Download to read offline




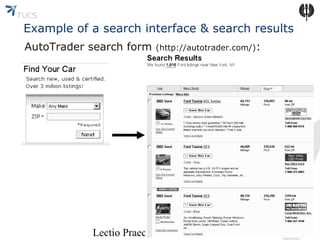







The document discusses the challenges of accessing the deep web, which consists of databases not indexed by search engines like Google. It highlights the need for automated querying methods to retrieve information and characterizes the deep web based on new survey methods, specifically focusing on Russian web databases. The future work focuses on creating a comprehensive directory of web databases to improve accessibility and discovery.










































































