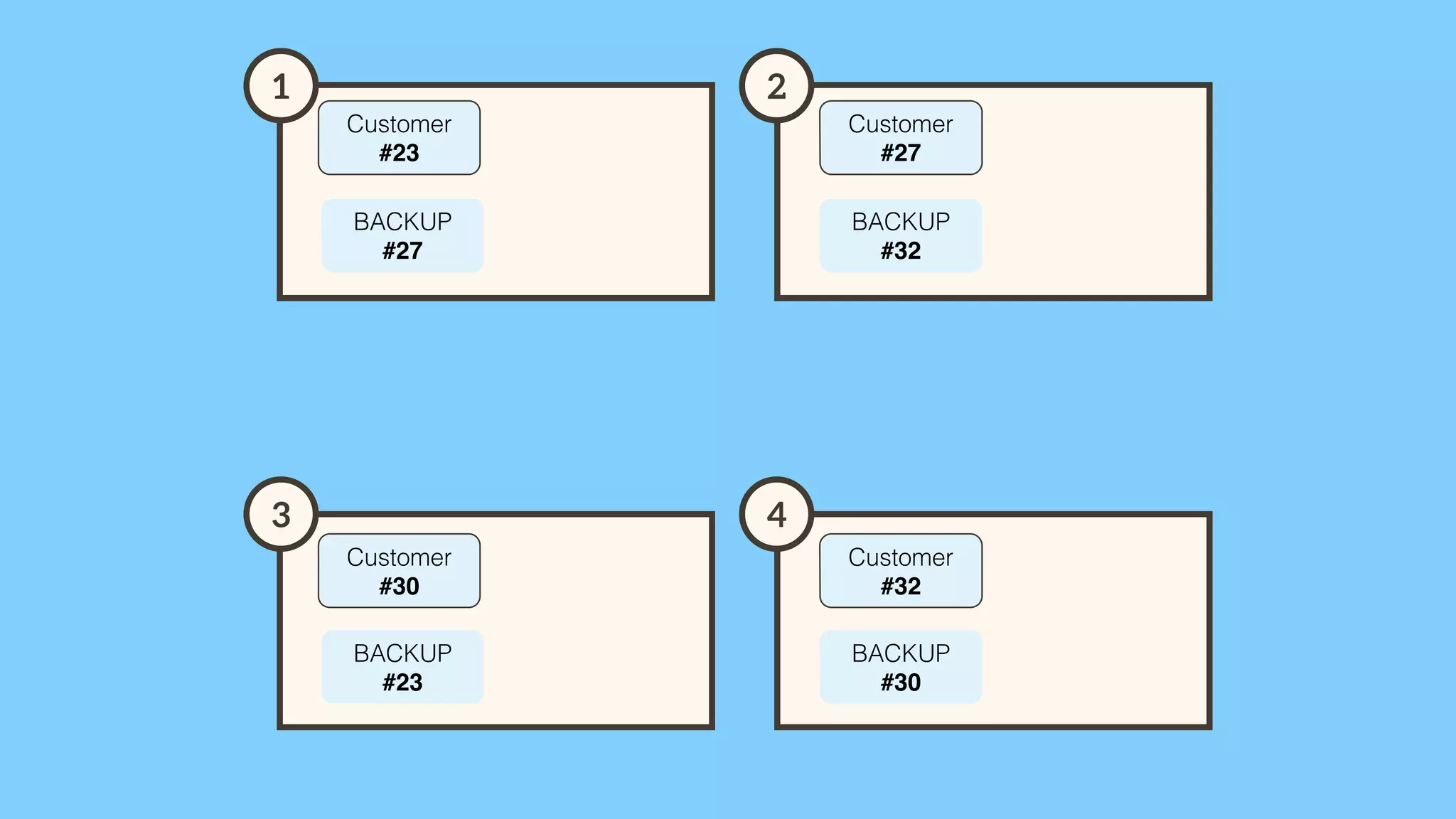
Importance of involving operations in caching strategy, managing clustered caches, and backing up data.
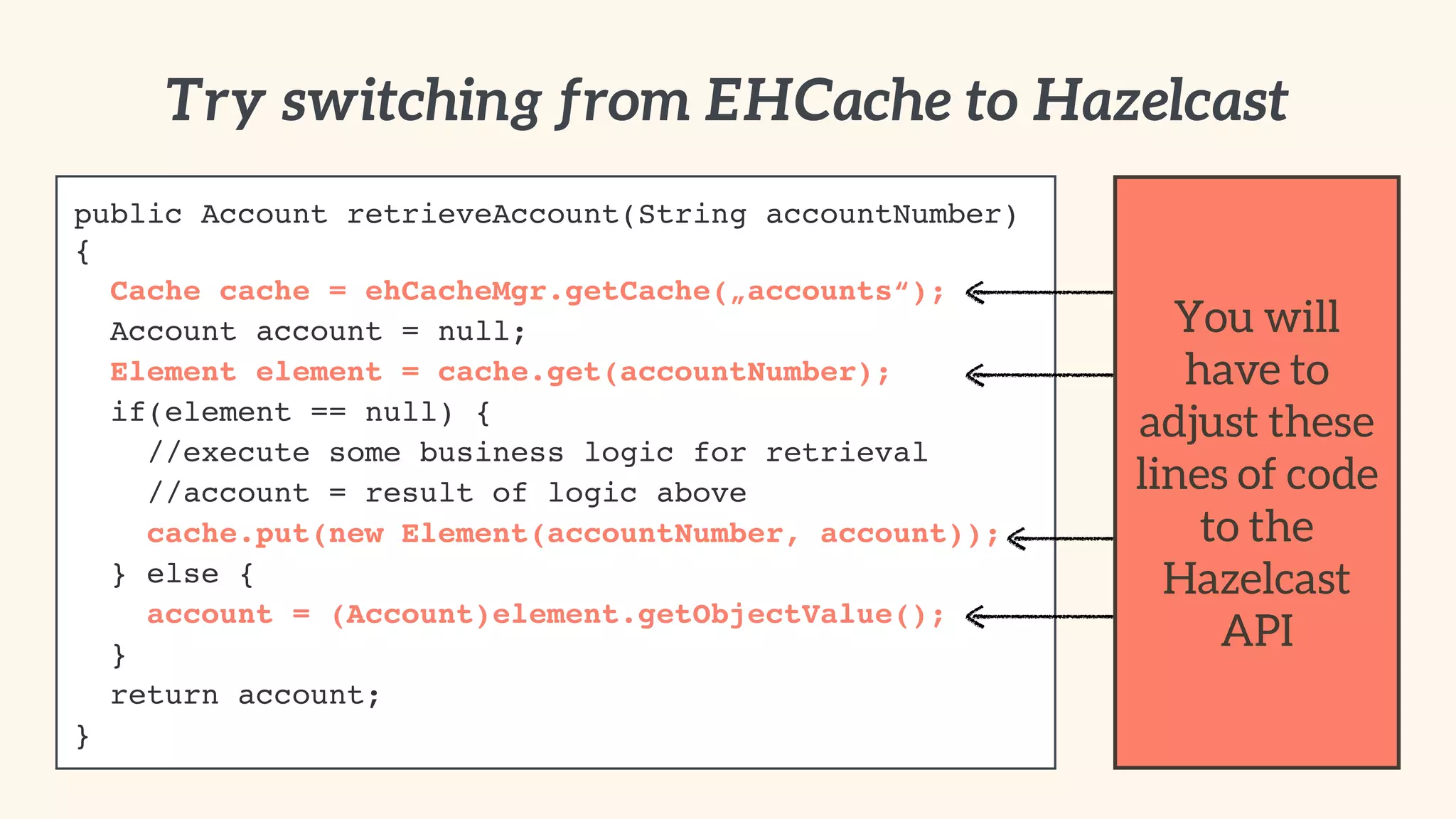
Methods to introduce caching effectively, optimize serialization, and implement using popular caching libraries.
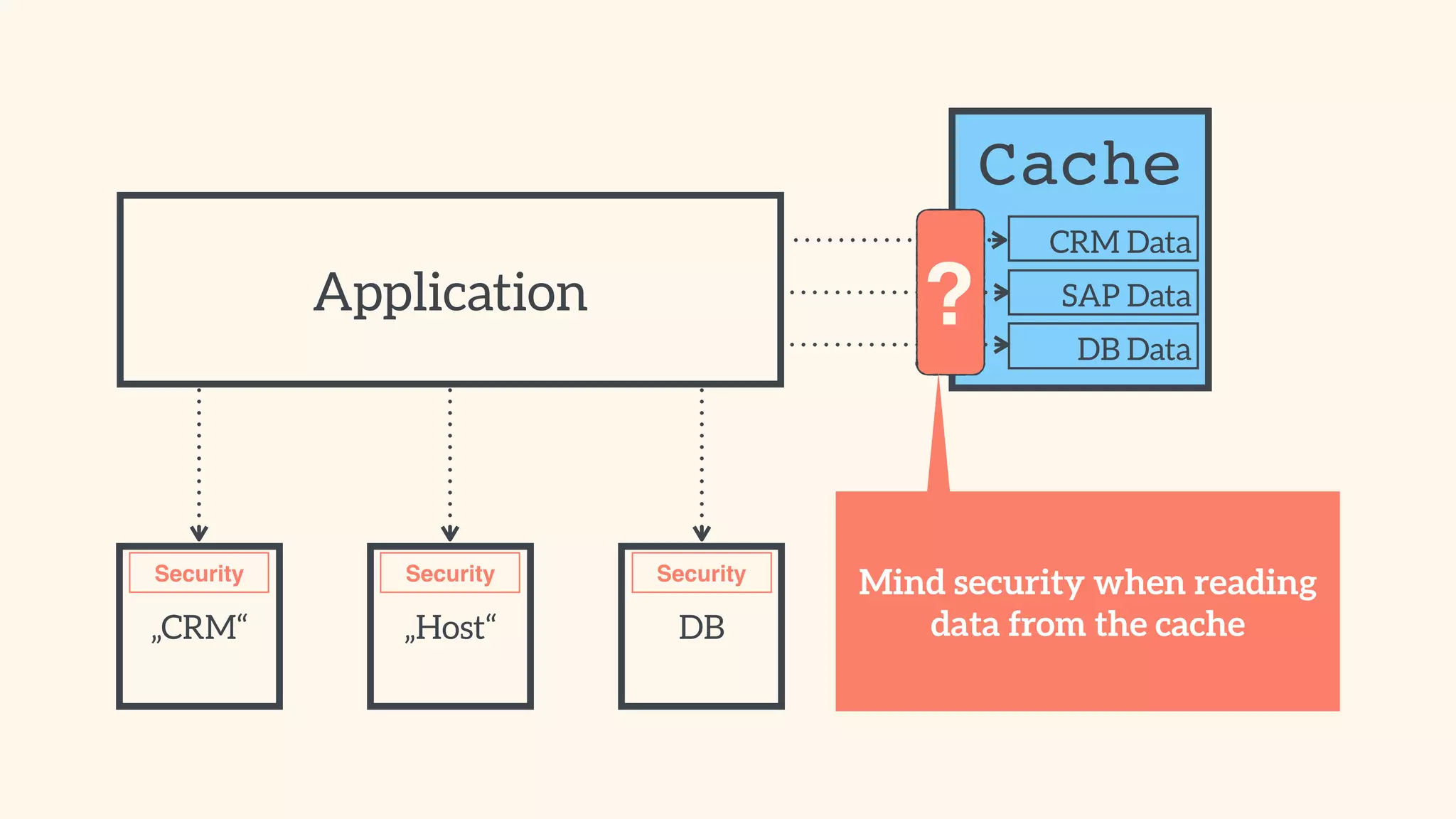
Addressing caching-related security risks and ensuring performance through proper cache management.
Best practices for abstracting cache providers in code, and using Spring's cache annotations.
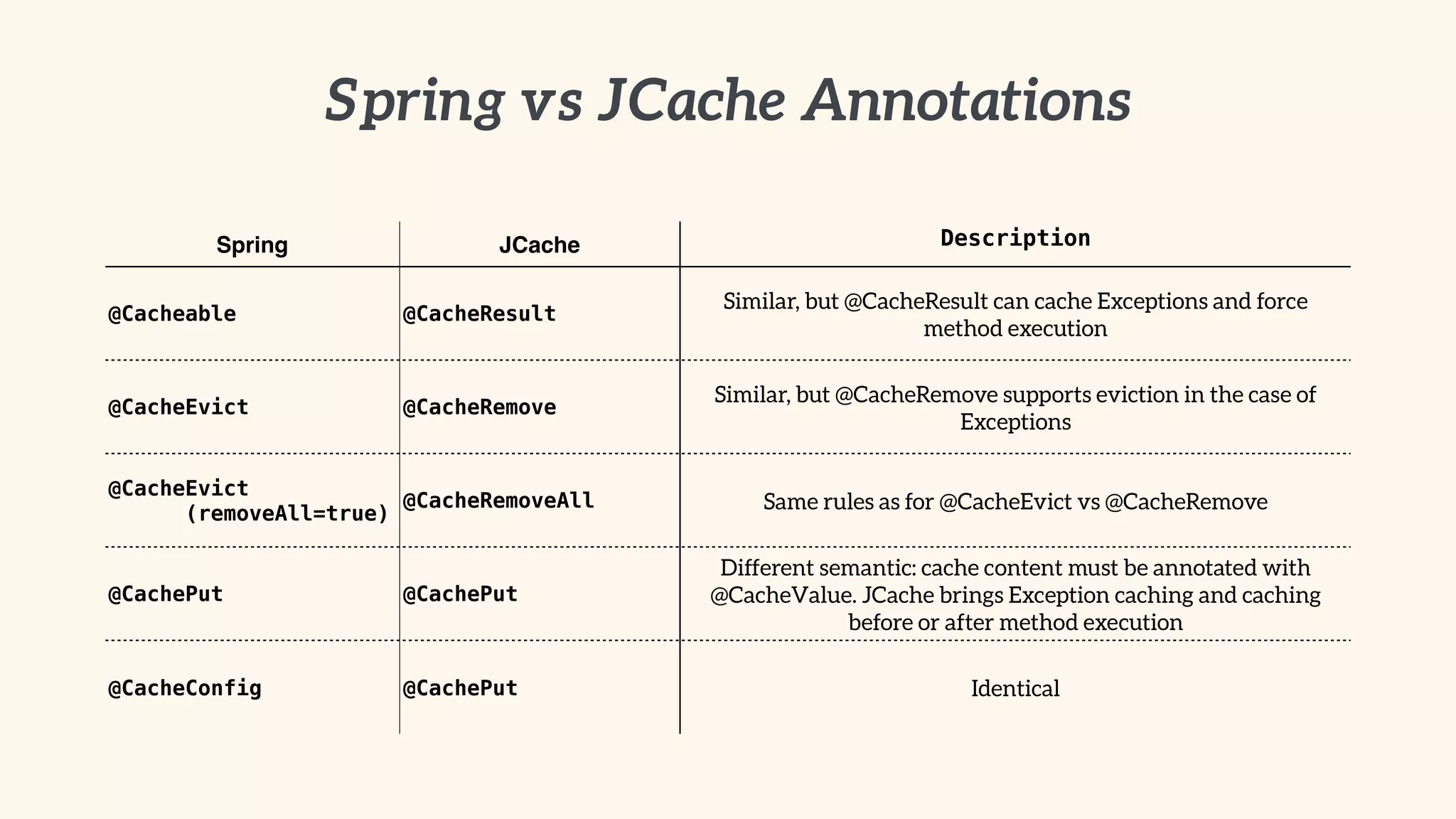
Comparison of Spring caching annotations with JCache, and steps for implementing JCache support in Spring.
Final remarks, acknowledgments, and contact information of the presenter.




































![[Hanoi-August 13] Tech Talk on Caching Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/nitecocachingsolution-130826204343-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































