Downloaded 618 times


![Denis Shestakov
Current Challenges in Web Crawling
ICWE’13, Aalborg, Denmark, 08.07.2013
2/80
References to this tutorial
To cite please use:
D. Shestakov, "Current Challenges in Web Crawling," in
Proc. ICWE 2013, 2013, pp. 518-521.
[BibTeX]](https://image.slidesharecdn.com/icwe13tutorialwebcrawling-130710094801-phpapp01/85/Current-challenges-in-web-crawling-2-320.jpg)



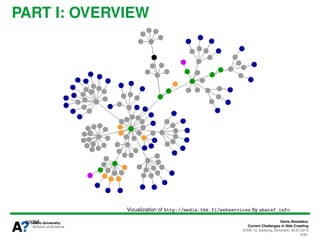


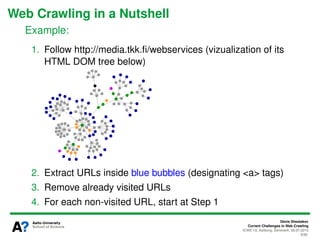




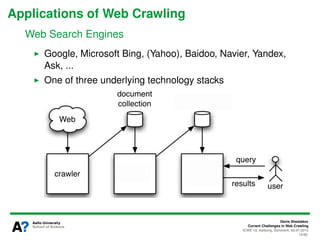
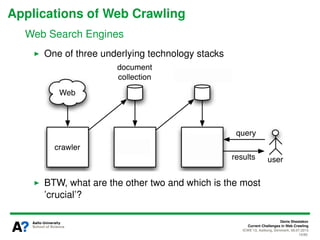
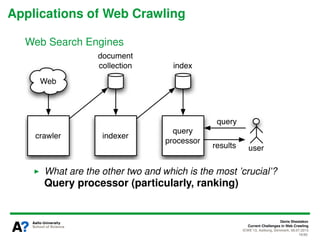




















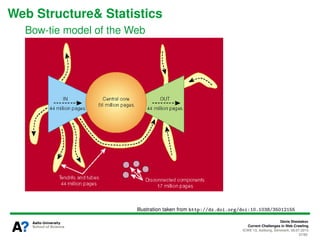
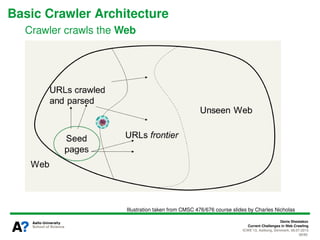
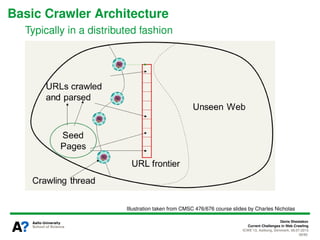

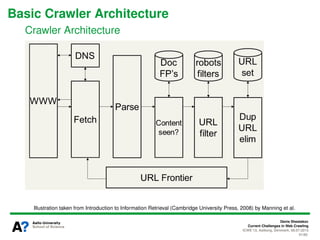



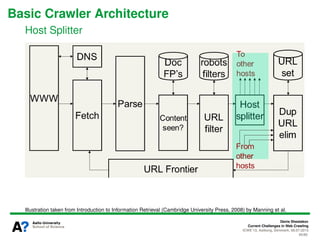



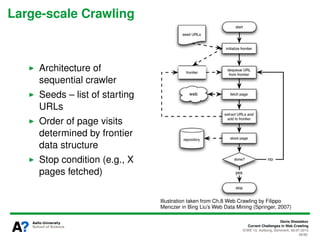
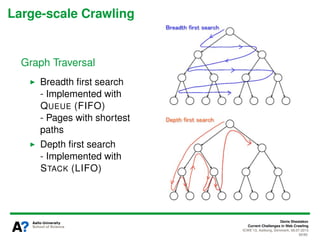


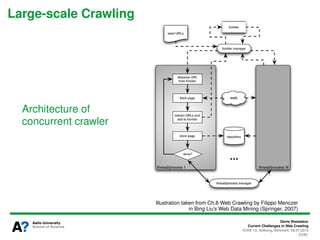








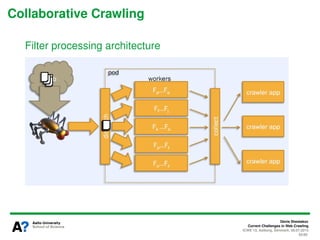
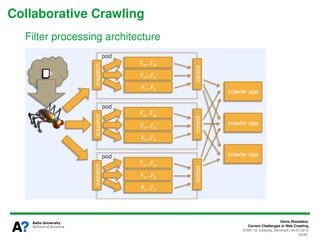

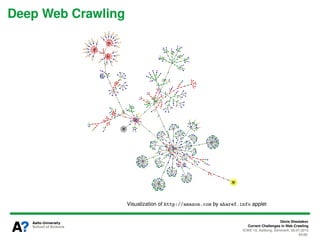
















The document presents a tutorial on the current challenges of web crawling, highlighting the processes, architecture, and applications of web crawlers. It discusses various types of crawlers, their roles in web services, industrial versus academic approaches, and the importance of crawler politeness through protocols like robots.txt. Future directions and potential improvements in web crawling techniques are also explored.





























































































