Downloaded 412 times


![Denis Shestakov
Intelligent Web Crawling
WI-IAT’13, Atlanta, USA, 20.11.2013
1/98
References to this tutorial
To cite please use:
D. Shestakov, "Intelligent Web Crawling," IEEE Intelligent
Informatics Bulletin, 14(1), pp. 5-7, 2013.
[BibTeX]](https://image.slidesharecdn.com/intelligentcrawlingshestakovwiiat13-131211043744-phpapp02/85/Intelligent-web-crawling-2-320.jpg)



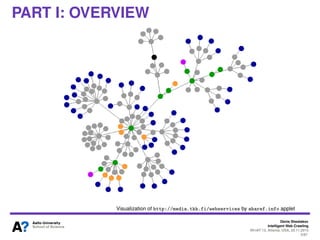


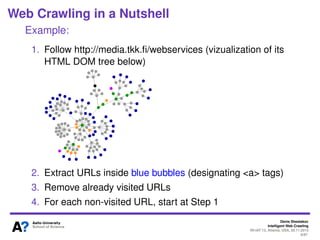




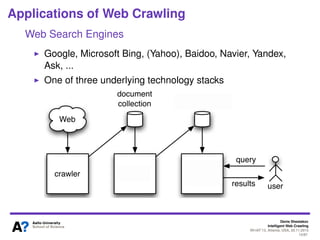
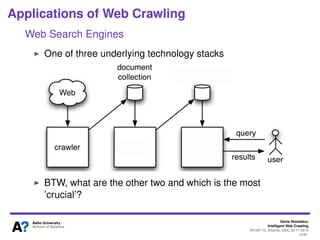
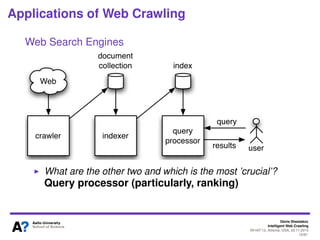













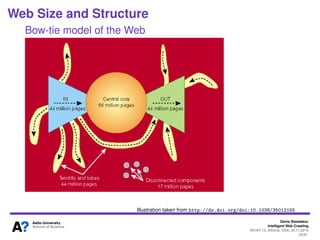
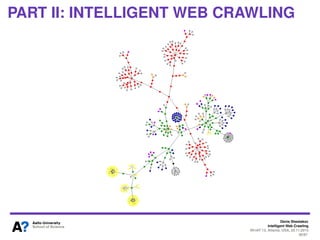

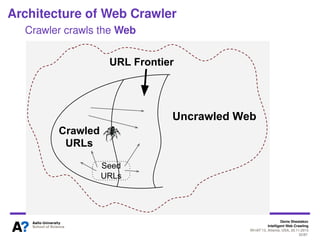
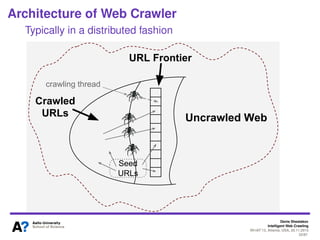

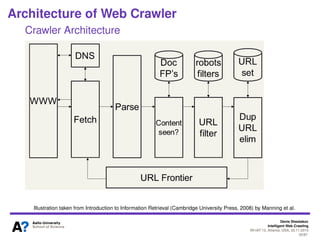


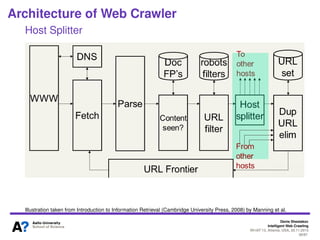



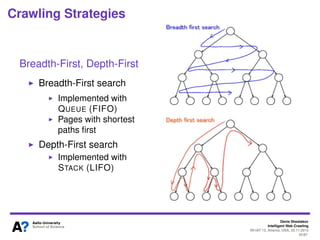









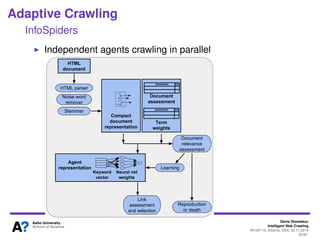






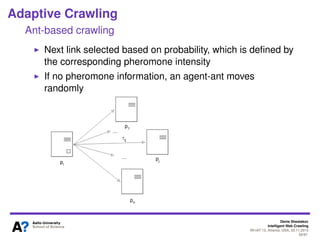
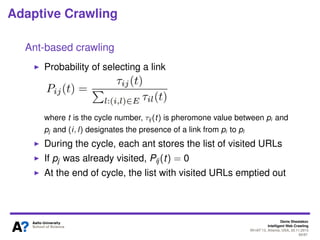

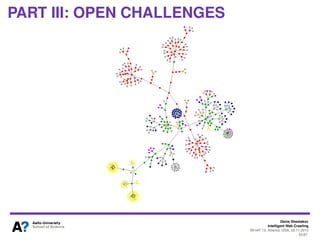









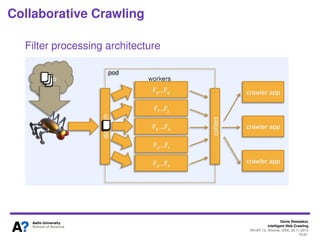
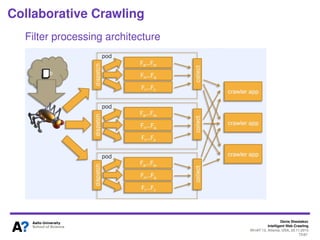

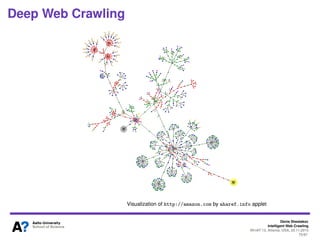
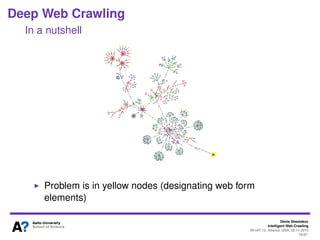























The document outlines a tutorial on intelligent web crawling presented by Denis Shestakov at WI-IAT 2013, discussing various aspects such as architecture, strategies, and applications of web crawlers. It highlights the complexity of web crawling processes, the importance of prioritization, and the distinction between academic and industrial practices. Additionally, several applications of web crawling, including web search engines, archiving, data mining, and monitoring, are presented along with challenges faced in the field.
















































































