




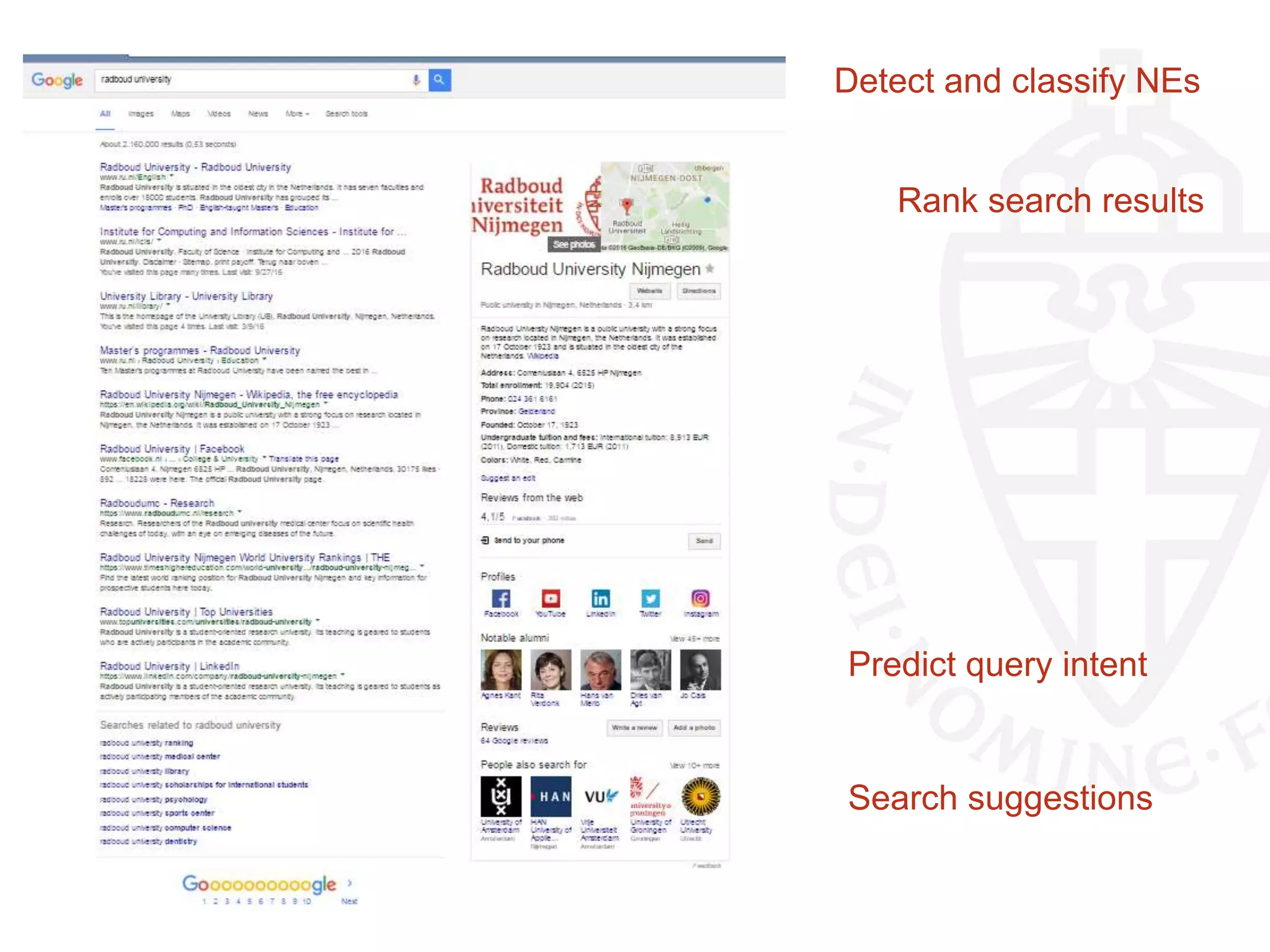
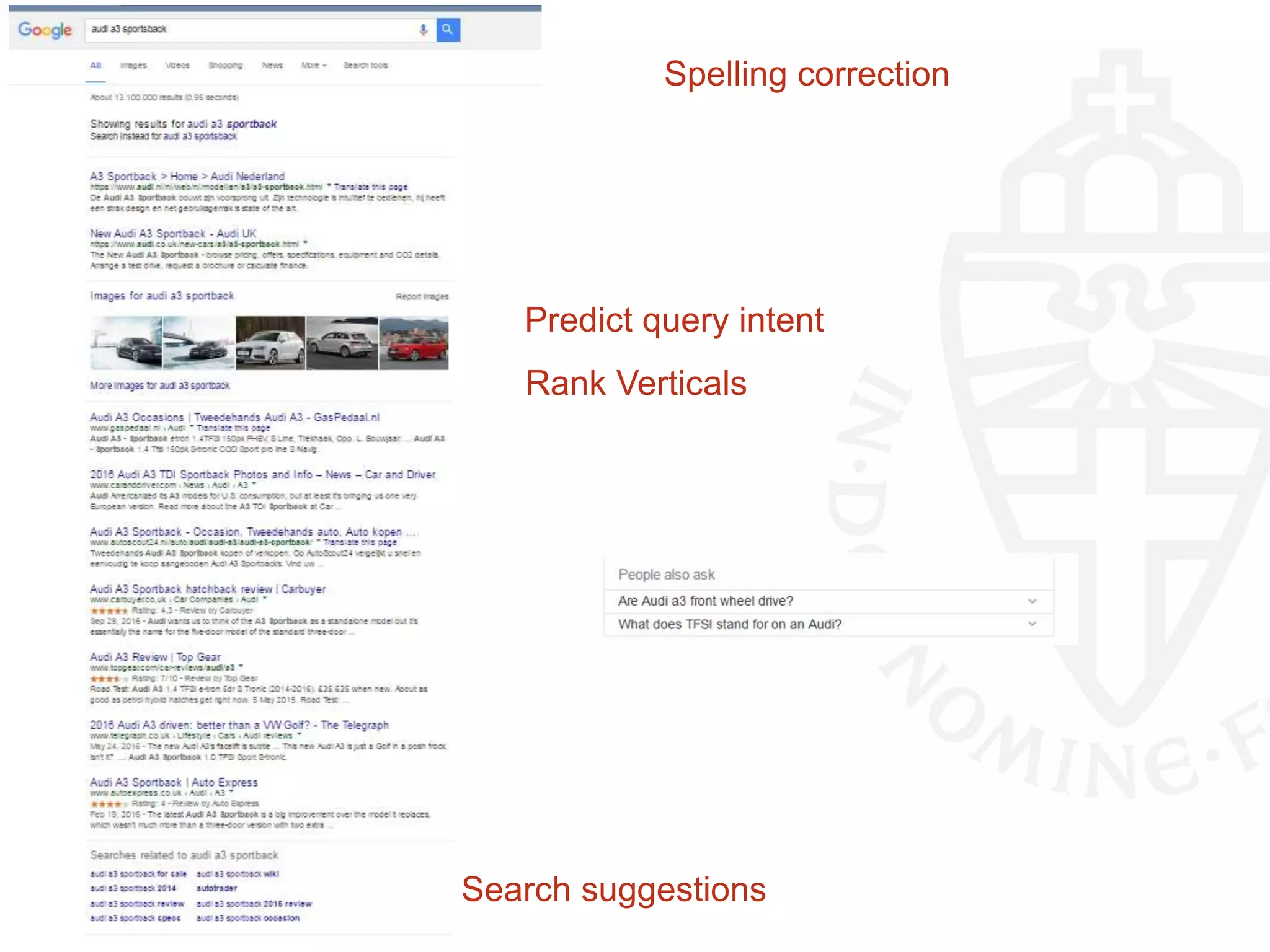





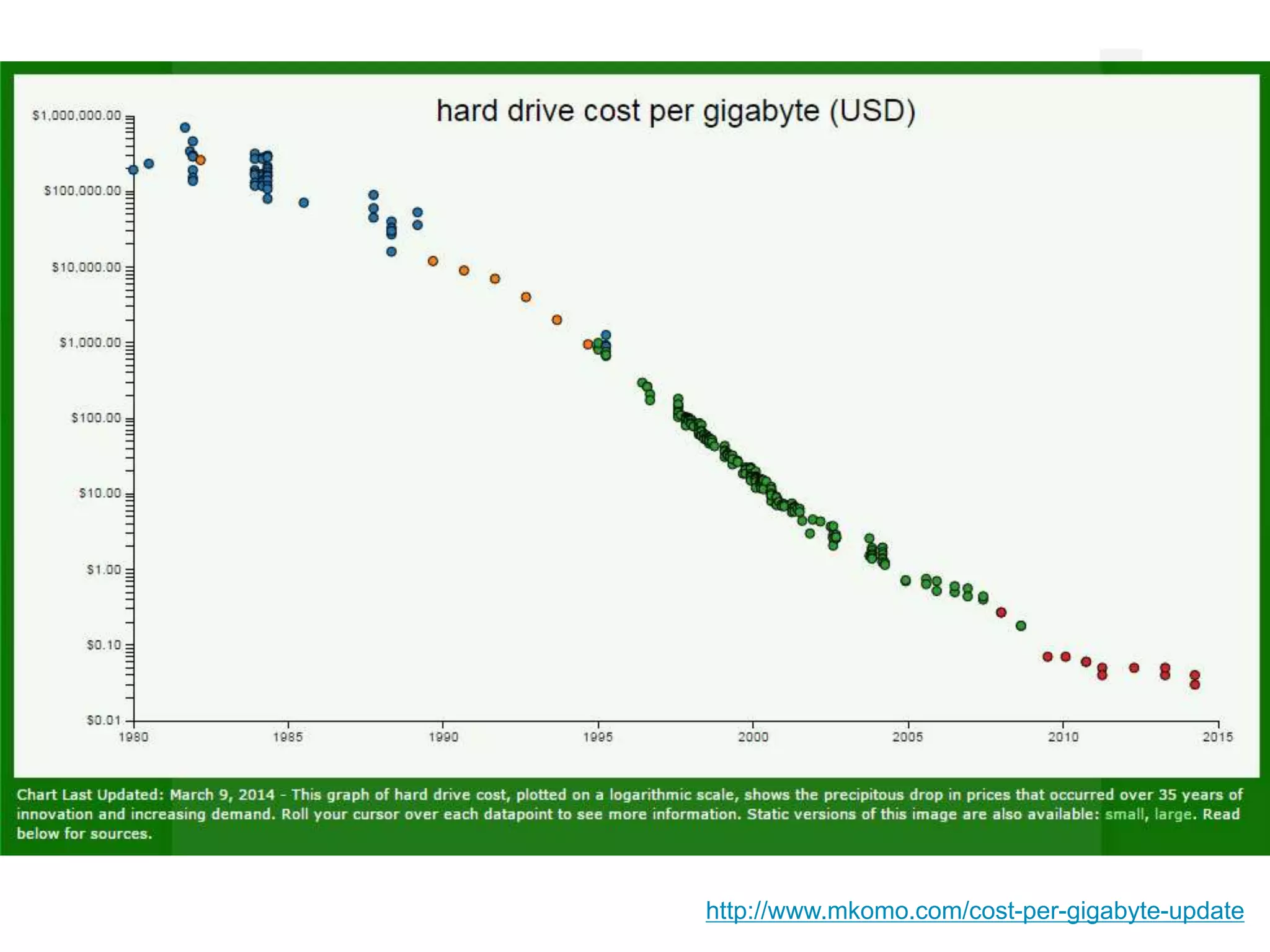








![“… communication and media
limitations, due to the distance
between Earth and Mars,
resulting in time delays: they will
have to request the movies or
news broadcasts they want to
see in advance.
[…]
Easy Internet access will be
limited to their preferred sites
that are constantly updated on
the local Mars web server.
Other websites will take
between 6 and 45 minutes to
appear on their screen - first 3-
22 minutes for your click to
reach Earth, and then another
3-22 minutes for the website
data to reach Mars.”
http://www.mars-one.com/faq/mission-to-mars/what-will-the-astronauts-do-on-mars](https://image.slidesharecdn.com/alexandria-2017-171023075258/75/Web-Archives-and-the-dream-of-the-Personal-Search-Engine-24-2048.jpg)






![Anchor Text & Timestamps
Anchor text exhibits characteristics similar to user query
and document title [Eiron & McCurley, Jin et al.]
Anchor text with timestamps can be used to capture &
trace entity evolution [Kanhabua and Nejdl]
Anchor text with timestamps lets us reconstruct (past) topic
popularity [Samar et al.]
Again, the Web Archive to the rescue!](https://image.slidesharecdn.com/alexandria-2017-171023075258/75/Web-Archives-and-the-dream-of-the-Personal-Search-Engine-31-2048.jpg)




![Trade log data!
IR-809: (2011) Feild, H., Allan, J. and Glatt, J.,
"CrowdLogging: Distributed, private, and
anonymous search logging," Proceedings of the
International Conference on Research and
Development in Information Retrieval (SIGIR'11),
pp. 375-384. [View bibtex]
We describe an approach for distributed search log collection, storage, and mining,
with the dual goals of preserving privacy and making the mined information broadly
available. [..] The approach works with any search behavior artifact that can be
extracted from a search log, including queries, query reformulations, and query-
click pairs.](https://image.slidesharecdn.com/alexandria-2017-171023075258/75/Web-Archives-and-the-dream-of-the-Personal-Search-Engine-36-2048.jpg)










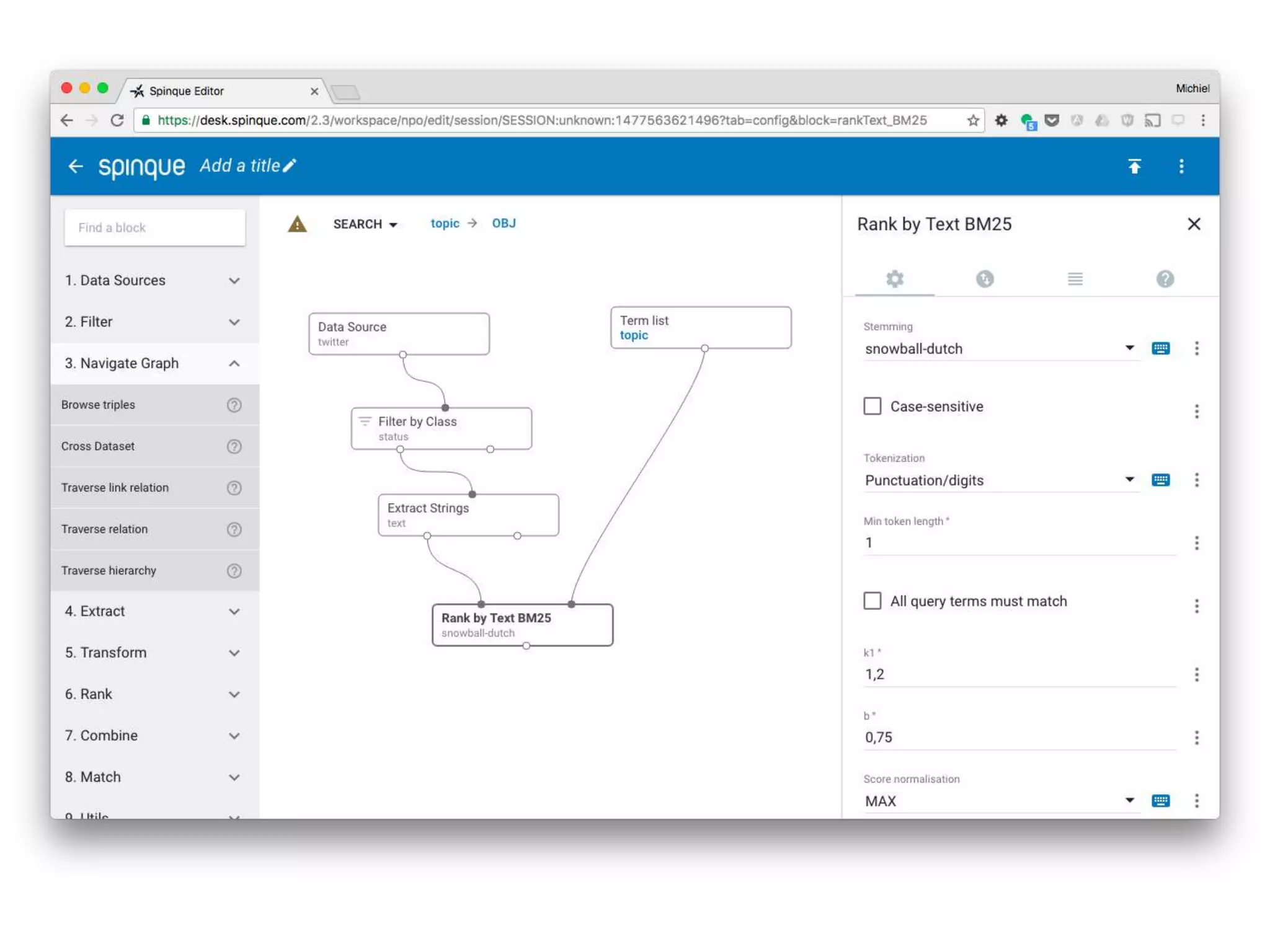



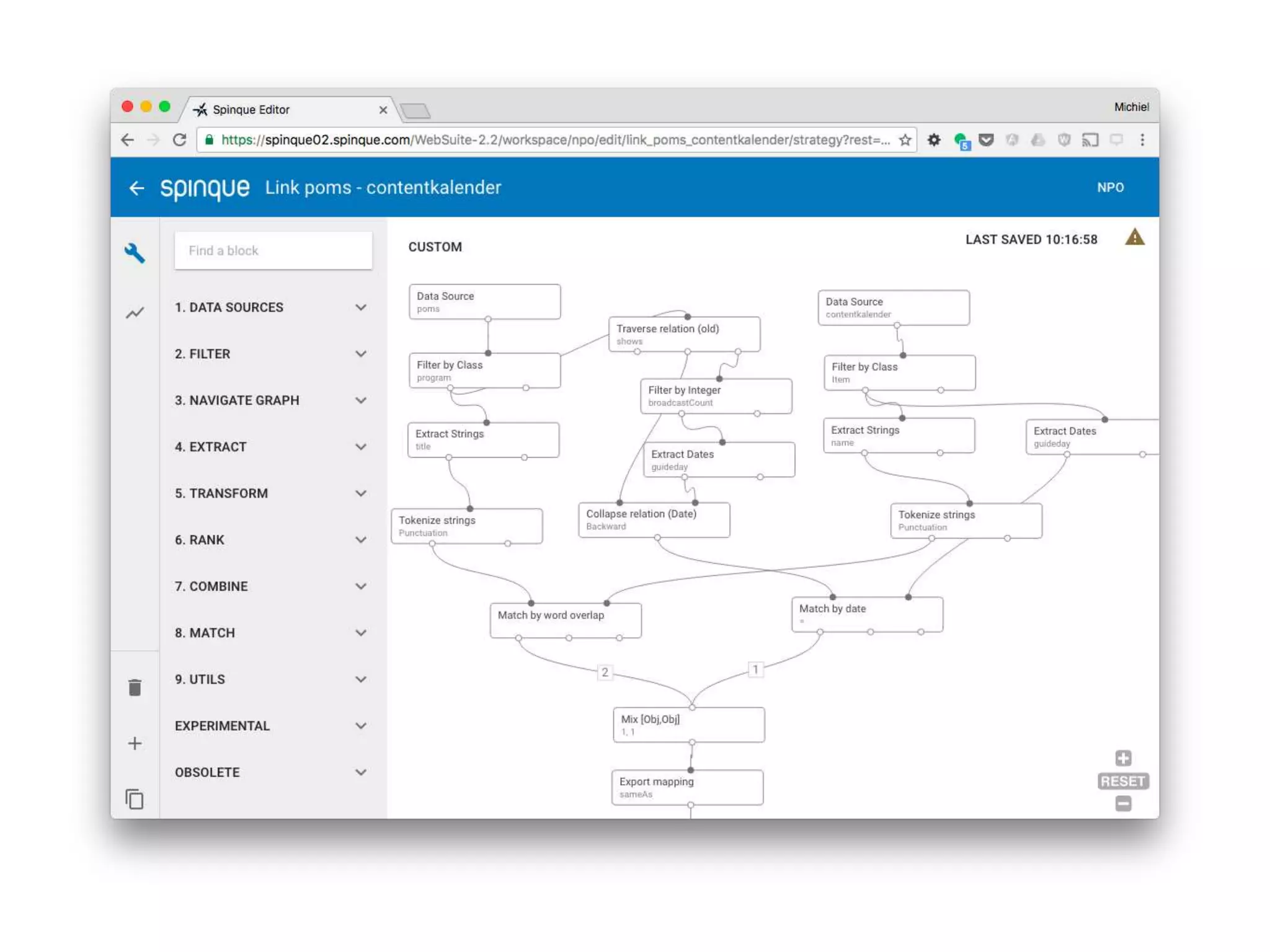
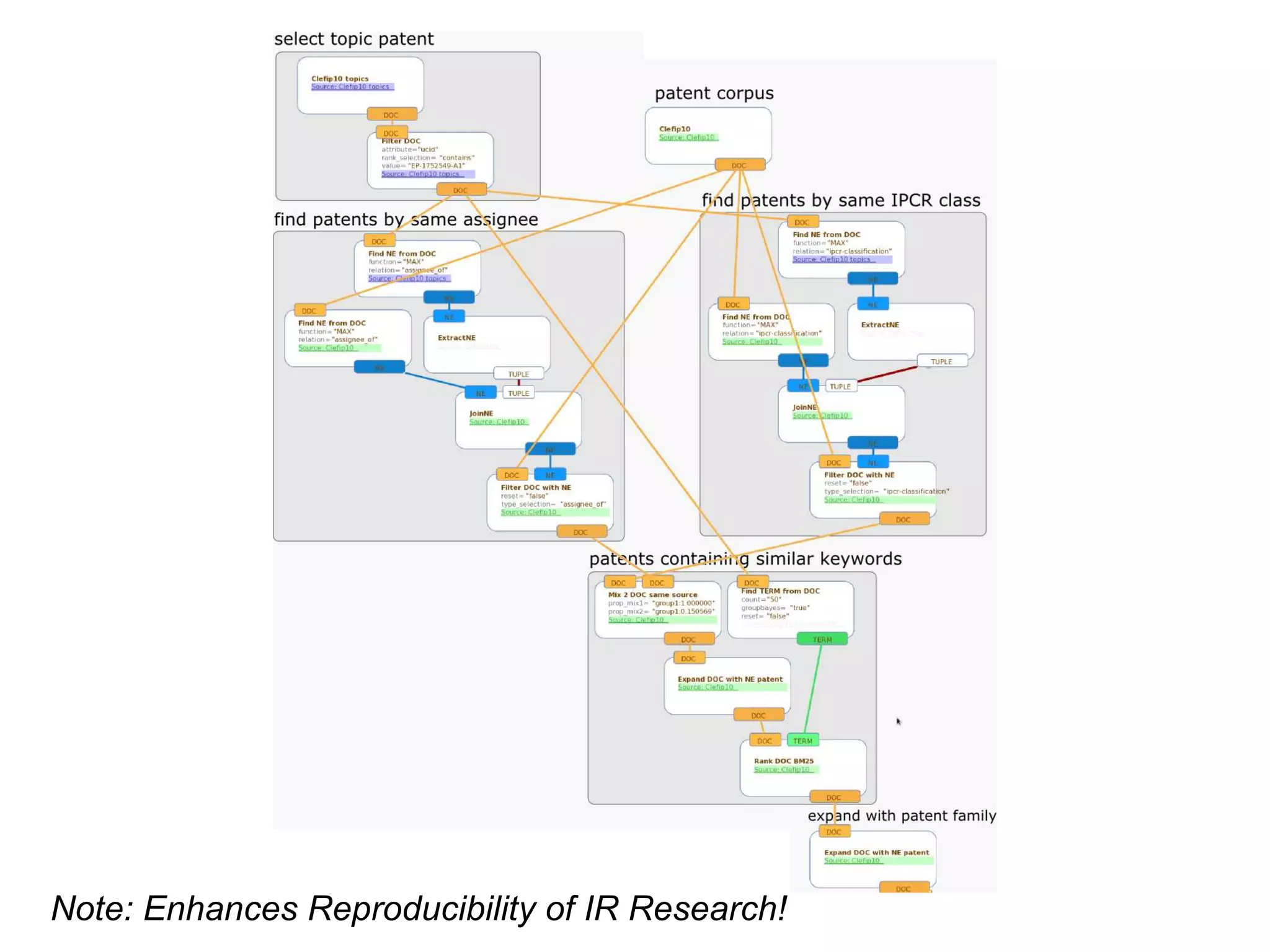




The document discusses the challenges of web search and the potential of personal search engines, emphasizing the need for decentralized data management and the utilization of web archives. It explores strategies like learning to rank for result optimization and innovative approaches to gather web data while maintaining user privacy. Ultimately, the aim is to develop a highly personalized search experience that leverages individual usage data and advances in decentralized technology.






















































































