Download to read offline





![Input
RGB or Grayscale Images
Unsigned integer [0,255]](https://image.slidesharecdn.com/imagesegmentationwithunet-191007034311/85/Image-Segmentation-Approaches-and-Challenges-7-320.jpg)




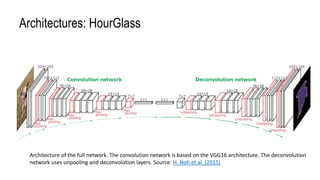








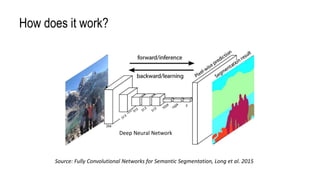
The document discusses advanced methods for semantic segmentation, particularly focusing on convolutional networks such as U-Net and DeepLab architectures. It emphasizes the challenges of capturing multi-scale context in pixel-level classification tasks for applications in various fields, including biomedical imaging and satellite data analysis. The conclusion highlights the necessity of efficiently integrating local and global context for accurate pixel-wise predictions.




































































![Human Reproduction [ Reproductive System ] Notes @irfanullah_mehar Irfanullah...](https://cdn.slidesharecdn.com/ss_thumbnails/humanreproductionreproductivesystemnotesirfanullahmeharirfanullahmeharjanantantra-260111172350-56e85778-thumbnail.jpg?width=640&height=640&fit=bounds)

















